

OpenSearch 3.0 marks a major milestone in the project’s ongoing performance journey and the first major release since 2.0 in April 2022. Building on the enhancements of the 2.x series, the 3.0 release integrates Apache Lucene 10 and upgrades the Java runtime to JDK 21, bringing significant improvements to search throughput, indexing and query latency, and vector processing. With a 10x search performance boost and 2.5x vector search performance boost, Lucene 10 continues to be our strategic search library, and its latest version delivers measurable gains over earlier releases (baselined against 1.x) through enhanced query execution, skip-based filtering, and segment-level concurrency.
This post provides a detailed update on OpenSearch 3.0’s performance, focusing on search queries, indexing throughput, artificial intelligence and machine learning (AI/ML) use cases, and vector search workloads. We’ll highlight measurable impacts, as observed in our benchmarks, and explain how new Lucene 10 features, such as concurrent segment search, query optimizations, doc-value skip lists, and prefetch APIs, contribute to future OpenSearch roadmaps. All results are supported by benchmark data, in keeping with our focus on community transparency and real-world impact.
Query performance improvements in OpenSearch 3.0
OpenSearch 3.0 continues the steady performance gains achieved throughout the 2.x line, as shown in the following graph. Compared to OpenSearch 1.3, query latency in OpenSearch 3.0 has been reduced by about 90% (geometric mean across key query types), meaning queries are on average over 10x faster than in 1.3. Even compared to more recent 2.x versions, 3.0’s query operations are about 24% faster than 2.19 (the last 2.x release) on the OpenSearch Big5 workload.
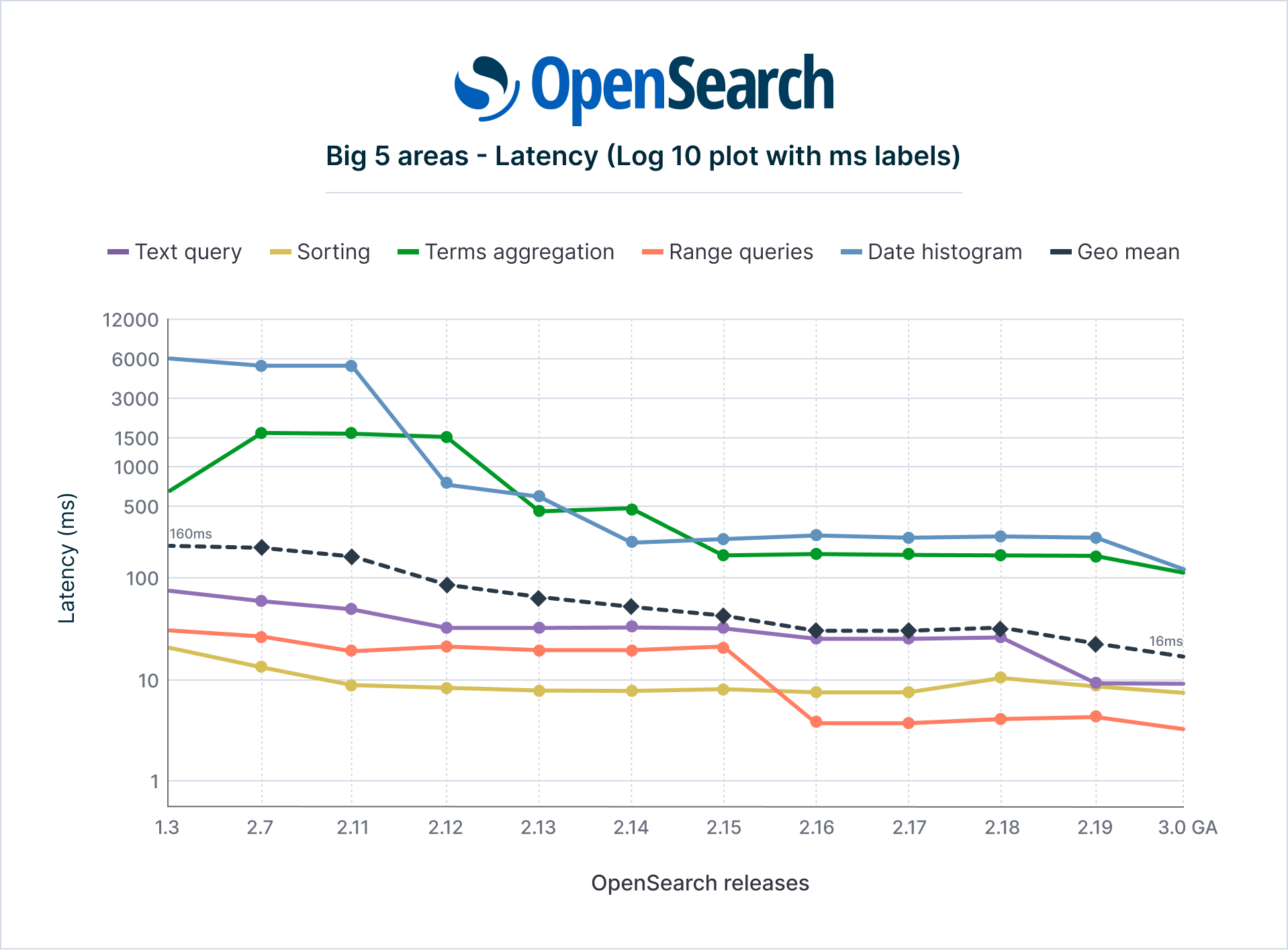
The following table summarizes latency benchmarks across versions 1.3.18, 2.x, and 3.0.
| Big 5 areas mean latency, ms | Query type | 1.3.18 | 2.7 | 2.11 | 2.12 | 2.13 | 2.14 | 2.15 | 2.16 | 2.17 | 2.18 | 2.19 | 3.0 GA |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Text queries | 59.51 | 47.91 | 41.05 | 27.29 | 27.61 | 27.85 | 27.39 | 21.7 | 21.77 | 22.31 | 8.22 | 8.3 | |
| Sorting | 17.73 | 11.24 | 8.14 | 7.99 | 7.53 | 7.47 | 7.78 | 7.22 | 7.26 | 9.98 | 7.96 | 7.03 | |
| Terms aggregations | 609.43 | 1351 | 1316 | 1228 | 291 | 293 | 113 | 112 | 113 | 111.74 | 112.08 | 79.72 | |
| Range queries | 26.08 | 23.12 | 16.91 | 18.71 | 17.33 | 17.39 | 18.51 | 3.17 | 3.17 | 3.55 | 3.67 | 2.68 | |
| Date histograms | 6068 | 5249 | 5168 | 469 | 357 | 146 | 157 | 164 | 160 | 163.58 | 159.57 | 85.21 | |
| Aggregate (geo mean) | 159.04 | 154.59 | 130.9 | 74.85 | 51.84 | 43.44 | 37.07 | 24.66 | 24.63 | 27.04 | 21.21 | 16.04 | |
| Speedup factor, compared to OS 1.3 (geo mean) | N/A | 1.03 | 1.21 | 2.12 | 3.07 | 3.66 | 4.29 | 6.45 | 6.46 | 5.88 | 7.50 | 9.92 | |
| Relative latency, compared to OS 1.3 (geo mean) | N/A | 97.20 | 82.31 | 47.06 | 32.60 | 27.31 | 23.31 | 15.51 | 15.49 | 17.00 | 13.34 | 10.09 | |
Row 7 shows Big5 benchmark mean latency (ms) by OpenSearch version. Lower is better. Rows 8 and 9 show speedup factor and latency relative to the 1.3 baseline.
The OpenSearch 3.0 release brings search performance gains in two main areas:
- Out-of-the-box improvements in Lucene 10: Lucene 10 introduces hardware-level enhancements such as SIMD-accelerated vector scoring and more efficient postings decoding, which immediately benefit query performance and require no configuration changes. For example, minute-level date histogram aggregations run up to 60% faster,
search_afterqueries improve by 20–24%, and scroll queries show modest latency reductions because of low-level enhancements in both Lucene 10 and JDK 21. - OpenSearch-specific engine optimizations: Since our previous update, the OpenSearch community implemented multiple targeted optimizations in versions 2.18, 2.19, and 3.0. These include cost-based query planning, optimized handling for high-frequency terms queries, restoration of a time-series sort optimization lost with the Lucene 10 upgrade, aggregation engine improvements, request cache concurrency enhancements, and resolution of Lucene-induced regressions (for example, sort and merge slowdowns). Additionally, OpenSearch 3.0 introduces auto-enabled concurrent segment search, which selectively parallelizes expensive queries, delivering double-digit latency reductions on operations like
date_histogramandtermsaggregations.
Key performance highlights
The following sections describe key performance highlights in OpenSearch 3.0.
Lucene 10 improvements
The Lucene 10 upgrade introduced out-of-the-box speedups using SIMD vectorization and improved input/output patterns. OpenSearch 3.0 inherits these benefits, with complex query-string searches showing ~24% lower p50 latency compared to 2.19 (issue #17385). Other operations, like high-cardinality aggregations, improved by ~10–20% solely because of the engine change. Additionally, OpenSearch addressed several regressions caused by the Lucene 10 transition, including performance drops in composite_terms operations on keyword fields (#17387, #17388). With these fixes, keyword-heavy filters and aggregations in OpenSearch 3.0 now perform as well as, or better than, their counterparts in the 2.x series.
Query operation improvements (compared to OpenSearch 1.3.18 and 2.17)
To further accelerate query execution, OpenSearch introduced targeted optimizations across core operations:
- Text queries: The median latency for full-text queries is ~8 ms in 3.0 compared to ~60 ms in 1.3 (~87% faster). In 2.19, most gains were achieved through cost-based filter planning and early clause elimination. Further, Boolean scorer improvements helped reduce tail latencies in 3.0. Compared to 2.17 (~21.7 ms), this is a ~3x speedup (#17385).
- Terms aggregations: Latency dropped from ~609 ms in 1.3 to ~80 ms in 3.0 (~85% faster; ~30% compared to 2.17). Improvements include optimized global ordinals, smarter doc values access, and execution hints for controlling cardinality aggregation memory usage (#17657). Approximate filtering for range constraints also reduced scan costs in observability use cases.
- Sort queries: Sorted queries are ~60% faster than in 1.3 and ~5–10% faster than in 2.17. OpenSearch 3.0 restored Lucene’s time-series sort optimization by correctly invoking the new
searchAfterPartition()API (PR #17329) and resolving regressions indesc_sort_timestampqueries (#17404). - Date histograms: Latency fell from ~6s in 1.3 to ~146 ms in 3.0, with lows of ~85 ms using concurrency (up to 60x faster). Gains come from block skipping, segment-level parallelism, and sub-agg optimizations (for example, pushing filters inside range-auto-date aggs). 3.0 is up to ~50% faster than 2.19 in this category.
- Range queries: Range filters now run in ~2.75 ms, down from ~26 ms in 1.3 (~89% faster) and ~25% faster than 2.19. OpenSearch’s range approximation framework became generally available in 3.0, delivering gains through more efficient use of doc values and by skipping over non-matching blocks, further lowering scan costs.
Star-tree index for log analytics
Introduced in 2.19, the star-tree aggregator enables pre-aggregated metric and filtered terms queries. In eligible use cases, this reduces query compute by up to 100x and cache usage by ~30x. 3.0 extends support to multi-level and numeric terms aggregations (with sorted bucket elimination), achieving ~15–20% lower latency over 2.19 in benchmarks.
Concurrent segment search (auto mode)
OpenSearch 3.0 defaults to concurrent segment search in the auto mode, allowing the engine to choose between sequential and parallel segment execution per query. Expensive aggregations (for example, terms or date_histogram) run in parallel, while lightweight queries stay single-threaded to avoid overhead. On an 8-vCPU cluster, this yielded ~35% lower latency on date histograms, 15%+ on terms aggregations, and showed an ~8% aggregate gain across the Big5. Text queries stayed flat (for example, 8.22 ms sequential compared to 8.93 ms auto), confirming that the selector works as intended without regression.
AI/ML and vector search performance improvements
OpenSearch 3.0 builds on the vector engine enhancements introduced in the 2.x series, continuing to improve performance, memory efficiency, and configurability for both exact k-NN and approximate k-NN (ANN) search. These capabilities are critical for workloads running semantic search and generative AI.
GPU acceleration for vector index builds
The introduction of GPU acceleration for vector indexing in OpenSearch represents a major advancement in supporting large-scale AI workloads. Benchmarks showed that GPU acceleration improved indexing speed by 9.3x and reduced costs by 3.75x compared to CPU-based solutions. This dramatically reduces the time required for billion-scale index builds from days to just hours. The decoupled design, which separates the GPU-powered index build service from the main OpenSearch cluster, provides flexibility to evolve the components independently and enables seamless adoption across cloud and on-premises environments. By using the CAGRA algorithm from NVIDIA’s cuVS library and supporting GPU-CPU index interoperability, OpenSearch delivers a robust, scalable vector search solution with built-in fault tolerance and fallback mechanisms for production reliability. For more information, see this blog post and the RFC.
Derived source (3x storage reduction)
In OpenSearch 3.0, derived source for vectors is enabled by default for all vector indexes. By removing the redundant storage of the _source field, using derived source for vectors results in a 3x reduction in storage across all engines tested (Faiss, Lucene, and NMSLIB), as shown in the following graph.
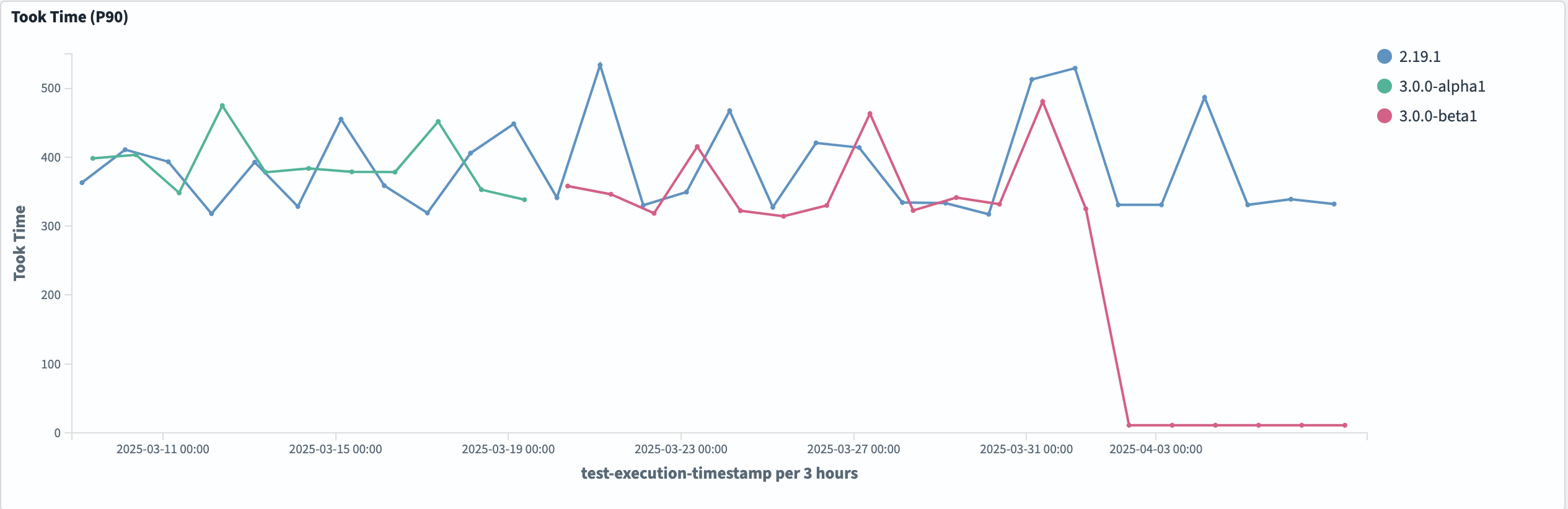
This storage optimization also has a significant impact on performance, with a 30x improvement in p90 cold start query latencies for the Lucene engine, as shown in the following graph.
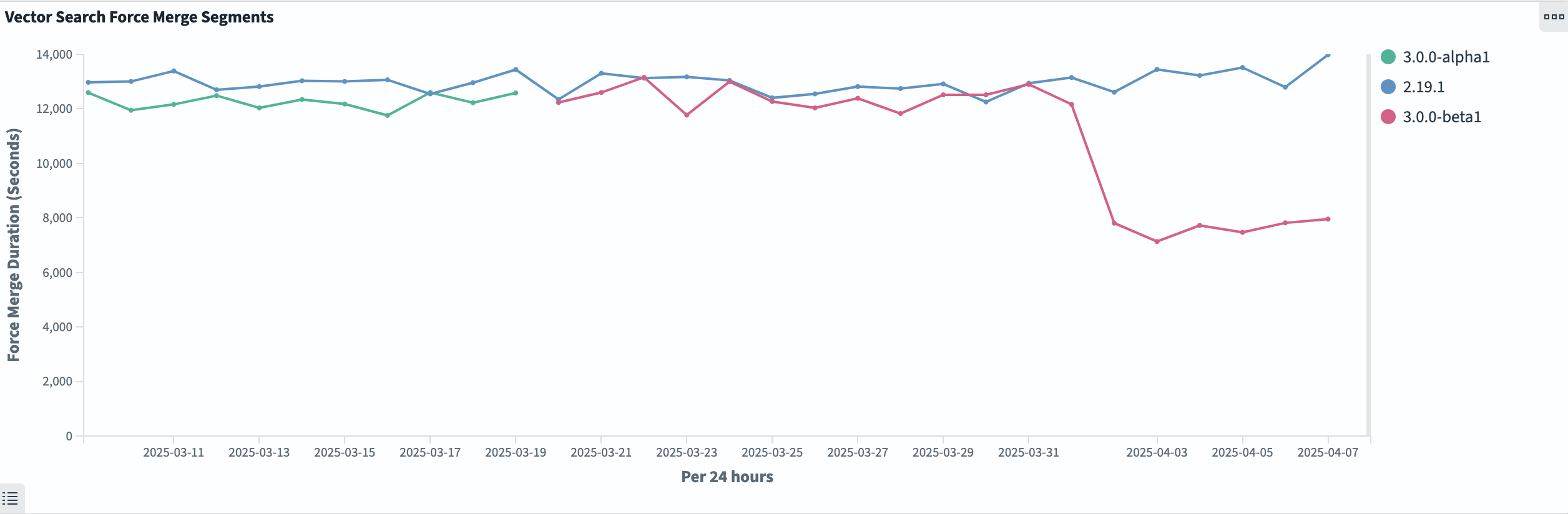
This feature also saw strong improvements in merge time reduction: up to 40% across all engines, as shown in the following graph.
These substantial gains in both storage efficiency and query performance demonstrate the value of using derived source for vectors when operating OpenSearch as a high-scale vector search engine. The transparent nature of this feature, which preserves critical functionality like reindexing and field-based updates, makes it available to a wide range of users looking to optimize their vector search workloads in OpenSearch. For more information, see the RFC.
For benchmarking tests, see the nightly benchmarks. Benchmarks are run against a 10M/768D dataset.
Vector search performance boost of up to 2.5x
Concurrent segment search is now enabled by default for all vector search use cases. Concurrent segment search boosts vector query performance by up to 2.5x with no impact on recall through parallelizing search queries across multiple threads. Additionally, changes to the floor segment size setting in the merge policy create more balanced segments and improve tail latencies by up to 20%. This performance boost is applicable to both in-memory and disk-optimized indexes.
Service time comparison
The following table compares 90th percentile (p90) service times, in milliseconds, across different k-NN engines with various concurrent segment search configurations.
| k-NN engine | Concurrent segment search disabled | Concurrent segment search enabled (Lucene default number of slices) | % Improvement | Concurrent segment search with max_slice_count = 2 |
% Improvement | Concurrent segment search with max_slice_count = 4 |
% Improvement | Concurrent segment search with max_slice_count = 8 |
% Improvement |
|---|---|---|---|---|---|---|---|---|---|
| Lucene | 37 | 15 | 59.5 | 16 | 56.8 | 15.9 | 57 | 16 | 56.8 |
| NMSLIB | 35 | 14 | 60 | 23 | 34.3 | 15 | 57.1 | 12 | 65.7 |
| Faiss | 37 | 14 | 62.2 | 22 | 40.5 | 15 | 59.5 | 16 | 56.8 |
Embedding processor optimization
In OpenSearch 3.0, we added skip_existing support in the text_embedding processor to improve embedding ingestion performance. Previously, the processor made ML inference calls regardless of whether it was adding new embeddings or updating existing embeddings. With this feature, users now have an option to configure the processor so that it skips inference calls when the target embedding field is not changed. This feature applies to both dense embeddings and sparse embeddings. By skipping the inference calls, this optimization can reduce ingestion latencies by up to 70% for text embeddings, 40% for text/image embeddings, and 80% for sparse text embeddings.
Pruning for neural sparse search
Neural sparse search is a semantic search technique built on the native Lucene inverted index. It encodes documents and queries into sparse vectors, in which each entry represents a token and its corresponding semantic weight. Because the encoding process expands tokens with semantic weights during encoding, the number of tokens in the sparse vectors is often higher than in the original text. These vectors also follow a long-tail distribution: many tokens have low semantic importance but still consume significant storage. As a result, index sizes produced by sparse models can be 4 to 7 times larger than those generated by BM25. Introduced in OpenSearch 2.19, pruning helps address this issue by removing tokens with relatively low weights during ingestion and search. Depending on the strategy used, pruning can reduce index size by up to 60% with only about a 1% impact on search relevance.
Indexing and ingestion performance
OpenSearch 3.0 maintains the indexing throughput of the 2.x series while integrating updates from Lucene 10. In benchmark tests indexing 70 million documents (60 GB) on an r5.xlarge node, version 3.0 sustained a throughput of approximately 20,000 documents per second, matching the performance of OpenSearch 2.19 under identical bulk ingestion conditions. Ingestion time and segment counts were also comparable after normalizing for segment merges, indicating that the format changes introduced by Lucene 10 add minimal overhead for typical workloads.
OpenSearch 3.0 enables support for sparse doc values introduced in Lucene 10. When indexes are sorted (for example, by timestamp) Lucene builds skip lists that accelerate range queries and aggregations. While this introduces minor indexing overhead, it significantly improves query efficiency. In time-series benchmarks, enabling sparse doc values had no impact on ingestion speed while improving date-based query performance.
Segment merging behavior remains stable in OpenSearch 3.0, with a few updated defaults to better utilize modern hardware. Force merge now uses 1/4th of machine cores instead of 1, the default floor segment size has increased from 4 MB to 16 MB, and maxMergeAtOnce changed from 10 to 30, which is aligned with the Lucene 10 defaults. Additionally, maxMergeAtOnce is now available as a cluster-level setting for custom tuning. While one extra segment was observed after ingestion in 3.0 (20 compared to 19 in 2.19), forced merges equalized the results without increasing CPU usage or garbage collection overhead. All other aspects of the merge policy remain unchanged.
Vector indexing also saw significant improvements in OpenSearch 3.0. By using Lucene’s KnnVectorsFormat, 3.0 supports incremental HNSW graph merging, which reduces memory usage and eliminates the need for full graph rebuilds. This enhancement lowered the memory footprint and reduced vector index build time by ~30% compared to version 1.3. Combined with earlier optimizations such as byte compression, OpenSearch 3.0 can index large vector datasets using up to 85% less memory than earlier releases.
In summary, OpenSearch 3.0 maintains the indexing performance of the 2.x series while delivering improved memory efficiency and incorporating Lucene 10 enhancements that boost query performance without impacting ingestion speed.
Roadmap for OpenSearch 3.1 and beyond
Performance continues to be a central focus for the OpenSearch Project. Based on the public roadmap and upcoming 3.1 release, several initiatives are underway:
-
Building on Lucene 10: Looking ahead, OpenSearch 3.x releases will continue to build on this foundation. Upcoming efforts include using Lucene’s concurrent segment execution for force-merged indexes and integrating asynchronous disk I/O using the new
IndexInput.prefetch()API. We are also planning to evaluate support for sparse doc values and block-level metadata in order to enable more efficient range queries and aggregations. These enhancements, combined with continued performance improvements (for example, in term query,search_after, and sort performance), will help OpenSearch deliver even lower latencies and better throughput across diverse workloads. -
Cost-based query planning: OpenSearch is developing a query planner that uses statistics and cost modeling to select execution strategies more efficiently. This includes choosing between bitset and term filters, determining clause order, and deciding when to enable concurrent segment search. This effort targets improved latency and resource usage, especially for complex queries.
-
Streaming query execution: We’re currently working on introducing a streaming model, in which query stages can begin before the previous ones fully complete. This approach should lower latency and memory usage by allowing results to flow incrementally. Initial support is planned for specific aggregations and query types in the 3.x series.
-
gRPC/protobuf-based communication: As per-shard latency decreases, coordination overhead becomes more significant. Optimizations are planned to reduce serialization costs, make coordinator node communication with multiple data nodes more efficient, and support more parallelism in response handling across nodes. We’re also considering adding support for a gRPC-based API using protocol buffers (protobuf) for serialization and deserialization.
-
Join support and advanced queries: Native join support is planned for 2025, with an emphasis on runtime efficiency. Techniques like index-level bloom filters or pre-join caching will be used to reduce query costs and support production-grade usage.
-
Native SIMD and vectorization: OpenSearch is exploring the use of native code and SIMD instructions beyond Lucene for operations like aggregations and result sorting. These efforts aim to reduce JVM overhead and improve throughput in CPU-bound workloads.
-
GPU acceleration for quantized vector indexes: OpenSearch is expanding its GPU acceleration capabilities for quantized vector indexes. While the 3.0 release introduced GPU support for full-precision (FP32) indexes, the upcoming 3.1 release will extend GPU acceleration to a broader range of quantization techniques, including FP16, byte, and binary indexes. Looking beyond version 3.1, OpenSearch plans to extend GPU capabilities for search workloads.
-
Disk-optimized vector search—Phase 2: OpenSearch 3.1 will introduce significant enhancements to disk-optimized vector search capabilities, marking Phase 2 of its optimization journey. Building upon the success of binary quantization, the system will incorporate the following techniques: random rotation and Asymmetric Distance Computation (ADC). These improvements, inspired by the innovative RaBitQ paper, deliver a substantial boost to recall performance while maintaining the benefits of disk optimization.
-
Partial loading of graphs using the Faiss vector engine: Starting with version 3.1, the introduction of partial graph loading will mark a major breakthrough in how vector search operates. Unlike traditional approaches that load entire graphs into memory, this new approach will selectively load only the required portions of the graph needed for search traversal. This smart loading mechanism will deliver two crucial benefits: it will dramatically reduce memory consumption and enable billion-scale workloads to run efficiently even in single-node environments.
-
Support for BFloat16 (efficient FP16) for vectors: FP16 support using the Faiss scalar quantizer (SQfp16) reduces memory usage by 50% while maintaining performance and recall levels similar to FP32 vectors. However, it has a limitation: input vectors must fall within the range of [-65504, 65504]. BFloat16 offers an alternative that provides the full range of FP32 by trading off precision (it supports up to 2 or 3 decimal values, or 7 mantissa bits) and still uses 16 bits per dimension (providing a 50% memory reduction).
-
Multi-tenancy/high-cardinality filtering in vector search: OpenSearch is taking multi-tenant vector search to the next level with its enhanced filtering capabilities. At the core of this improvement is an innovative approach to partitioning HNSW graphs based on tenant boundaries. This strategic enhancement will deliver two critical advantages: superior search accuracy and robust data isolation between tenants. By organizing vector search data structures according to tenant boundaries, filter queries operate exclusively within their respective tenant partitions, eliminating cross-tenant noise and improving precision.
-
Improving vector search throughput with smart query routing: By implementing semantic-based data organization across OpenSearch nodes, grouping similar embeddings together, you will be able to enable targeted searching of relevant nodes for nearest neighbors. This approach will allow you to search a subset of shards per query, potentially increasing throughput by up to 3x while reducing compute requirements.
OpenSearch 3.1 will be the first minor release to build on 3.0 based on the OpenSearch release schedule. It will include Lucene updates, refinements to concurrent search, and improvements to aggregation, vector, and indexing frameworks. As usual, we’ll share performance updates in the release notes and blog posts.
Appendix: Benchmarking methodology
All performance comparisons were conducted using a repeatable process based on the OpenSearch Benchmark tool and the Big5 workload. Benchmarks covered match queries, terms aggregations, range filters, date histograms, and sorted queries. The dataset (~100 GB, 116 million documents) reflects time-series and e-commerce use cases.
Environment: Tests were run on a single-node OpenSearch cluster using c5.2xlarge Amazon Elastic Compute Cloud (Amazon EC2) instances (8 vCPUs, 16 GB RAM, 8 GB JVM heap). Default settings were used unless noted. Indexes had one primary shard and no replicas to avoid multi-shard variability. Documents were ingested chronologically to simulate time-series workloads.
Index settings: We used Lucene’s LogByteSizeMergePolicy and did not enable explicit index sorting. In some tests, a force merge was applied to normalize segment counts (for example, 10 segments in both 2.19 and 3.0) in order to ensure a fair comparison.
Execution: Each operation was repeated multiple times. We discarded warmup runs and averaged the next three runs. Latency metrics included p50, p90, and p99; throughput was also recorded. OpenSearch Benchmark was run in throughput-throttled mode to record accurate query latency for each operation type.
Software: Comparisons used OpenSearch 2.19.1 (Java 17) and 3.0.0-beta (Java 21, Lucene 10.1.0). Only default plugins were enabled. Vector benchmarks used Faiss + HNSW using the k-NN plugin, with recall measured against brute-force results.
Metrics: Big5 median latency is the simple mean of the five core query types. Aggregate latency is the geometric mean, used for overall comparison. Speedup factors are reported relative to OpenSearch 1.3 where noted.
| Buckets | Query | Order | OS 1.3.18 | OS 2.7 | OS 2.11.1 | OS 2.12.0 | OS 2.13.0 | OS 2.14 | OS 2.15 | OS 2.16 | OS 2.17 | OS 2.18 | OS 2.19 | OS 3.0 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Text queries | query-string-on-message | 1 | 332.75 | 280 | 276 | 78.25 | 80 | 77.75 | 77.25 | 77.75 | 78 | 85 | 4 | 4 |
| query-string-on-message-filtered | 2 | 67.25 | 47 | 30.25 | 46.5 | 47.5 | 46 | 46.75 | 29.5 | 30 | 27 | 11 | 11 | |
| query-string-on-message-filtered-sorted-num | 3 | 125.25 | 102 | 85.5 | 41 | 41.25 | 41 | 40.75 | 24 | 24.5 | 27 | 26 | 27 | |
| term | 4 | 4 | 3.75 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | |
| Sorting | asc_sort_timestamp | 5 | 9.75 | 15.75 | 7.5 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 |
| asc_sort_timestamp_can_match_shortcut | 6 | 13.75 | 7 | 7 | 6.75 | 6 | 6.25 | 6.5 | 6 | 6.25 | 7 | 7 | 7 | |
| asc_sort_timestamp_no_can_match_shortcut | 7 | 13.5 | 7 | 7 | 6.5 | 6 | 6 | 6.5 | 6 | 6.25 | 7 | 7 | 7 | |
| asc_sort_with_after_timestamp | 8 | 35 | 33.75 | 238 | 212 | 197.5 | 213.5 | 204.25 | 160.5 | 185.25 | 216 | 150 | 168 | |
| desc_sort_timestamp | 9 | 12.25 | 39.25 | 6 | 7 | 5.75 | 5.75 | 5.75 | 6 | 6 | 8 | 7 | 7 | |
| desc_sort_timestamp_can_match_shortcut | 10 | 7 | 120.5 | 5 | 5.5 | 5 | 4.75 | 5 | 5 | 5 | 6 | 6 | 5 | |
| desc_sort_timestamp_no_can_match_shortcut | 11 | 6.75 | 117 | 5 | 5 | 4.75 | 4.5 | 4.75 | 5 | 5 | 6 | 6 | 5 | |
| desc_sort_with_after_timestamp | 12 | 487 | 33.75 | 325.75 | 358 | 361.5 | 385.25 | 378.25 | 320.25 | 329.5 | 262 | 246 | 93 | |
| sort_keyword_can_match_shortcut | 13 | 291 | 3 | 3 | 3.25 | 3.5 | 3 | 3 | 3 | 3 | 4 | 4 | 4 | |
| sort_keyword_no_can_match_shortcut | 14 | 290.75 | 3.25 | 3 | 3.5 | 3.25 | 3 | 3.75 | 3 | 3.25 | 4 | 4 | 4 | |
| sort_numeric_asc | 15 | 7.5 | 4.5 | 4.5 | 4 | 4 | 4 | 4 | 4 | 4 | 17 | 4 | 3 | |
| sort_numeric_asc_with_match | 16 | 2 | 1.75 | 2 | 2 | 2 | 2 | 1.75 | 2 | 2 | 2 | 2 | 2 | |
| sort_numeric_desc | 17 | 8 | 6 | 6 | 5.5 | 4.75 | 5 | 4.75 | 4.25 | 4.5 | 16 | 5 | 4 | |
| sort_numeric_desc_with_match | 18 | 2 | 2 | 2 | 2 | 2 | 2 | 1.75 | 2 | 2 | 2 | 2 | 2 | |
| Terms aggregations | cardinality-agg-high | 19 | 3075.75 | 2432.25 | 2506.25 | 2246 | 2284.5 | 2202.25 | 2323.75 | 2337.25 | 2408.75 | 2324 | 2235 | 628 |
| cardinality-agg-low | 20 | 2925.5 | 2295.5 | 2383 | 2126 | 2245.25 | 2159 | 3 | 3 | 3 | 3 | 3 | 3 | |
| composite_terms-keyword | 21 | 466.75 | 378.5 | 407.75 | 394.5 | 353.5 | 366 | 350 | 346.5 | 350.25 | 216 | 218 | 202 | |
| composite-terms | 22 | 290 | 242 | 263 | 252 | 233 | 228.75 | 229 | 223.75 | 226 | 333 | 362 | 328 | |
| keyword-terms | 23 | 4695.25 | 3478.75 | 3557.5 | 3220 | 29.5 | 26 | 25.75 | 26.25 | 26.25 | 27 | 26 | 19 | |
| keyword-terms-low-cardinality | 24 | 4699.5 | 3383 | 3477.25 | 3249.75 | 25 | 22 | 21.75 | 21.75 | 21.75 | 22 | 22 | 13 | |
| multi_terms-keyword | 25 | 0* | 0* | 854.75 | 817.25 | 796.5 | 748 | 768.5 | 746.75 | 770 | 736 | 734 | 657 | |
| Range queries | keyword-in-range | 26 | 101.5 | 100 | 18 | 22 | 23.25 | 26 | 27.25 | 18 | 17.75 | 64 | 68 | 14 |
| range | 27 | 85 | 77 | 14.5 | 18.25 | 20.25 | 22.75 | 24.25 | 13.75 | 14.25 | 11 | 14 | 4 | |
| range_field_conjunction_big_range_big_term_query | 28 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | |
| range_field_conjunction_small_range_big_term_query | 29 | 2 | 1.75 | 2 | 2 | 2 | 2 | 1.5 | 2 | 2 | 2 | 2 | 2 | |
| range_field_conjunction_small_range_small_term_query | 30 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | |
| range_field_disjunction_big_range_small_term_query | 31 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2.25 | 2 | 2 | 2 | |
| range-agg-1 | 32 | 4641.25 | 3810.75 | 3745.75 | 3578.75 | 3477.5 | 3328.75 | 3318.75 | 2 | 2.25 | 2 | 2 | 2 | |
| range-agg-2 | 33 | 4568 | 3717.25 | 3669.75 | 3492.75 | 3403.5 | 3243.5 | 3235 | 2 | 2.25 | 2 | 2 | 2 | |
| range-numeric | 34 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | |
| Date histograms | composite-date_histogram-daily | 35 | 4828.75 | 4055.5 | 4051.25 | 9 | 3 | 2.5 | 3 | 2.75 | 2.75 | 3 | 3 | 3 |
| date_histogram_hourly_agg | 36 | 4790.25 | 4361 | 4363.25 | 12.5 | 12.75 | 6.25 | 6 | 6.25 | 6.5 | 7 | 6 | 4 | |
| date_histogram_minute_agg | 37 | 1404.5 | 1340.25 | 1113.75 | 1001.25 | 923 | 36 | 32.75 | 35.25 | 39.75 | 35 | 36 | 37 | |
| range-auto-date-histo | 38 | 10373 | 8686.75 | 9940.25 | 8696.75 | 8199.75 | 8214.75 | 8278.75 | 8306 | 8293.75 | 8095 | 7899 | 1871 | |
| range-auto-date-histo-with-metrics | 39 | 22988.5 | 20438 | 20108.25 | 20392.75 | 20117.25 | 19656.5 | 19959.25 | 20364.75 | 20147.5 | 19686 | 20211 | 5406 |
While results may vary in different environments, we controlled for noise and hardware variability. The relative performance trends are expected to hold across most real-world scenarios. The OpenSearch Benchmark workload is open source, and we welcome replication and feedback from the community.




