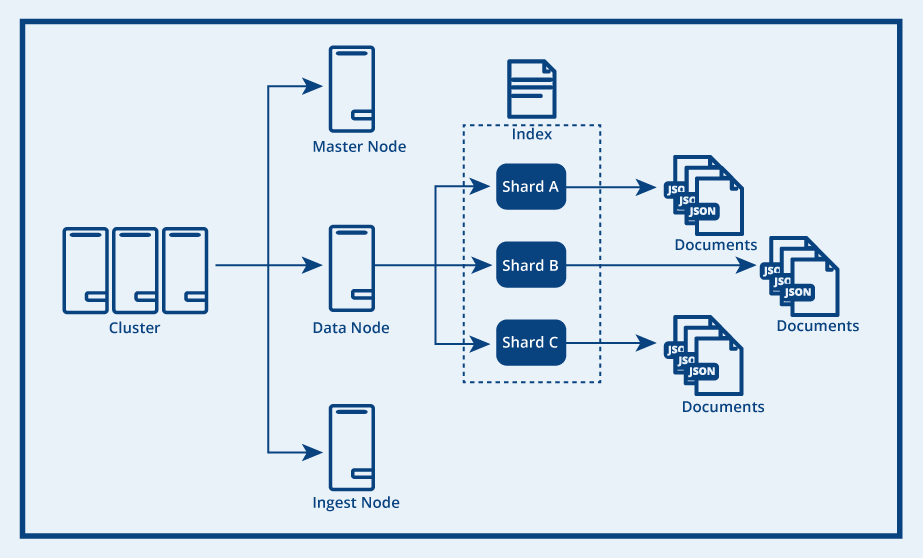
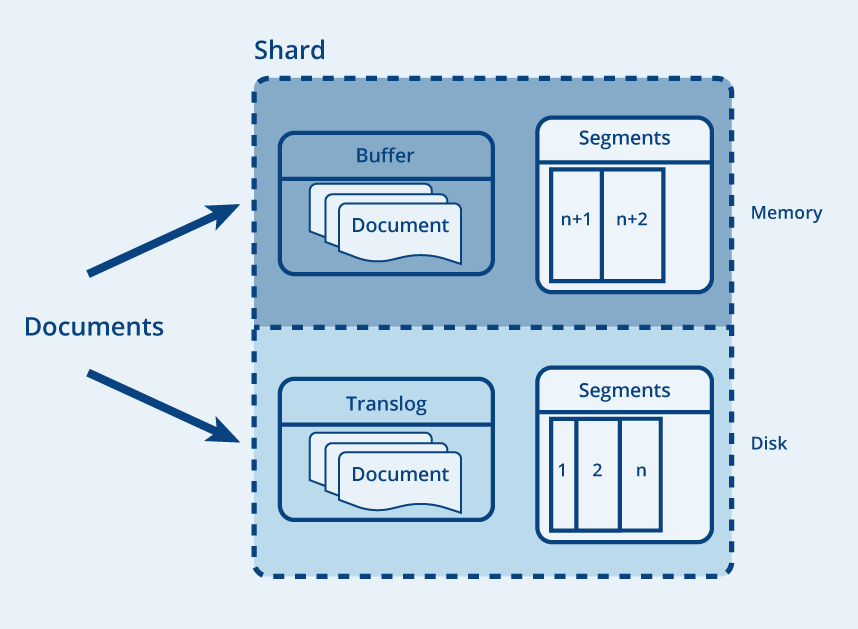
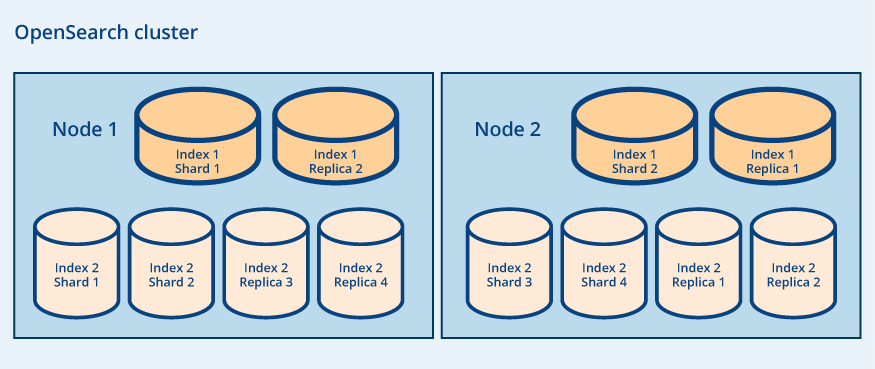
OpenSearch Core is a high-performance search engine built on the robust indexing and search capabilities of Apache Lucene.
It allows you to ingest large volumes of content in diverse formats using OpenSearch Data Prepper, index complex multidimensional data, and perform efficient searches that return highly accurate results.
You can then explore and visualize your data seamlessly with OpenSearch Dashboards.