Data Prepper is an open-source data collector used to ingest data into OpenSearch clusters. In addition to Data Prepper’s in-memory buffer, which allows for fast throughput, users also want improved data durability, particularly, confirmation that the data received by Data Prepper reaches the desired sink. End-to-end acknowledgments give Data Prepper this capability.
The need: Improving data durability
The Data Prepper maintainers and their teams have observed that a common challenge to data durability is ingestion pipeline reliability. For example, if the OpenSearch cluster cannot receive data because of temporary stress on the cluster or underscaling, then Data Prepper cannot send data to the destination sink. Further, Data Prepper may exhaust memory or other system resources or the hardware running Data Prepper may fail resulting the data loss during the ingestion.
To solve these challenges, the maintainers and their teams must consider the data sources themselves. For example, the Amazon S3 source can read data from a highly durable store. When observing this, capability, it was realized that if Data Prepper fails to deliver data to OpenSearch, Data Prepper can retry reading data from Amazon S3. This, however, requires knowing when the data is written before deleting the SQS message that notifies Data Prepper of an available S3 object to consume.
Our solution: End-to-end acknowledgments
Data Prepper provides data durability through the use of end-to-end acknowledgments. When a Data Prepper source is configured to use end-to-end acknowledgments, the source is notified only when the data is successfully delivered to the sink. If the source receives end-to-end acknowledgments, it can take appropriate actions such as removing SQS messages that have been successfully delivered to the sink or incrementing the commit offset, such as in the case of a Kafka source. If end-to-end acknowledgments are not received, the source may retry the operation or notify the external source of the failure. The following image shows the control flow when a Data Prepper source is configured to use end-to-end acknowledgments.
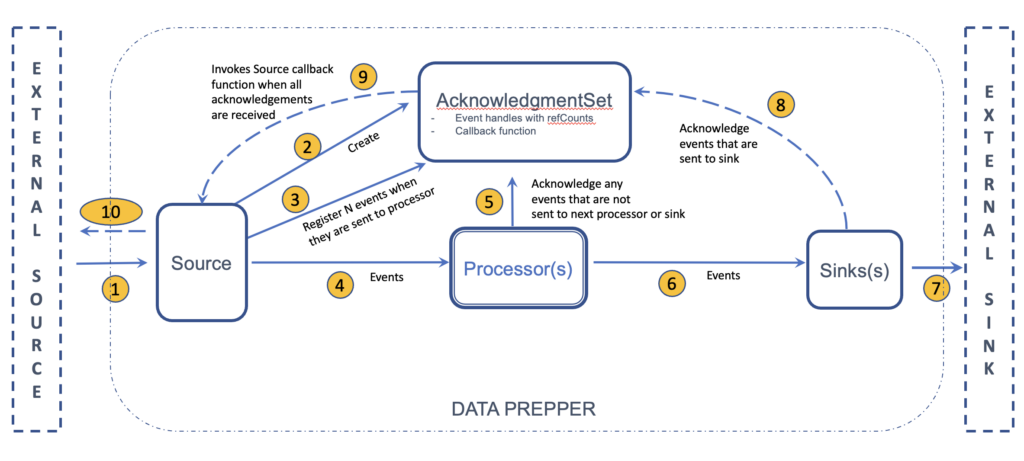
- The Data Prepper source receives a batch of records from an external source (such as Amazon S3).
- When a Data Prepper source is configured with end-to-end acknowledgments, the source creates an AcknowledgmentSet along with a callback function for each batch of records received from the external source. The source then converts the records to Data Prepper events.
- Each event in the batch is added to the AcknowledgmentSet, and a reference to the AcknowledgmentSet is kept in the event as a handle.
- Events are then passed to the ingestion pipeline, which consists of multiple processors that transform, filter, and enrich the data in the event.
- If an event is dropped in the processors, the AcknowledgmentSet is notified of the event’s completion when the event handle is released.
- All events that are not dropped are sent to the Data Prepper sink.
- The Data Prepper sink sends the events to the external sink (such as the OpenSearch cluster).
- When events are successfully sent to the external sink, the AcknowledgmentSet is notified of the event’s completion when the event handles are released.
- When the AcknowledgmentSet has no pending events, it invokes the callback function.
- The callback function notifies the external source about the successful delivery of the batch of records.
If all events are not successfully delivered to the external sinks, AcknowledgmentSet will retain some events that have not been released. Each AcknowledgmentSet has an expiry time. If all events are not released before the expiry time, the AcknowledgmentSet is freed, and the external source is not notified of the delivery of the records. This situation may trigger the Data Prepper source or the external source to take corrective action, such as retrying the ingestion of the records.
Data Prepper supports multiple pipelines and events can be routed to different pipelines based on the configuration and the data within the events. Additionally, each event may be routed to multiple pipelines that eventually send data to different sinks. In some cases, multiple copies of the same event are not created when the event is routed to multiple pipelines or sinks. This poses a challenge when tracking acknowledgments because multiple acknowledgments are required for the same event. To address this issue, reference counts are maintained for events that are routed to multiple pipelines. When an event handle is released (either in step 5 or step 8), the reference count is decremented. The event is considered completed, and the handle is removed from the AcknowledgmentSet only when the reference count reaches zero, indicating the successful delivery of the event to all sinks. This approach ensures accurate tracking of acknowledgments for events routed to multiple pipelines.
Data Prepper also provides support for sending negative acknowledgments to indicate explicit failure. The callback function can examine the acknowledgment status, whether it is positive or negative, and take appropriate action based on that information.
In certain scenarios, when Data Prepper sinks are configured with a Dead Letter Queue (DLQ), events that cannot be delivered to the external sink (for example OpenSearch) are written to the DLQ. When end-to-end acknowledgments are enabled, successfully writing the events to the DLQ (after failing to deliver them to the external sink) is considered a successful completion of event delivery. In this case, a positive acknowledgment is delivered to the AcknowledgmentSet, indicating successful event processing and handling.
Moving forward: Conclusion and next steps
End-to-end acknowledgments offer robust data durability when using Data Prepper for data processing and ingestion. Some considerations, however, are necessary:
- End-to-end acknowledgments currently are not compatible with stateful aggregations. The Data Prepper maintainers are considering this issue and exploring solutions for release in future iterations.
- To leverage end-to-end acknowledgments, source plugins must integrate with the acknowledgment system. Currently, the Amazon S3 source is the only source plugin with this functionality. However, the capability is designed to expand to include additional sources and is well-suited for pull-based sources. Ongoing development of a new Kafka source is showing to be a promising candidate for using these acknowledgments. Users also have expressed interest in applying these acknowledgments to push-based sources like HTTP, which is an area maintainers are exploring.
If you have data stored in Amazon S3 and would like to ingest it into OpenSearch, try out the Data Prepper end-to-end acknowledgments feature. As always, the Data Prepper community appreciates your feedback and contributions.
See End-to-end Acknowledgments for more details about the feature, how to enable it for a source, and what changes needed in a sink to send acknowledgments.
Share your feedback and comments on the feature’s overall goals, user experience, and architecture.

