
OpenSearch 2.10 introduced hybrid queries, which have become a popular choice for improving semantic search relevance. By combining full-text lexical search with semantic search, hybrid queries deliver better results than either method alone across various applications, including e-commerce, document search, log analytics, and data exploration. Our earlier blog post introduced this feature and presented quality and performance results.
OpenSearch continues to enhance its hybrid query capabilities with features like post-filters, aggregations, query parallelization, the explain parameter, and sorting. Building on this momentum, OpenSearch 2.19 introduced pagination support through the new pagination_depth parameter. When used with traditional from and size parameters, this enhancement helps you efficiently navigate through hybrid query result sets. For example, you can now paginate through thousands of search results one page at a time.
In this blog post, we’ll explain pagination and the pagination_depth parameter. We’ll explore why pagination depth is necessary for hybrid queries, show you how to use this feature, and share benchmarking results.
Understanding pagination
OpenSearch uses pagination to divide large result sets into manageable pages. Each page contains the number of search results specified by the size parameter in your search request. OpenSearch supports four pagination techniques:
fromandsizeparameters- Scroll search operation
search_afterparameter- Point in Time with
search_after
For more information about these techniques, see the OpenSearch documentation.
This blog post focuses on using the from and size parameters with the new pagination_depth parameter in hybrid queries.
How pagination_depth works
The pagination_depth parameter specifies the maximum number of search results to retrieve from each shard for every subquery. This gives you precise control over how many results to hybridize for each subquery.
The following figure presents an index with three shards. The example hybrid query search request includes two subqueries (a match query and a k-NN query), with pagination_depth = 20, size = 10, and from = 5.
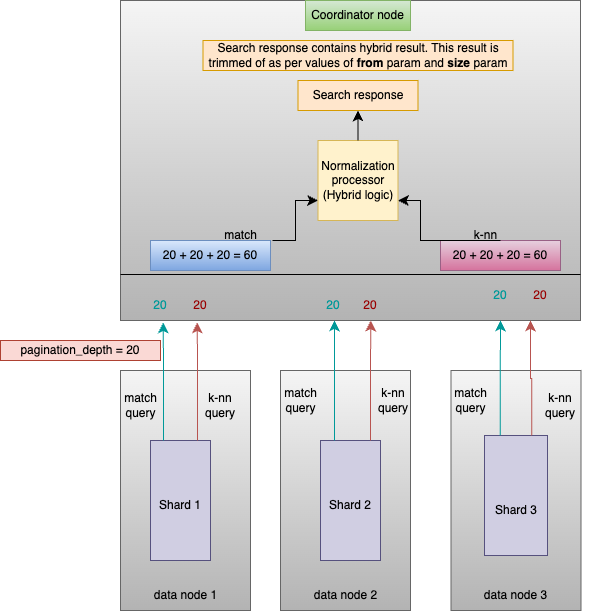
Here’s how this example works:
- With
pagination_depthset to 20, each shard retrieves up to 20 results for both the match query and the k-NN query (this example assumes that each shard contains at least 20 results per query). - The coordinator node receives 120 total results (60 for the match query and 60 for the k-NN query) and processes them using hybrid search techniques, including normalization and score combination.
- When applying hybrid search techniques, any duplicate results appearing in both subqueries are merged into a single result.
- The final results are trimmed according to the top 10 results (because of
size = 10), starting from the fifth entry (because offrom = 5).
This process ensures that hybrid search efficiently merges and ranks results from multiple subqueries while respecting pagination constraints.
Why pagination_depth matters
Traditional queries (like match and term) use a simple from + size formula to determine the maximum number of search results to retrieve from each shard. However, applying this same formula to hybrid search creates challenges that affect result accuracy, or ground truth. Ground truth refers to information gained from direct observation rather than inference; in practice, it represents the best available test or benchmark under reasonable conditions. This serves as a foundation for validating data accuracy, whether through customer feedback, human labels, or the most reliable available testing methods, even when classification may be imperfect.
Let’s look at an example. Consider a hybrid query search request with these parameters:
from = 0size = 3
The request contains two subqueries under the hybrid clause: a match query and a k-NN query. The normalization processor is configured to assign a greater weight to the match query (0.7) than the k-NN query (0.3), as shown in the following diagram.
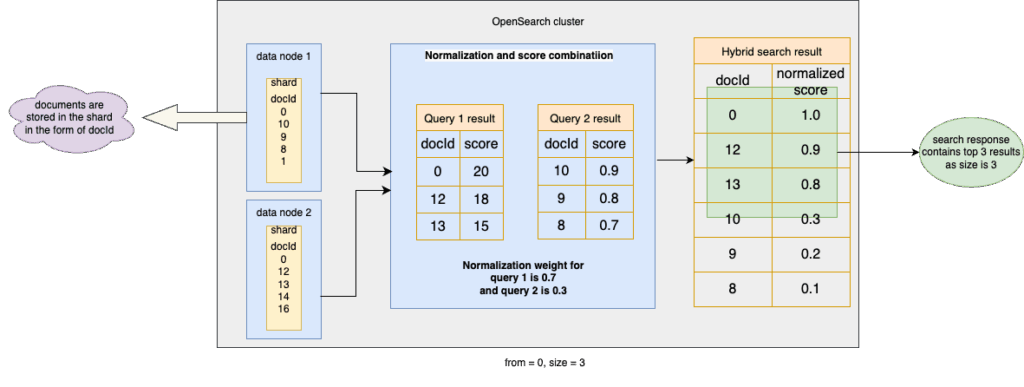
How the from + size formula affects ground truth
Modifying the from or size values increases the number of results retrieved for each subquery from a shard. However, these new results don’t simply append to the last page. They can appear earlier in the ranked list, changing the ground truth you’re trying to paginate through. This happens in the following two main scenarios:
-
Higher-weighted subquery effect:
- New results from a higher-weighted subquery may rank higher after score combination.
- As a result, these new entries may appear earlier in the final result set—either on the first few pages or somewhere in the middle—rather than at the end, disrupting the expected pagination order.
In our example, increasing
sizeto4causes an unexpected result: the new Query 1 result (document ID 14) appears as the fourth document instead of at the end because of Query 1’s higher weight during normalization, as shown in the following diagram.

2.Duplicate result effect:
- Newly retrieved results can become duplicates, meaning they exist in both subquery results.
- After the score combination process, the combined score of a duplicate entry increases, making it more relevant.
- With equal subquery weights, duplicate results rank higher than expected, appearing higher in search results.
In the following diagram, the documents with the IDs 0 and 12 are duplicate results appearing in both the match and k-NN subqueries. Because duplicate documents typically receive higher hybrid scores than unduplicated documents, they appear higher in the results, disrupting the expected pagination order.
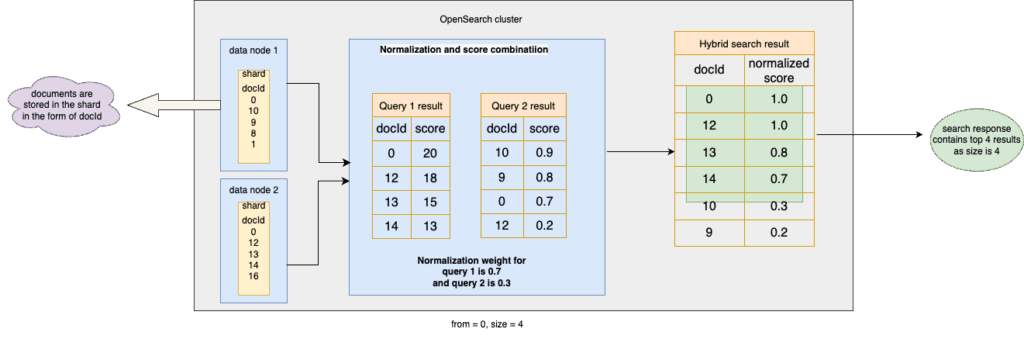
Addressing the ground truth problem
The pagination_depth parameter solves these issues by ensuring a consistent number of results per shard. This removes the dependency on from and size during result retrieval, ensuring that the same set of search results is returned every time. The from and size parameters are applied after hybrid techniques to trim the results and determine how many results should be displayed on each page.
Key takeaways
Note the following key takeaways:
- Keep
pagination_depthconstant while navigating between pages so that you maintain consistent results. - Changing
pagination_depthduring pagination will lead to inconsistent results.
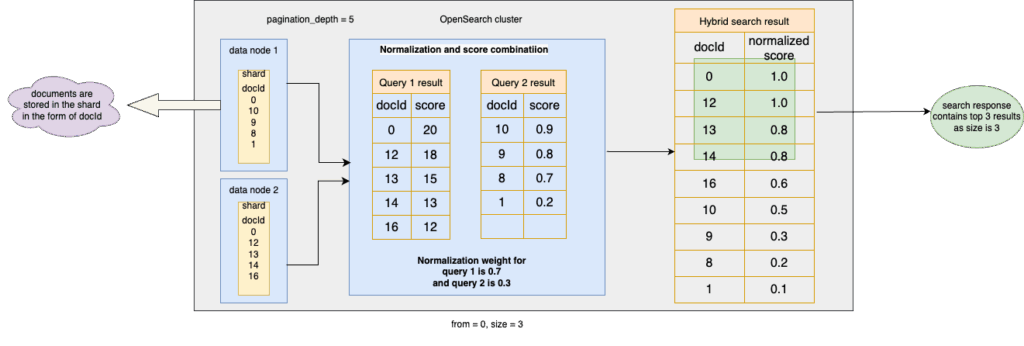
In our earlier example, setting pagination_depth = 5 addresses the ground truth issue. Both the match and k-NN queries will return up to 5 results from each shard to the coordinator node so that it can apply hybrid techniques to the subquery results. The from and size parameters then determine how to trim the hybrid search results, as shown in the following diagram.
How to use pagination with hybrid queries
To navigate between pages, specify the pagination_depth parameter in your hybrid query clause. The following example sets pagination_depth = 10, from = 0, and size = 5:
GET /my-nlp-index/_search?search_pipeline=nlp-search-pipeline
{
"from": 0,
"size": 5,
"query": {
"hybrid": {
"pagination_depth": 10,
"queries": [
{
"term": {
"category": "permission"
}
},
{
"bool": {
"should": [
{
"term": {
"category": "editor"
}
},
{
"term": {
"category": "statement"
}
}
]
}
}
]
}
}
}
For a detailed explanation of this example, see Paginating hybrid query results.
Performance impact
We conducted benchmarking to evaluate how different pagination_depth values affect CPU utilization and latency. Our tests used the noaa_semantic_search dataset from opensearch-benchmark-workloads.
Benchmarking configurations
We tested 6 configurations, all returning the second page of results (from = 100, size = 100) with varying pagination_depth values:
- 50
- 100
- 500
- 1,000
- 5,000
- 10,000
Query types tested
We evaluated two query types:
- A hybrid query that contains three subqueries: term, range, and date
- A metric aggregation applied to a hybrid query that contains three subqueries: term, range, and date
The complete query definitions are available in hybrid_search.json. Benchmarking was performed using the hybrid-query-aggs-light procedure.
Results
Our tests used an index containing 134 million documents (4 copies of the noaa_semantic_search dataset).
The following graph presents the results of running a hybrid query containing three BM25 subqueries: term, range, and date.
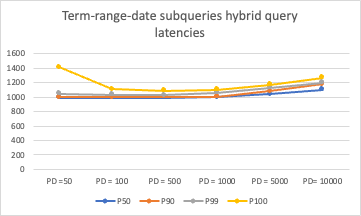
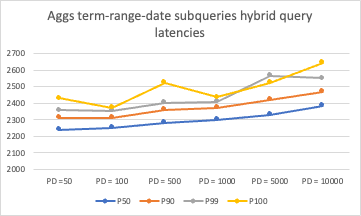
The following graph presents the results of running a metric aggregation with a hybrid query containing three BM25 subqueries: term, range, and date.
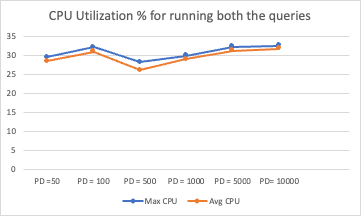
The following graph presents the CPU utilization results.
Performance summary
The results show gradual, predictable performance changes:
- There are no significant latency or CPU utilization spikes.
- Latency metrics (p50, p90, p99, p100) and CPU utilization increase steadily with increasing pagination depth.
Best practices for using pagination_depth
Our benchmarking shows no significant performance impact when fetching the second page, even with a pagination_depth of 10,000. However, both latency and CPU utilization increase with pagination depth. To optimize performance, consider the following best practices.
Optimize pagination depth based on data distribution
The efficiency of pagination depends on how evenly your data is distributed across shards. You can check this distribution using the _cat/shards API. If the documents are equally distributed among shards, then even a smaller pagination_depth can provide more hybridized search results per subquery.
For example:
- With
pagination_depth = 20across 3 shards, you can hybridize up to 60 results per subquery. - This assumes that each shard contains at least 20 results per subquery (thus, the data is evenly distributed).
- If there are no duplicate entries in the subqueries, you can paginate through up to 120 hybridized search results.
Manage uneven data distribution
Custom routing can lead to uneven data distribution across shards, resulting in some shards returning zero results, which reduces the total number of hybridized results.
Additionally, some shards may contain all the relevant results because of custom routing. Continuing the earlier example, if a shard contains more than 20 results per subquery, it can still return only 20 results (based on pagination_depth). As a result, the coordinator node will receive fewer results for hybridization, reducing the final search result size.
Summary: Recommendations
In summary, follow these recommendations to optimize hybrid search for efficiency, ensuring high relevance while maintaining performance:
- Avoid deep pagination: Hybrid search is optimized for relevance, not exhaustive pagination. For deep pagination needs, consider using traditional search methods like
boolormatchqueries. - Distribute data evenly: Balance shards during indexing to ensure better query efficiency and minimize the need for high
pagination_depthvalues.
Limitations
You may see this error while navigating between pages: “Reached end of search results. Increase pagination_depth value to see more results.”
As noted in Key takeaways, maintaining a consistent pagination_depth ensures stable results but limits you to a fixed result set. When you reach the last available page for your specified pagination_depth, OpenSearch will return an error indicating that the end of the search results has been reached. At this point, you have exhausted the search results for the given pagination_depth. To retrieve additional results beyond this limit, you must increase the pagination_depth, effectively expanding the search reference by including more results in the final result set.
Wrapping up
In this blog post, we explored how pagination_depth resolves the ground truth issues that occur when using only the from and size parameters for pagination. We also examined how pagination_depth affects performance when retrieving the top pages of the final search result. As discussed, applying pagination to retrieve a higher number of pages can degrade search performance because it increases both computation time and costs. To help you optimize performance, we’ve provided best practices for using pagination_depth with hybrid search.
Looking ahead, we’ll be adding the following features to make hybrid queries even more flexible and powerful:



