
















OpenSearch Project update: A look at performance progress through version 2.14
OpenSearch covers a broad range of functionality for applications involving document search, e-commerce search, log analytics, observability, and data analytics. All of these applications depend on a full-featured, scalable, reliable, and high-performance foundation. In the latest OpenSearch versions, we’ve added new features such as enhanced artificial intelligence and machine learning (AI/ML) semantic/vector search capabilities, neural search, hybrid search, flat objects, and zero-ETL integrations. As we continue to add new features, we are also improving scalability, reliability, and performance both for existing and for new features. These improvements allow us to support ever-growing data collections with high throughput, low latency, lower resource consumption, and, thus, lower costs. This blog post focuses on performance improvements in OpenSearch 2.12, 2.13, and 2.14. These fall into four broad categories: text querying, vector storage and querying, ingestion and indexing, and storage efficiency.
We evaluated performance improvements using the OpenSearch Big5 workload, which covers the types of queries common in search and log analytics, including text queries, sorting, term aggregations, range queries, and date histograms. This provides an objective and easy-to-replicate benchmark for performance work.
Performance improvements through 2.14
Since the inception of the OpenSearch Project, we have achieved significant increases in speed.
The following graph shows the relative improvements by query category as the 90th percentile latencies, with a baseline of OpenSearch 1.0. Every category improved considerably, some dramatically. For the full results, see the Appendix.
The heavy green line summarizes the overall improvements as the geometric mean of the individual categories of improvement, showing continuous progress in performance.
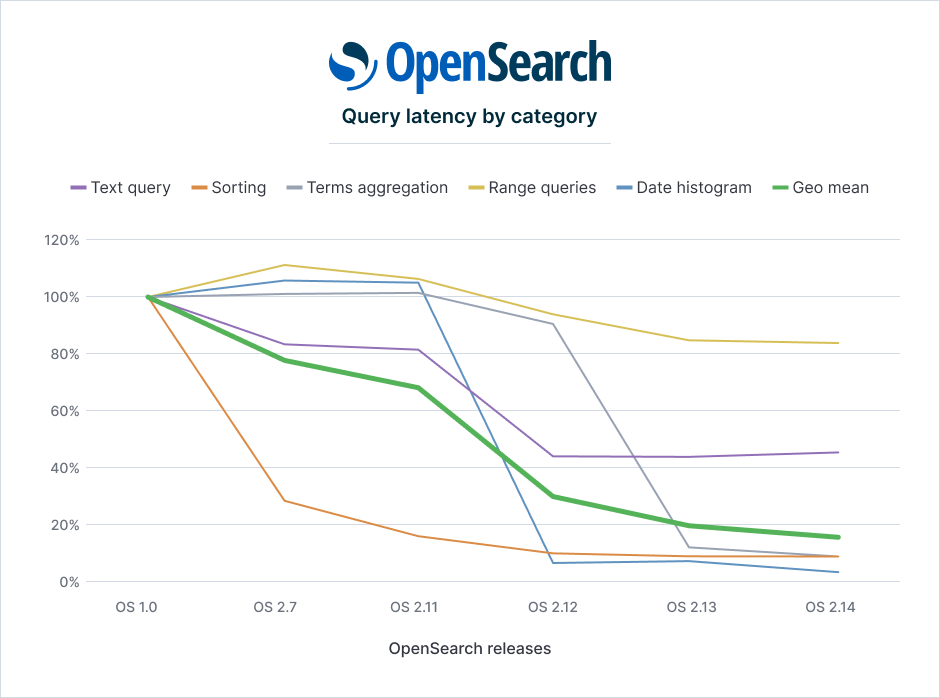
Queries
OpenSearch has made the following query improvements.
Text queries
Text queries are the foundation of text search. When used for traditional document search, text search determines not just whether certain text is included in the document but also where and how often. This is needed for the classic term frequency calculation (TF/IDF or BM25), which is the basis for result ranking, as well as for highlighting (snippeting) and proximity matching.
However, many applications do not need this additional information—it’s enough to know which documents contain the terms. This applies when the application wants all documents with a given term, as is typical in an analytics application, or when it wants 100% recall in order to apply its own result reranking.
For these applications, OpenSearch 2.12 introduced the match_only_text field. This field type dramatically reduces the space needed for indexes and speeds up query execution because there is no complicated scoring for relevance ranking. At the same time, it supports all standard text query types, except for interval and span queries.
Using match_only_text, text queries are 47% faster in OpenSearch 2.12 than in 2.11 and 57% faster than in OpenSearch 1.0.
Term aggregations
Term aggregations are an important tool in data analytics because they allow you to slice and dice data using multiple criteria. For example, you might want to group the brands, model years, and colors of a collection of cars in your data.
OpenSearch 2.13 speeds up term aggregations for global term aggregations in immutable collections such as log data. This is an important and common analytics use case. OpenSearch gains this efficiency by using the term frequencies that Lucene precalculates.
Evaluating term aggregations on Big5 data shows speed improvements of a factor of 85 to 100.
Date histograms
Date histograms are OpenSearch’s way of grouping data by date. Almost every Dashboard or Discover visualization in OpenSearch Dashboards depends on this functionality. For example, you might want to aggregate the logs of every HTTP request sent to your site by week. Date histogram optimizations in OpenSearch 2.12 provide speed improvements ranging from 10 to 50 times on the Big5 benchmark, in cases where there are no sub-aggregations in range filters.
Multi-term queries and numeric fields
Multi-term queries are commonly used in analytics to simultaneously aggregate by many terms, often retrieving only the top n results. OpenSearch 2.12 accelerates multi-term queries on keyword fields by over 40% by taking advantage of Lucene’s IndexOrDocValuesQuery.
In version 2.14, we also use the IndexOrDocValuesQuery to increase search speed on numeric, IP, Boolean, and date fields, even when the fields are not indexed. This means that you can save storage space by not creating indexes for less commonly used search fields.
Semantic vectors
Vector search is the foundation of modern semantic/neural search. With semantic search, documents are embedded in a high-dimensional vector space, which preserves important semantic relations, and then indexed for fast retrieval. At search time, queries are embedded in the same space, and the search engine finds similar document vectors by using a nearest-neighbor algorithm (k-NN or approximate nearest neighbor [ANN]). The documents that are semantically close to the query are more likely to represent relevant results.
Document vectors can require a lot of storage space, especially when documents are segmented to provide full content coverage. Decreasing the amount of necessary storage directly lowers resource consumption and costs.
Vector search cost reduction
By reducing the vector elements from 32-bit to 16-bit (fp16) floating-point numbers, OpenSearch 2.13 reduces the amount of storage required by 45–50%. Our experiments show that this has little or no effect on the quality of the results: Recall remains above 95%, and query latency is unaffected.
OpenSearch 2.14 also improves the memory usage of IVFPQ and HNSWPQ vector indexes by unifying the storage of index metadata.
Efficient filtering
As a user of nearest-neighbor semantic search, you often want to combine vector similarity with filtering on other fields. Simple post-filtering is inefficient and produces poor results. Introduced in OpenSearch 2.9 and improved in OpenSearch 2.10, efficient filtering filters during the nearest-neighbor search. In OpenSearch 2.14, we enhanced the filtering logic to further reduce query latencies for filtered vector search by approximately 30% at P99, using the Faiss engine.
Indexing
So far, we’ve been discussing improvements to search latency and memory efficiency. But we have also improved indexing performance. Many workloads, notably log analytics workloads, spend most of their computing resources on the indexing phase. For these workloads, accelerating indexing performance can significantly reduce costs. In OpenSearch 2.7, we introduced segment replication, which improves performance by up to 40% compared to document replication by eliminating redundant indexing. OpenSearch 2.11 introduced additional improvements to segment replication, allowing it to use a remote object store for improved durability and scalability.
Storage
OpenSearch 2.13 enhances storage and retrieval efficiency by introducing more efficient compression codecs. These codecs reduce disk space usage without compromising performance. Additionally, OpenSearch 2.13 introduced enhanced data tiering capabilities to improve data lifecycle management. This allows you to reduce storage costs and improve performance on a wide range of hardware.
Roadmap for 2024
Here are some planned improvements that we have on the roadmap for the rest of 2024.
Core search engine
OpenSearch continues to improve the core search engine. Our full plans are available on GitHub.
We are planning the following enhancements:
- Supporting fine-grained customer monitoring of query execution, allowing you to identify problematic queries, diagnose query execution bottlenecks, and tune query performance.
- Optimizing common query execution infrastructure by developing multi-level caching (tiered caching); faster interconnections among components using an efficient binary format (Protobuf).
- Improving query execution itself, using document reordering to optimize query throughput and storage efficiency (graph bipartite partitioning); analyzing and rewriting complex queries to make them run more efficiently; dynamic pruning; count-only caching.
- Modularizing the query engine to make future improvements faster and easier.
Hybrid search
Hybrid search combines lexical and semantic vector search in order to get the best of both worlds. Highly specific names—like part numbers—are best found using lexical search, while broader queries are often best handled by semantic vector search. We have supported hybrid search since OpenSearch 2.10.
We are planning the following hybrid search enhancements:
- By executing lexical and vector searches in parallel, we can achieve a latency improvement of up to 25%.
- Supporting re-sorting of hybrid query results.
- Supporting additional algorithms for combining query results. In particular, reciprocal rank fusion has shown good results for some applications.
- Returning the raw scores of subqueries, which are useful for debugging and relevance tuning.
Vector search
Semantic vector search is a powerful technique for finding semantic similiarities. However, it can be costly because indexing vectors to make them efficient for search is time consuming, and the vectors themselves can consume large amounts of memory.
We are currently working on the following vector search improvements:
- Accelerating vector indexing by 80% and reducing the memory required for indexing.
- Reducing the amount of space needed to store vectors by compressing vector components from 32 bits to 16, 8, and even 1 bit. Our experiments show modest reductions in search quality (recall) with 16- and 8-bit components; we are still analyzing the 1-bit use case (binary quantization).
- Reducing costs by employing disk-based ANN algorithms that use external storage (SSDs, Amazon S3, and so on).
Vector techniques have also been less flexible than lexical techniques in many ways, so we are:
- Improving search relevance by supporting reranking on compressed vectors.
- Supporting ANN vector search for multi-tenant use cases, where each tenant has its own subcollection. This is especially valuable for customers each of whose user organizations has a large vector collection.
Performance benchmarking
We are planning to update the Big5 workload mappings and settings. In particular, we’ll add support for dynamic templates, configurable merge policies, match-only text, and setting the default query field to message.
Conclusion
While we’re continuing to expand OpenSearch functionality, we are also investing in improving the performance, efficiency, and robustness of the system for every workload. In particular, vector techniques are being widely adopted both for pure semantic search and for hybrid semantic and lexical search.
The OpenSearch team at AWS works in collaboration with the larger OpenSearch community. Without your contributions to testing, feedback, and development, OpenSearch would not be where it is today. Thank you.
Stay tuned to our blog and GitHub for further updates and insights into our progress and future plans.
Appendix: Benchmark tests and results
This section provides detailed information about the performance benchmarks we used and the results we obtained. The data was collected by using OpenSearch Benchmark to run the Big5 workload against different OpenSearch distributions and configurations. In particular:
- We used OpenSearch Benchmark—our standard benchmarking tool—for testing. Rally might produce different results.
- We ran each test against a single-node cluster to ensure better reproducibility and an easier setup.
- The instance type was c5.2xlarge—8 vCPU, 16 GB—an average instance type. Using oversized instances can conceal resource usage efficiency improvements.
- The Big5 index comprised a single shard with no replicas (run with
--workload-params="number_of_replicas:0"). - During the tests, we ingested data using a single bulk indexing client to ensure that data was ingested in chronological order.
- We ran the tests in benchmarking mode (
target-throughputwas disabled) so that the OpenSearch client sent requests to the OpenSearch cluster as quickly as possible. - We configured the shard merge policy with LogByteSizeMergePolicy because this optimization was in place last year, prior to the publishing of this blog post.
- The corpus size of the workload was 60 GB, 70M documents. The store size after ingestion was 15 GB for the primary shard. If overhead such as doc values is eliminated, Resident Set Size (RSS) should be about 8 GB, which should match the JVM heap size for the instance. Having most data in-memory should provide an ideal performance assessment.
The following table presents the latency comparison.
| Query type | OS 1.0 | OS 2.7 | OS 2.11 | OS 2.12 | OS 2.13 | OS 2.14 | |
|---|---|---|---|---|---|---|---|
| Big 5 areas mean latency, ms | Text query | 44.34 | 37.02 | 36.12 | 19.42 | 19.41 | 20.01 |
| Sorting | 65.04 | 18.58 | 10.21 | 6.22 | 5.55 | 5.53 | |
| Terms Aggregation | 311.78 | 315.27 | 316.32 | 282.41 | 36.27 | 27.18 | |
| Range query | 4.06 | 4.52 | 4.32 | 3.81 | 3.44 | 3.41 | |
| Date histogram | 4812.36 | 5093.01 | 5057.62 | 310.32 | 332.41 | 141.5 | |
| Relative latency, compared to OS 1.0 (geo mean) | 100% | 78% | 68% | 30% | 19% | 15% | |
| Speedup factor, compared to OS 1.0 (geo mean) | 1.0 | 1.3 | 1.5 | 3.3 | 5.3 | 6.7 |
The following table presents benchmarking results by query category. It shows the P90 Service Time (ms) values.
| Buckets | Query | OS 1.0 | OS 2.7 | OS 2.11.0 | OS 2.12.0 | OS 2.13.0 | OS 2.14 |
|---|---|---|---|---|---|---|---|
| Text Querying | default | 2.79 | 2.65 | 2.41 | 2.5 | 2.34 | 2.27 |
| scroll | 448.9 | 228.42 | 227.36 | 222.1 | 210.41 | 217.82 | |
| query_string_on_message | 180.55 | 173.6 | 168.29 | 8.72 | 9.29 | 8.22 | |
| query_string_on_message_filtered | 174.25 | 125.88 | 146.62 | 102.53 | 110.49 | 135.98 | |
| query_string_on_message_filtered_sorted_num | 238.14 | 183.62 | 180.46 | 112.39 | 120.41 | 139.95 | |
| term | 0.81 | 1.06 | 0.91 | 0.96 | 0.88 | 0.83 | |
| Sorting | desc_sort_timestamp | 13.09 | 159.45 | 28.39 | 20.65 | 18.76 | 20.4483 |
| asc_sort_timestamp | 993.81 | 61.94 | 78.91 | 39.78 | 36.83 | 33.79 | |
| desc_sort_with_after_timestamp | 1123.65 | 163.53 | 28.93 | 19.4 | 18.78 | 22.492 | |
| asc_sort_with_after_timestamp | 1475.51 | 42.69 | 38.55 | 6.22 | 5.55 | 5.14 | |
| desc_sort_timestamp_can_match_shortcut | 15.49 | 31.13 | 7.64 | 7.11 | 6.54 | 6.88 | |
| desc_sort_timestamp_no_can_match_shortcut | 15.29 | 30.95 | 7.63 | 7.17 | 6.53 | 6.74441 | |
| asc_sort_timestamp_can_match_shortcut | 198.59 | 32.46 | 18.93 | 12.64 | 9.45 | 8.91 | |
| asc_sort_timestamp_no_can_match_shortcut | 197.36 | 32.5 | 18.78 | 12.74 | 9.02 | 8.82 | |
| sort_keyword_can_match_shortcut | 181.18 | 2.59 | 2.37 | 2.46 | 2.18 | 2.13 | |
| sort_keyword_no_can_match_shortcut | 181.06 | 2.43 | 2.44 | 2.49 | 2.15 | 2.09 | |
| sort_numeric_desc | 36.19 | 35.15 | 23.6 | 6.04 | 5.83 | 5.78 | |
| sort_numeric_asc | 66.87 | 37.74 | 21.14 | 5.3 | 5.15 | 5.2 | |
| sort_numeric_desc_with_match | 1.23 | 1.01 | 0.99 | 0.92 | 0.85 | 0.8 | |
| sort_numeric_asc_with_match | 1.24 | 0.99 | 0.9 | 0.89 | 0.84 | 0.8 | |
| Terms aggregation | multi_terms_keyword | 0.92 | 1.1 | 1 | 1.05 | 0.91 | 0.89 |
| keyword_terms | 2126.25 | 2117.22 | 2382.37 | 1906.71 | 12.74 | 6.96 | |
| keyword_terms_low_cardinality | 2135.16 | 2121.88 | 2338.1 | 1893.9 | 10.81 | 5.25 | |
| composite_terms | 696.37 | 668.09 | 631.23 | 572.77 | 581.24 | 551.62 | |
| composite_terms_keyword | 1012.96 | 943.35 | 900.66 | 827.16 | 861.81 | 826.18 | |
| Range queries | range | 203.29 | 170.68 | 189.77 | 115.38 | 115.2 | 125.99 |
| range_numeric | 0.81 | 0.96 | 0.87 | 0.9 | 0.76 | 0.75 | |
| keyword_in_range | 210.69 | 179.18 | 200.37 | 123.59 | 124.66 | 134.06 | |
| range_field_conjunction_big_range_big_term_query | 0.92 | 1.13 | 0.99 | 1.01 | 0.91 | 0.82 | |
| range_field_disjunction_big_range_small_term_query | 0.82 | 1.08 | 1.04 | 1 | 0.86 | 0.81 | |
| range_field_conjunction_small_range_small_term_query | 0.83 | 1.09 | 0.93 | 0.98 | 0.85 | 0.81 | |
| range_field_conjunction_small_range_big_term_query | 0.83 | 0.98 | 0.88 | 0.91 | 0.78 | 0.78 | |
| Date histogram | date_histogram_hourly_agg | 3618.5 | 3664.45 | 3785.48 | 8.5 | 9.97 | 3.39 |
| date_histogram_minute_agg | 2854.99 | 2933.76 | 2961.69 | 2518.69 | 2635.16 | 148.69 | |
| composite_date_histogram_daily | 3760.5 | 4016.42 | 3574.18 | 1.44 | 1.51 | 1.39 | |
| range_auto_date_histo | 5267.47 | 5960.21 | 6055.74 | 6784.27 | 6977.05 | 6129.29 | |
| range_auto_date_histo_with_metrics | 12612.77 | 13314.87 | 13637.23 | 13759.51 | 14662.24 | 13208.98 |
If you decide to run your own benchmarking tests, please feel free to share the results with us. As always, we welcome your feedback and contributions, and we’d love to hear from you on the OpenSearch forum.



