
This post was imported from the Open Distro For Elasticsearch blog, a predecessor project of OpenSearch. Information reflected in this post may not be current or accurate.
Blog refreshed for technical accuracy on 06 Jan 2023
Since the OpenSearch Project introduced the k-nearest neighbor (k-NN) plugin in 2019, it has supported both exact and approximate k-NN search. The approximate k-NN (ANN) search method is more efficient for large datasets with high dimensionality because it reduces the cardinality of searchable vectors. This approach is superior in speed at the cost of a slight reduction in accuracy. Currently, OpenSearch supports three similarity search libraries that implement ANN algorithms: Non-Metric Space Library (NMSLIB), Facebook AI Similarity Search (Faiss), and Lucene. This post describes k-NN search and its underlying Hierarchical Navigable Small World (HNSW) algorithm, and then focuses on the integration of NMSLIB with OpenSearch and the customizations made to support the feature in OpenSearch.
What is k-NN?
A k-NN algorithm is a technique for performing similarity search: given a query data point, what are the k data points in an index that are most similar to the query? k-NN is largely popular for its use in content-based recommendation systems. For example, in a music streaming service, when a user generates an on-demand playlist, the recommendation system adds the songs that match the attributes of that playlist using k-NN. In a k-NN search algorithm, the elements of a data set are represented by vectors. Each song is a vector, containing several dimensions (attributes) like artist, album, genre, year of release, etc. The search assumes you have a defined distance function between the data elements (vectors) and returns most similar items to the one provided as input, where closer distance translates to greater item similarity. Other use cases with similarity search include fraud detection, image recognition, and semantic document retrieval.
To choose a k-NN algorithm for ANN search, we evaluated four primary dimensions to measure the algorithm’s effectiveness:
- Speed – How quickly does the algorithm return the approximate k-nearest neighbors, measured in latency of a single or batch query?
- Recall – How accurate are the results, measured by ratio of the returned k-nearest neighbors indeed in the list of the actual k nearest neighbors to the value of k?
- Scalability – Can the algorithm handle data sets with millions or billions of vectors and thousands of dimensions?
- Updates – Does the algorithm allow addition, deletion, and updating points without having to rebuild an index, a process that can take hours or more?
We selected HNSW graphs because it aligned with our architectural requirements and met most of our evaluation criteria. Given a dataset, the algorithm constructs a graph on the data such that the greedy search algorithm finds the approximate nearest neighbor to a query in logarithmic time. HNSW consistently outperforms other libraries in this space based on ANN benchmark metrics. HNSW excels at speed, recall, and cost, though it is restricted in scalability and updates. While the HNSW algorithm allows incremental addition of points, it forbids deletion and modification of indexed points. We offset the scalability and updates challenges by leveraging the OpenSearch distributed architecture, which scales with large data sets and inherently supports incremental updates to the data sets that become available in the search results in near real-time.
Hierarchical Navigable Small World Algorithm
The Hierarchical Navigable Small World (HNSW) graph algorithm is a fast and accurate solution to the approximate k-nearest neighbors (k-NN) search problem.
A straightforward, yet naive solution to the k-NN problem is to first compute the distances from a given query point to every data point within an index and then select the data points with the smallest k distances to the query. While this approach is effective when the index contains 10,000 or fewer data points, it does not scale to the sizes of datasets used by our customers. An approximate k-NN (ANN) algorithm may greatly reduce search latency at the cost of precision. When designing an ANN algorithm, there are two general approaches to improve latency:
- Compute fewer distances
- Make distance computations cheaper
The HNSW algorithm uses the first approach by building a graph data structure on the constituent points of the data set.
With a graph data structure on the data set, approximate nearest neighbors can be found using graph traversal methods. Given a query point, we find its nearest neighbors by starting at a random point in the graph and computing its distance to the query point. From this entry point, we explore the graph, computing the distance to the query of each newly visited data point until the traversal can find no closer data points. To compute fewer distances while still retaining high accuracy, the HNSW algorithm builds on top of previous work on Navigable Small World (NSW) graphs. The NSW algorithm builds a graph with two key properties. The “small world” property means that the number of edges in the shortest path between any pair of points grows poly-logarithmically with the number of points in the graph. The “navigable” property asserts that the greedy algorithm is likely to stay on this shortest path. Combining these two properties results in a graph structure that allows the greedy algorithm to find the data point nearest to a query in logarithmic time.
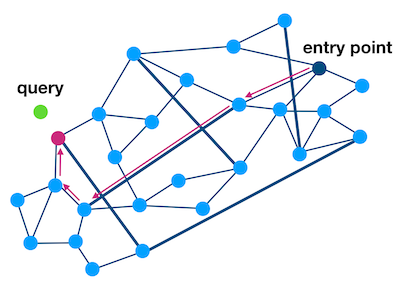
Figure 1: A depiction of an NSW graph built on blue data points. The dark blue edges represent long-range connections that help ensure the small-world property. Starting at the entry point, at each iteration the greedy algorithm will move to the neighbor closest to the query point. The chosen path from the entry point to the query’s nearest neighbor is highlighted in magenta and, by the “navigable” property, is likely to be the shortest path from the entry point to the query’s nearest neighbor.
HNSW extends the NSW algorithm by building multiple layers of interconnected NSW-like graphs. The top layer is a coarse graph built on a small subset of the data points in the index. Each lower layer incorporates more points in its graph until reaching the bottom layer, which consists of an NSW-like graph on every data point. To find the approximate nearest neighbors to a query, the search process finds the nearest neighbors in the graph at the top layer and uses these points as the entry points to the subsequent layer. This strategy results in a nearest neighbors search algorithm which runs logarithmically with respect to the number of data points in the index.
Non-Metric Space Library
NMSLIB, an Apache 2 licensed library, is the open source implementation of HNSW. It is lightweight and works particularly well for our use cases that that requires minimal impact on the OpenSearch application workloads. To index the vectors and to query the nearest neighbors for the given query vector, our k-NN plugin makes calls to the NMSLIB implementation of HNSW. We use the Java Native Interface (JNI) as a bridge between OpenSearch, which is written in Java, and NMSLIB libraries, which are written in C++. OpenSearch now supports several distance functions, such as Euclidean, cosine similarity, and inner product, for calculating similarity scores. For a list of all supported distance functions, see Spaces.
OpenSearch Integration with ANN
The OpenSearch distributed engine allows us to distribute the millions of vectors across multiple shards spread across multiple nodes within a cluster and scales horizontally as the data grows. Users can also take advantage of OpenSearch’s support for index updates to make any modifications to the dataset and reflect the changes in the results in near real-time. While OpenSearch’s plugin-based architecture makes it easy to add extensions, we had to make some customizations to support the ANN Search.
First, we added a new field type, knn_vector, using the Mapper plugin, to represent the vectors as arrays of floating point numbers in a document. ANN requires support for storing high cardinality vectors. The knn_vector field supports vectors up to 16,000 dimensions. We also introduced a new Apache Lucene codec, KNNCodec, to add a new index file format for storing and retrieving the vectors and make Apache Lucene aware of the graphs built by NMSLIB. These file formats co-exist with the other Apache Lucene file formats and are immutable just like the other Apache Lucene files, making them file system cache friendly and thread safe.
Let’s create a KNN index myindex and add data of type knn_vector to the field my_vector:
PUT /myindex
{
"settings": {
"index.knn": true
},
"mappings": {
"properties": {
"my_vector": {
"type": "knn_vector",
"dimension": 4,
"method": {
"name": "hnsw",
"space_type": "l2",
"engine": "nmslib",
"parameters": {
"ef_construction": 128,
"m": 24
}
}
}
}
}
}
For a description of more advanced settings, see knn_vector data type documentation.
You can then index your documents as you would normally do using any of OpenSearch index APIs:
PUT /myindex/_doc/1
{
"my_vector": [1.5, 2.5]
}
PUT/myindex/_doc/2
{
"my_vector": [2.5, 3.5]
}
We also added a new knn query clause. You can use the this clause in a query and specify the point of interest as my_vector (knn_vector) and the number of nearest neighbors to fetch as k. The following response shows two nearest documents to the input point [3, 4]. The score indicates the distance between the two vectors, which is the deciding factor for selecting the neighbors:
POST /myindex/_search
{
"size": 2,
"query": {
"knn": {
"my_vector": {
"vector": [3, 4],
"k": 2
}
}
}
}
The response contains the matching documents:
{
"took": 7,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.5857864,
"hits": [{
"_index": "myindex",
"_type": "_doc",
"_id": "2",
"_score": 0.5857864,
"_source": {
"my_vector": [
2.5,
3.5
]
}
},
{
"_index": "myindex",
"_type": "_doc",
"_id": "1",
"_score": 0.32037726,
"_source": {
"my_vector": [
1.5,
2.5
]
}
}
]
}
}
You can also combine the knn query clause with other query clauses as you would normally do with compound queries. In the following example, the user first runs the knn query to find the closest five neighbors (k=5) to the vector [3,4] and then applies post filter to the results using the boolean query to focus on items that are priced less than 15 units:
POST /myindex/_search
{
"size": 5,
"query": {
"bool": {
"must": {
"knn": {
"my_vector": {
"vector": [3, 4],
"k": 5
}
}
},
"filter": {
"range": {
"price": {
"lt": 15
}
}
}
}
}
}
Memory Monitoring
The NSW graphs, created by the underlying NMSLIB C++ library, are loaded outside the OpenSearch JVM, and the garbage collection does not reclaim the memory used by the graphs. We developed a monitoring solution using Guava cache to limit memory consumption by the graphs to prevent OOM (out of memory) issues and to trigger garbage collection when the indices are deleted or when the existing segments are merged to newer segments as part of segment merges. We also introduced an additional stats API to monitor the cache metrics like totalLoadTime, evictionCount, hitCount, and graphMemoryUsage to assist with efficient memory management. For the complete set of metrics, refer to k-NN settings.
Conclusion
Our k-NN solution enables you to build a scalable, distributed, and reliable framework for similarity searches. You can further enhance the results with strong analytics and query support from OpenSearch. For more details on k-NN search, check out the k-NN documentation. If you are interested in contributing, be sure to access the k-NN plugin repo.


