
OpenSearch Data Prepper
OpenSearch Data Prepper is an open-source data collector designed to filter, enrich, transform, normalize, and aggregate data before sending it to downstream systems like OpenSearch for analysis and visualization.
Built for high-performance ingestion and transformation, Data Prepper serves as a powerful server-side pre-processing pipeline that ensures your data is properly structured and formatted for your specific use case.
Whether you’re digging into trace analytics to pinpoint performance bottlenecks or diving deep into log data for operational insights, Data Prepper lets you build custom pipelines that turn raw information into actionable intelligence.

OpenSearch Data Prepper pipelines and attributes
Streamline data ingestion with ease
Optimize and enhance the collection, transformation, and enrichment of data before it reaches your OpenSearch cluster.
OpenSearch Data Prepper is a powerful pipeline tool that efficiently processes logs, metrics, and traces—structuring and optimizing them for faster indexing and deeper insights.
Designed for observability at scale
Data Prepper supports popular formats like OpenTelemetry and integrates seamlessly into observability workflows.
With features like filtering, transformation, and trace correlation, it ensures your data is clean, context-rich, and ready for real-time insights.
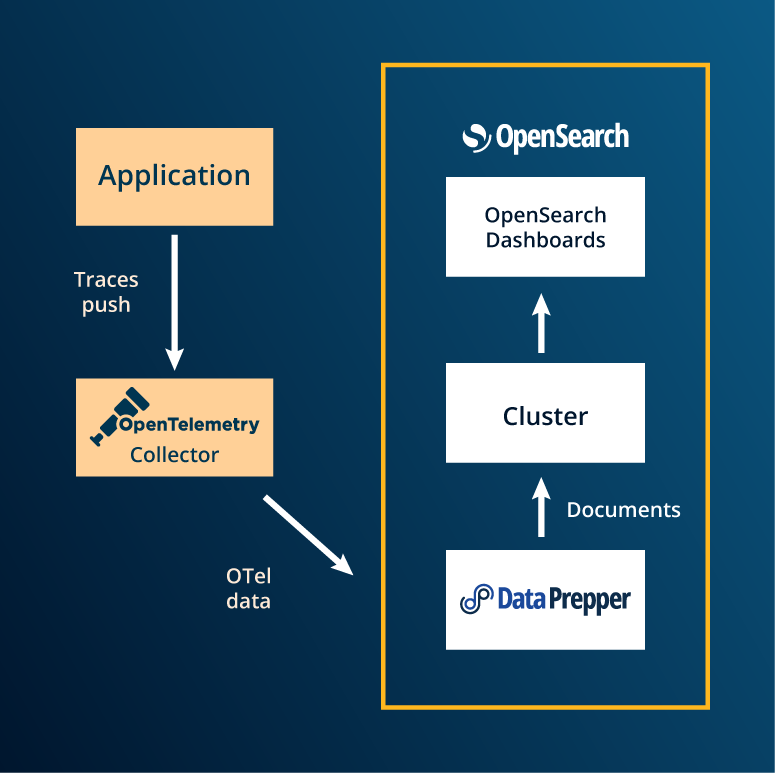
Data Prepper components for ingesting, transforming, and visualizing trace data
Transform and route data at scale
OpenSearch Data Prepper is a powerful, standalone component of the OpenSearch project designed to accept, filter, transform, enrich, and route data at scale.
Unlike OpenSearch plugins, Data Prepper operates independently—giving you the flexibility to tailor your data pipelines without being tied directly into the OpenSearch engine.
Built to handle high-throughput ingestion scenarios, OpenSearch Data Prepper is an essential tool for converting raw, unstructured data into a form that’s optimized for OpenSearch indexing and analysis. With Data Prepper, you can unlock a range of observability and analytics use cases.
OpenTelemetry data pipeline
High-performance ingestion
Filter, enrich, transform, and normalize your data with ease, then send it downstream for fast, Insightful analysis and visualization.
Streamline your data flow into OpenSearch
Data Prepper’s modular design and rich processing capabilities make it the go-to solution for anyone looking to build robust high-performance data flows into OpenSearch.
Improved data quality and observability
OpenSearch Dashboards is fully open-source and extensible, giving developers and analysts the freedom to customize, integrate, and extend visual analytics.
Customizable and open source
Build custom pipelines to transform, enrich, and route data for better operational visibility. And as an open-source project, Data Prepper gives you the freedom to adapt and innovate—supported by a vibrant, collaborative community.
Key features
Flexible data collection from any source
Data Prepper supports flexible data pipelines and sources, temporary buffers for better throughput, a variety of processors for data transformation, and OpenSearch sinks to send data directly into your cluster.
Powerful data transformation and enrichment
Transform raw data into usable insights through robust filtering, enrichment, and normalization capabilities. Reshape and standardize data formats, enhance events with contextual information like geolocation, and run stateful aggregations—Data Prepper enables streamlined, source-agnostic analysis at scale.
Robust data processing with built-in processors
Data Prepper’s versatile set of processors allows you to run advanced data manipulations with ease. From renaming fields and transforming strings to performing arithmetic on numeric values, it enables fine-grained control over your data.
Reliable data delivery from source to sink
Ensure end-to-end reliability with built-in acknowledgments, retry logic, and error handling. Data Prepper supports multiple output destinations—including OpenSearch and multiple AWS services—and uses in-memory or disk-based buffering to manage throughput and maintain data durability under load.
Seamless integrations for enhanced observability
Easily integrate with key services to expand OpenSearch’s capabilities. Ingest data from DynamoDB, support OpenTelemetry for metrics, and enable AI-powered analysis for security and log insights. Data Prepper also supports secure secret injection, allowing for powerful and safe pipeline configurations.
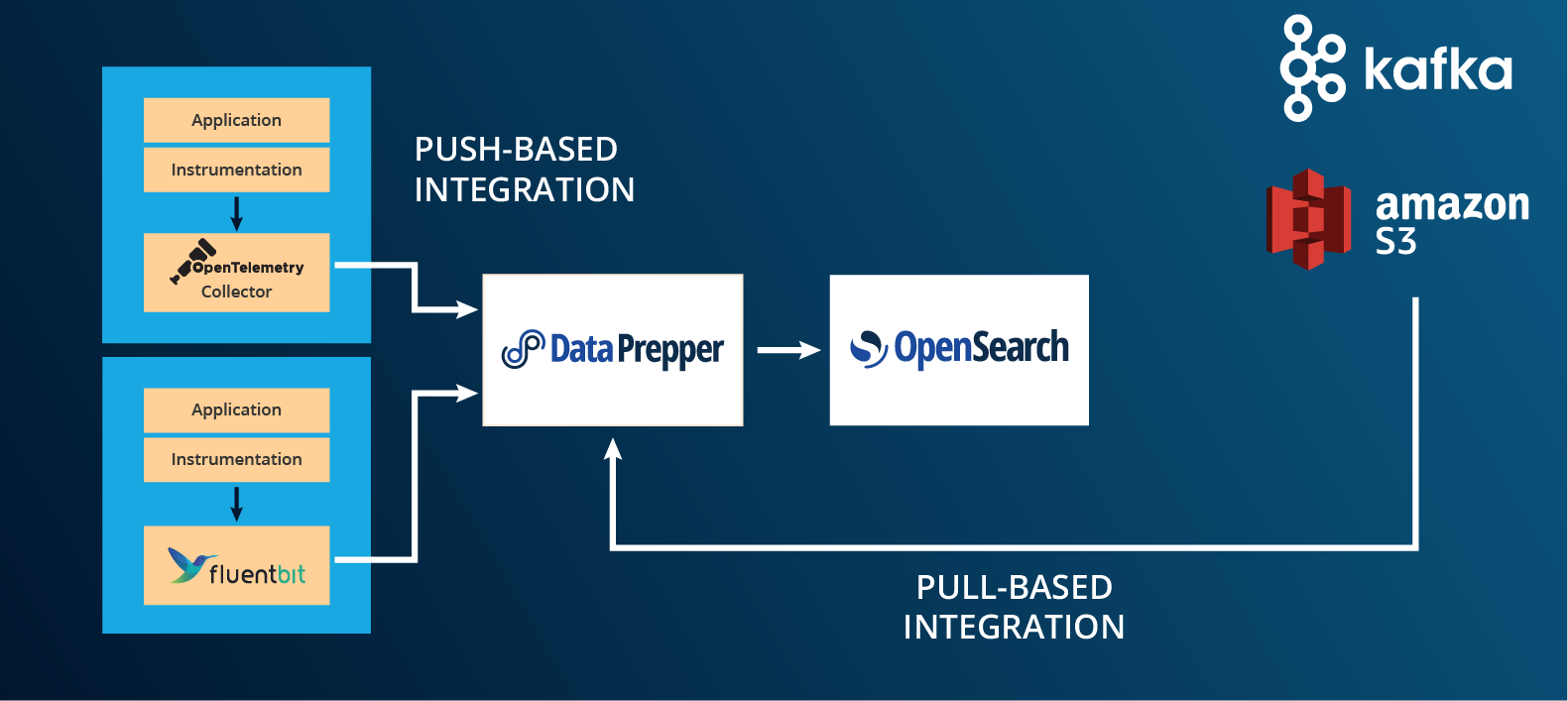
Flexible integration models: push or pull
Data Prepper supports both push-based and pull-based integrations, giving you flexible control over data flow. It can receive data from OpenTelemetry collectors or actively fetch from services like Apache Kafka and AWS S3 using agents like FluentBit, adapting seamlessly to your architecture.
Benefits
Smarter transformations and observability
Improve data quality and observability by transforming raw input into structured, actionable insights. With filtering, enriching, and normalization, Data Prepper streamlines analysis and visualization—accelerating investigations and analyses.
Cut costs, boost Insights
Optimize data ingestion costs through smart deduplication and sampling, minimizing noise and reducing storage demands. OpenSearch Data Prepper delivers efficiency without sacrificing visibility.
Security and compliance built-in
OpenSearch Data Prepper allows you to safeguards sensitive data with built-in redaction and obfuscation tools, helping you meet privacy and compliance requirements. With conditional routing, it ensures data flows to the right locations—supporting data residency laws and regulatory standards.
Getting started
Check out the getting started guide and learn more about OpenSearch Data Prepper’s capabilities and how to quickly build powerful, efficient data pipelines.
Learn more about Data Prepper pipeline components, the foundational elements that enable flexible data processing, transformation, and routing at scale.
View some common OpenSearch use cases to find out how to customize it for your specific data pipeline and observability needs.