
In 2023, generative artificial intelligence (generative AI) captured the mainstream imagination and drove widespread AI-related initiatives. Vector database technology like OpenSearch got a share of the limelight, alleviating generative AI challenges like hallucinations and lack of persistent conversation memory. Builders created AI-powered chatbots designed around retrieval augmented generation (RAG) and OpenSearch. In the process, our users discovered new capabilities with vector search and infused semantic and multimodal search experiences into their OpenSearch-powered applications. Thus, we, the maintainers of the OpenSearch Project, focused on delivering features to fuel vector search and generative AI innovations.
In this blog post, we recap the key 2023 advancements in OpenSearch AI and machine learning (ML) and provide a glimpse into our 2024 roadmap.
Powering vector search
In February 2020, we released OpenSearch k-NN, our foundational vector database capability, to empower innovators to create scalable vector search applications. Today, builders are successfully operating high-scale, mission-critical vector search solutions on OpenSearch. As shared in this blog post, “…OpenSearch currently manages 1.05 billion vectors and supports a peak load of 7,100 vector queries per second to power Amazon Music recommendations.” Another deployment at Amazon “…has indexed a total of 68 billion, 128- and 1024-dimension vectors into OpenSearch Service to enable brands and automated systems to conduct infringement detection, in real-time, through a highly available and fast (sub-second) search API.”
In 2023, we continued to improve our engine’s performance and economics while delivering differentiated value through ease-of-use and developer productivity enhancements.
Vector search engine improvements
In OpenSearch 2.9, we added efficient filtering for our FAISS engine which was previously exclusive to our Lucene k-NN engine. With this feature, you can benefit from the scalability of FAISS and run more performant filtered queries. With efficient filtering, our engine intelligently evaluates strategies like pre-filtering versus exact k-NN matching to optimize on recall and latency tradeoffs.
We also started adding vector quantization support. Instead of operating on vectors with four-bytes per dimension, you can use quantized models to generate vectors with single-byte precision dimensions and create indexes with our Lucene k-NN engine. This allows you to improve performance and cost by reducing your index size and query latency with minimal impact to recall. We plan to add FP16—two-byte precision support—for our FAISS engine in OpenSearch 2.12.
Open source frameworks enable GenAI applications
Open source frameworks for building large language models (LLMs) based applications like LangChain and LlamaIndex flourished this year. Builders have been using these frameworks with OpenSearch to create generative chatbots and conversational search experiences. We were pleased to support the LangChain project and our community by contributing features such as the OpenSearch vector store and RAG template. With these features, builders can create RAG-powered chatbots like the solution described in this blog.
AI-powered search innovations
As our users increasingly build AI features into their OpenSearch applications, we’ve observed their pain around managing and integrating Machine Learning (ML) models with OpenSearch—such as having to build custom middleware to mediate communication between ML models and OpenSearch. For example, when you build a semantic search application on an OpenSearch k-NN index, you have to integrate text embeddings, a type of ML model, into your ingest pipelines to encode your text corpus into vectors. Then, you have to implement middleware to integrate ML models to help translate natural language queries like “what is OpenSearch” into a vector query to perform a vector similarity search. Moreover, to keep pace with AI innovations, your application has to adapt to frequent change as you re-evaluate and re-integrate new AI technologies.
Frameworks like LangChain have helped builders alleviate some of these challenges, but we still see an opportunity for complementary features that deliver further simplification. OpenSearch builders often have basic requirements—they simply want to infuse vector search into their OpenSearch-powered applications. For instance, their application doesn’t need to dynamically retrieve information from multiple data stores within sophisticated workflows that interact with a variety of services—often required by generative agents that drive automations. Thus, we launched neural search and the ML framework for OpenSearch to simplify the AI application building experience.
Neural search
Generally available since OpenSearch 2.9, neural search enables builders to create semantic search applications by running human language queries instead of vector-based ones. You can run semantic search pipelines on-cluster instead of on custom middleware. These pipelines are integrated with ML models that are hosted on-cluster or externally managed by providers like Cohere, OpenAI, Amazon Bedrock and Amazon SageMaker.
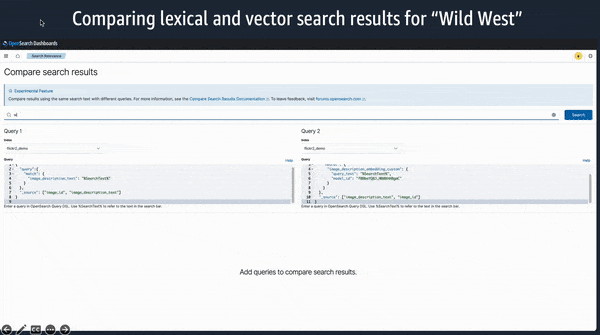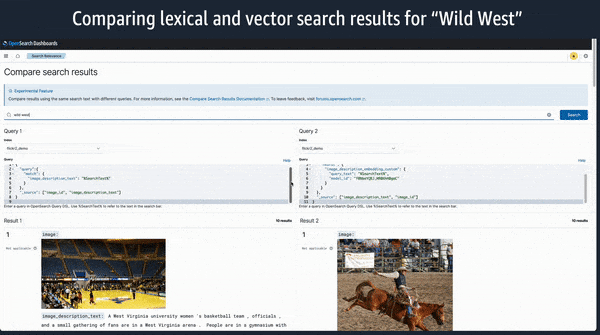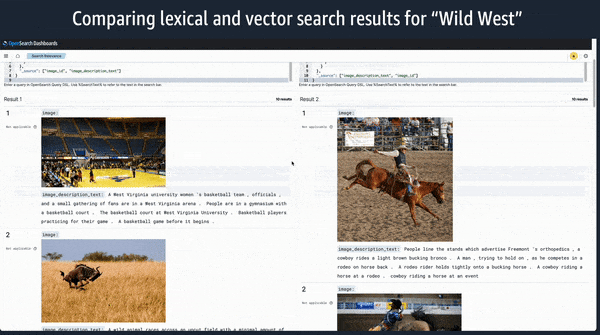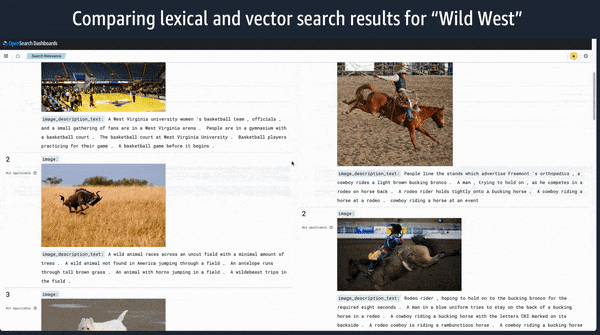
Machine learning framework
The ML models that power neural search are integrated and managed by OpenSearch’s ML framework. Integrated models share a unified API whether they run on-cluster or externally. This enables you to manage the model registration to deployment lifecycle such as versioning models, facilitating model search and discovery, configuring resource-level access controls, and more.
In addition to the first wave of AI connectors, we’ve created an extensible ML framework. We want to empower contributors to create OpenSearch AI integrations with minimal effort with much to gain from joining our open community. As a technology integrator, you can simply define JSON-based blueprints that describe a secure RESTful protocol between OpenSearch and your technology. You can then use these blueprints to provision connectors. This approach has enabled us to run third-party integrations like the Cohere Embed connector on the Amazon OpenSearch Service (AOS) without delay. It has enabled Cohere to author new versions of their connector so customers can immediately use it on AOS without dependencies on our release schedule. Historically, this has been challenging to accomplish on managed services due to security and business risks. Partners can now benefit from a fast path from open source to commercial offerings.
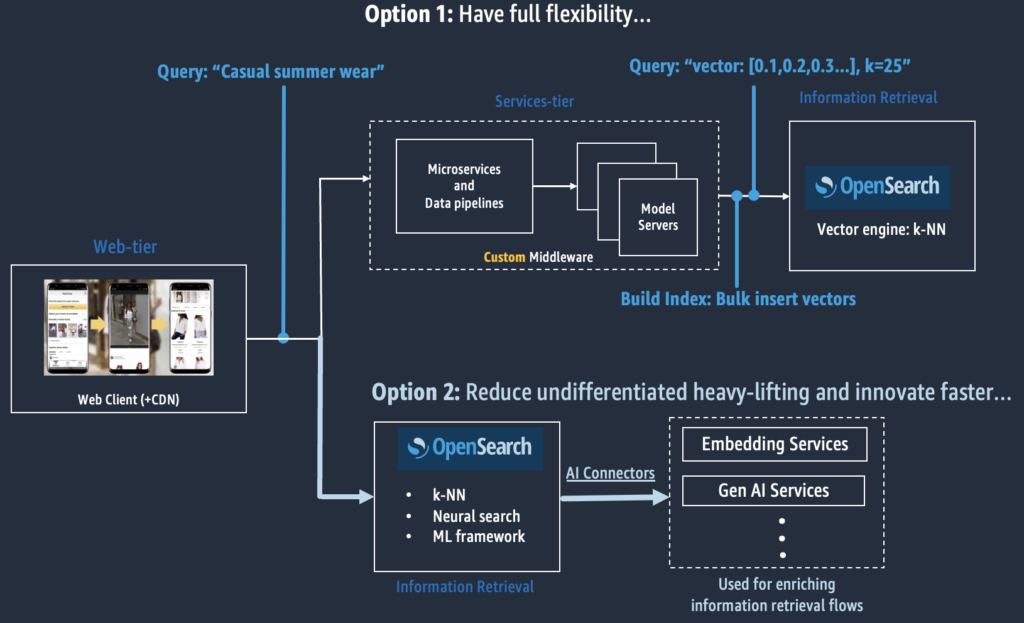
Use case support for neural search and ML framework
Initially, neural search only supported embeddings-based semantic search. It provided out-of-the-box pipelines that use integrations with text embedding models that can encode a text corpus into vectors. These vectors are encoded such that k-nearest-neighbor (vector) search can be used to retrieve documents based on semantic similarity. In OpenSearch 2.10, we added enhancements to simplify hybrid search, making it easier for you to blend normalized lexical and vector scores to improve search relevancy.
In 2.11, we introduced numerous features including support for neural sparse encoding based semantic search. This method uses a sparse encoder model that’s designed to encode a text corpus into “sparse” vectors—a collection of weighted terms. Like text embedding models, the encoder captures semantic meaning. However, since documents are encoded into weighted terms, an inverted index can be used. Thus, you can benefit from a smaller index footprint. Neural sparse search also provides two query methods. First, natural language queries are supported and are designed for high search relevancy performance—recall. However, these queries incur higher-latency because the large sparse encoder model has to be invoked to process a query. Alternatively, you can use keyword-type queries, which don’t require invoking the sparse encoder at query time. Thus, these queries run with low-latency, but they have lower recall compared to their high-latency counterpart.
Beyond text-based search, we added support for text and image multimodal search, which enables you to find images using combinations of text and visual inputs. Unlike traditional image search, which searches on image metadata, multimodal search allows users to describe the visual characteristics like “shirt with abstract pattern” without requiring manual labor to produce high-quality and granular metadata for images. You can also find visually similar images by searching on an image—an ideal approach when visual characteristics like stylistic patterns can’t be easily articulated. Lastly, you can query using a combination of text and image. For instance, you maybe looking for a similar variation of a blue shirt—a reference image—but you want it with “desert colors and long sleeves”.

Lastly, conversational search, a contribution from Aryn.ai, was released as an experimental feature. Conversational search transforms OpenSearch’s lexical, vector, and hybrid search features into conversational experiences without requiring custom middleware. It enables search through a series of interactions like “what is OpenSearch” and “how do I use it with GenAI.” It includes a RAG search pipeline that uses AI connectors to send information to generative LLMs like ChatGPT and Claude2. The RAG pipeline processes a query by retrieving knowledge articles from your indexes and sends them to a generative LLM to generate a conversational response. This method grounds the generative LLM on facts to minimize hallucinations, which can cause unintended misinformation. Conversation history is also tracked and included in the request context to generative LLMs, providing them with long-term memory for ongoing conversations.
What’s next for OpenSearch AI/ML in 2024?
Our roadmap will continue to be driven by our customers and community. Since there’s no sign of slowing interest in where search meets AI/ML, we plan to continually iterate on what we’ve delivered in the past year. Furthermore, expect more AI-powered features in our domain applications like the OpenSearch Assistant and Anomaly Detection for Observability.
Vector search engine roadmap
Our vector search engine will continue to be a priority. Firstly, we will continue delivering price-performance improvements. Our ongoing activities include evaluation of alternative k-NN libraries and algorithms. We’re looking for algorithms that add a new dimension—like an edge on cost optimization or ultra-low latency—to our current selection of engines and k-NN index types. Specifically, we’re planning to add a disked-based approximate nearest neighbor search algorithm as we’ve observed a good trade-off between cost and latency. We’ve also observed opportunities to improve query latency, index build times, and price performance using hardware accelerated algorithms beyond our current SIMD support. At last, we’re exploring caching techniques specialized for vector search workloads to bolster general vector query performance.
Aforementioned, we’re slated to add vector quantization support for FAISS in 2.12. We want to invest more in compression techniques because memory consumption is often the main cost driver for vector search deployments. Thus, we’re planning on improving our current product quantization support in terms of stability, configurability and ease-of-use.
We will continue to enhance query capabilities, which includes plans for out-of-the-box vector search on long documents. Language models have limits on how much text they can accept as input. Consequently, long documents have to be chunked and indexed as multiple vectors—vector chunks. Today, customers implement customizations to generate vector chunks and reassemble them at query time to retrieve long documents. We plan to provide the functionality to transparently chunk documents and query them as whole documents to simplify the developer experience.
As our query capabilities become increasingly sophisticated, builders have asked for a better understanding of query results. We plan to roll out improvements in phases. First, we’ll enhance our explain API to provide detailed visibility into hybrid query execution plans. Next, we will provide basic facilitators to help you interpret vector scoring results. For instance, we’ll make it easier for you to generate document summaries and key entities alongside encoded documents so you can easily examine vector search results. Eventually, we aim to integrate explainable AI capabilities into our search experiences, so that you have insights into things like word attribution so that you insights into what’s influencing the scores generated by your embeddings.
Lastly, we will continue to contribute to open source projects like LangChain and LlamaIndex as needed to ensure OpenSearch is well supported within our community’s preferred tools.
Ease-of-use with high flexibility
We’ve received positive feedback on the “neural search experience.” Our users like the concept of a simplified query interface, a simplified application architecture, and out-of-the-box workflows and AI integrations. However, users also expect the framework to provide high flexibility. With that said, we’ll continue to improve on the ease of building OpenSearch-powered AI applications, but we’ll aim to minimize flexibility tradeoffs.
In order to provide the flexibility to support the many AI use cases and variations that users are asking for, we’re revamping our framework to enable composable pipelines built on configurable and reusable components. For instance, when you integrate models with OpenSearch, we want you to be able to configure the interfaces, so that you’re not limited to integrating text embedding models. We want to enable users to compose a custom query flow as a series of configurable processors, such as custom models—as a generic ML model processor—that enrich query inputs and results during steps in a flow.
We plan to provide templates for precomposed flows to quick-start builders on popular use cases, but leave them with the flexibility to alter and evolve these flows. These templates will capture the OpenSearch resources and configurations required to provision components like search pipelines and AI connectors to power specific use cases like multimodal search. We aim to simplify the backend plumbing required by AI-enhanced search solutions to uplift ease-of-use with minimal flexibility trade-offs.
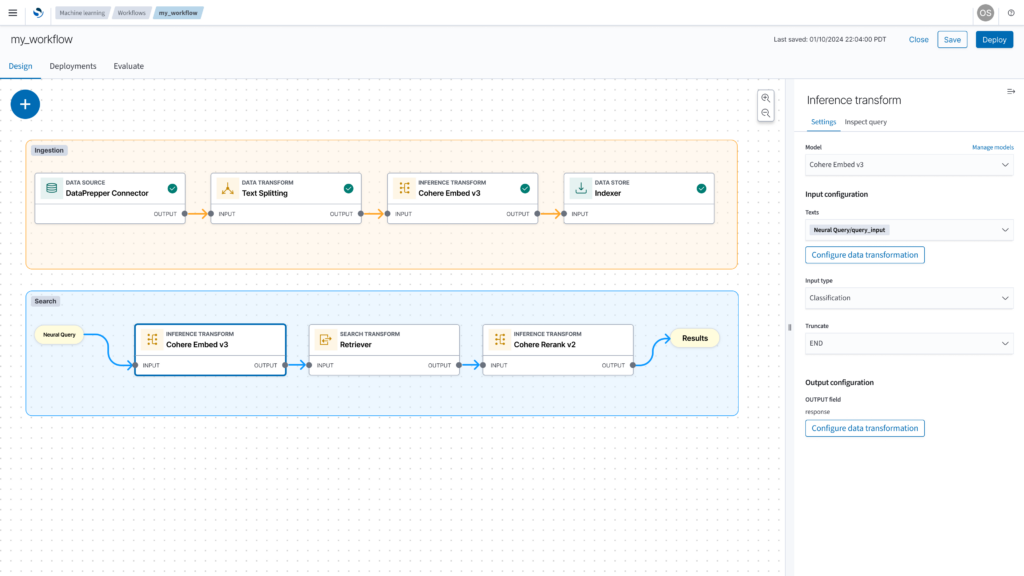
New AI use case support
With the composable flow paradigm, we envision supporting the existing use cases, variations and a plethora of new possibilities. Among the possible use cases will be the ability to construct re-ranking workflows. You will be able to compose a workflow that can retrieve results through lexical or vector methods and efficiently send those results to a re-ranking model, which might be a custom model or a provider like Cohere ReRank. These workflows will unlock various use cases, including search relevancy boosting through state-of-the-art techniques like combining bi-encoder and cross-encoder models and user-level personalization by re-ranking results using deep recommender models.
As well, the ability to use the generic ML processor within last-mile ingestion pipelines, will unlock countless use cases based around automating metadata extraction to enrich indexes. We plan to provide you with an ingest processor that allows you to configure your model interface, so that you can more easily integrate models ranging from name-entity-recognition models, computer vision classifiers, sentiment detectors to neural machine translators to enrich your data during ingestion and indexing flows.
Machine learning framework enhancements
ML extensibility enhancements
We created an extensible ML Framework for OpenSearch that enables technology providers to integrate AI technologies without having to write code. In our first release, we built connectors to Amazon SageMaker and Amazon Bedrock, and we partnered with Cohere who authored a blueprint for their Embed API. These connectors provide you with choice on how you manage models and power neural search. We’re delighted to have a steady contribution of community AI connectors since our launch on OpenSearch 2.9.
{
"name": "cohere-embed-v3",
"description": "The connector to public Cohere model service for embed",
"version": "1",
"protocol": "http",
"credential": {
"cohere_key": "<Your_API_Key>"
},
"parameters": {
"model": "embed-english-v3.0",
"input_type":"search_document",
"truncate": "END"
},
"actions": [
{
"action_type": "predict",
"method": "POST",
"url": "https://api.cohere.ai/v1/embed",
"headers": {
"Authorization": "Bearer ${credential.cohere_key}"
},
"request_body": "{ \"texts\": ${parameters.texts}, \"truncate\": \"${parameters.truncate}\", \"model\": \"${parameters.model}\", \"input_type\": \"${parameters.input_type}\" }",
"pre_process_function": "connector.pre_process.cohere.embedding",
"post_process_function": "connector.post_process.cohere.embedding"
}
]
}
Blueprint for provisioning Cohere Embed V3 Connectors to power Neural Search
In the fullness of time, we envision a framework that integrates with AI services to deliver functionality beyond inference, like model training and deployment. We envision having OpenSearch tightly integrated into ML lifecycles, seamlessly interoperating with incumbent ML technologies. We want to facilitate end-to-end automation and to continuously improve models to elevate search relevance and predictive insights.
Batch optimized inference
Among the things we plan to enhance next year is augmenting our framework so that our AI connectors have the ability to integrate with batch optimized APIs and services. We want you to be be able to easily enrich your ingest pipelines with a variety of ML models to generate vector embeddings and metadata. These types of ingest pipelines are typically best ran as a batch process, so we want you to have access to a variety of connectors that can deliver optimal price performance on batch workloads. All the while, we want you to have flexibility and the freedom to choose your preferred tooling.
Certified AI connectors
Additionally, we plan to implement a process for certifying connectors to maintain a quality standard for our users. We plan to elevate certified connectors by making them more accessible, for instance, by including them in our distributions by default.
Connector authors that acquire certification will qualify for additional benefits. For instance, they could qualify for publishing their connectors in the Amazon OpenSearch Services integration catalog, which enable AWS customers to automate infrastructure and OpenSearch resource creation to install connectors on managed clusters. Currently, to install a connector, you have to copy connector blueprints from our documentation. Then, you have to manually create OpenSearch and AWS resources like OpenSearch model abstractions and IAM policies. These automations make it easier for customers to use our AI integrations, and certified connector authors will have privileged access to mechanisms that facilitate go-to-market objectives.
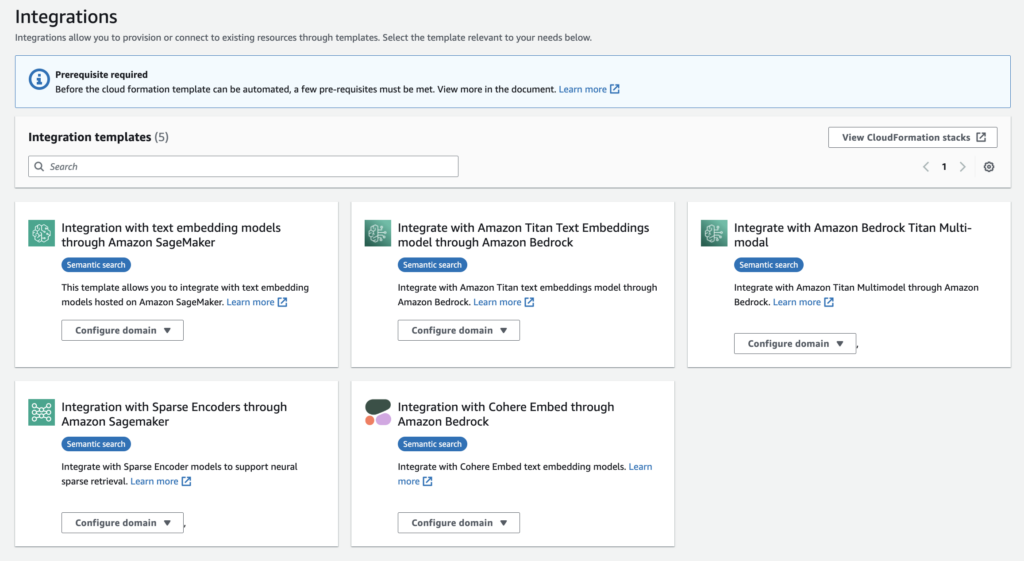
Model management
The initial release of our framework included a UI for administrators to monitor the responsiveness of ML models helping maintain the quality of AI-enhanced queries and troubleshoot ML workloads.
Next, we aim to help developers, data scientists, and MLOps engineers to more easily manage integrated models by providing a model registry UI within OpenSearch Dashboards. The dashboards will enable users to register and deploy models that are hosted on-cluster or externally. Teams will be provided with controls to easily share, secure, and discover available ML models while governing model deployment processes, versioning, and more.
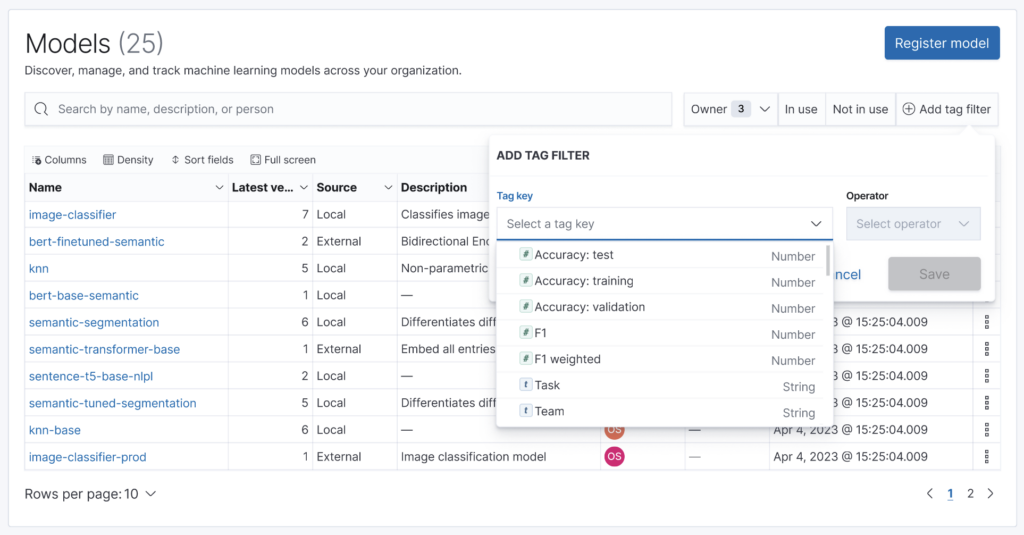
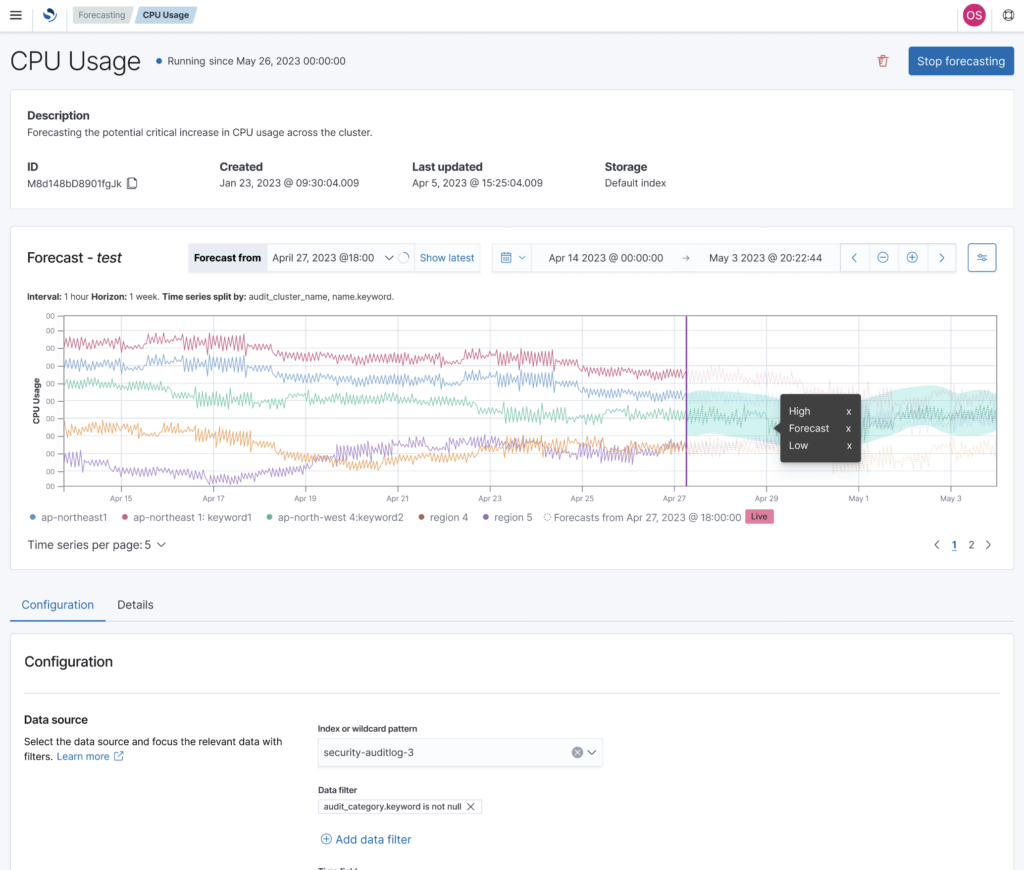
Forecasting
Lastly, in the similar vein as our Anomaly Detection capabilities, we want to provide non-ML experts with the ability to generate forecasts on their OpenSearch managed data. For instance, we want to enable operations teams with proactive monitoring, so that they can automatically detect trends over a sea of time-series metrics. We want to empower them to proactively prevent issues by providing visibility into resource over-utilization forecasts. Within OpenSearch Dashboards, non ML-experts will be able to configure forecasters that continually train and generate forecasts on configured OpenSearch data sources.
Shape the future of OpenSearch AI and machine learning
We hope you’re excited about what’s to come for OpenSearch AI and Machine Learning in 2024. As always, we’re interested in your feedback about our roadmap. You can share your thoughts with us in the forum, or through our community feature request forms to help us prioritize our efforts.
Additionally, if you like to learn more about the 2023 AI/ML features that were highlighted in this blog, the following are some technical blog posts that we published on these topics:
- Using and building OpenSearch AI connectors
- Efficient filtering for vector search
- Byte-quantized vectors in OpenSearch
- Improve search relevance with hybrid search, generally available in OpenSearch 2.10
- Improving document retrieval with sparse semantic encoders





