

Traditional databases often struggle with unstructured data, making it hard to efficiently store, index, and search today’s increasingly complex datasets. OpenSearch Vector Engine is designed for complex data, enabling fast similarity searches using techniques like k-nearest neighbors so models can quickly retrieve relevant information. Whether you’re building recommendation systems, detecting anomalies, or processing natural language, OpenSearch Vector Engine scales effortlessly with large, unstructured datasets, ensuring high performance in real-time AI applications.
Store, index, and search high-dimensional data
Integrate and enhance existing learning models by storing and retrieving model embeddings

Cluster and classify for similarity-based data point groupings
See what you can accomplish with OpenSearch vector engine.
Fast, efficient search across unstructured data
OpenSearch Vector Engine is optimized for storing vector embeddings—numerical representations that capture key features and meaning of unstructured data like text, images, and sound. AI systems compare these vectors to find similarities across various data types, allowing for context-aware searches based on content similarity rather than exact keyword matches.
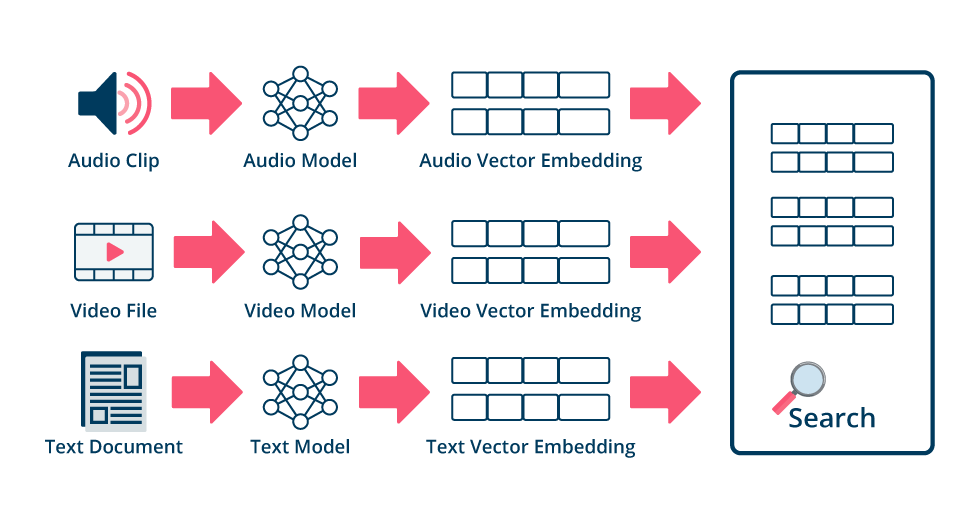
Accelerate your search apps with a highly versatile vector database built for speed and scale

Powerful vector database platform for AI apps
Store and search embeddings alongside your traditional data for seamless semantic search, RAG, recommendations, and more.

Search and analytics in one unified suite
Highly scalable and extensible open-source vector database platform for search, analytics, observability, and other data-intensive applications.

Develop AI/ML solutions quickly
From vector search to chatbots and agents, OpenSearch Vector Engine accelerates development for a wide array of AI/ML use cases.

Diverse range of AI search methods
Develop semantic, hybrid, multimodal, neural sparse search, and conversation search with RAG apps—all using one vector database platform.

Real time data ingestion and indexing
Continuously collect and index data from multiple sources, leveraging built-in data quality tools to ensure your predictive models remain accurate and up to date.
GPU-accelerated vector search
Accelerate vector search at scale with GPU-powered indexing in OpenSearch, cutting build times and costs while delivering superior performance for large-scale vector workloads.
Explore further resources
OpenSearch Blog
Generative AI: OpenSearch’s journey as an open-source search engine
Wed, Mar 26, 2025
OpenSearch Blog
GPU-accelerated vector search in OpenSearch: A new frontier
Tue, Mar 18, 2025
OpenSearch Blog
Reduce costs with disk-based vector search
Wed, Feb 19, 2025
OpenSearch Blog
Introducing reciprocal rank fusion for hybrid search
Wed, Feb 12, 2025
OpenSearch Blog
Zero to RAG: A quick OpenSearch vector database and DeepSeek integration guide
Thu, Jan 30, 2025
Everything you need to set up vector search in one platform.
OpenSearch Vector Engine dramatically shortens the time to market of your AI app, and allows you to scale on demand.
Integrations with leading LLMs
Popular large language model (LLM) frameworks integrate with OpenSearch Vector Engine as a vector store, enabling you to build production-ready generative AI applications.
Create and manage ingest pipelines
Easily create data pipelines for ingesting, filtering, transforming, and enriching data as they are ingested into an index.
Query DSL
OpenSearch’s Query domain-specific language provides a flexible language with a JSON interface for searching your data.
Designed for AI/ML
Native support for semantic search with vector embeddings, multi-modal search, hybrid search with score normalization, and sparse vector search.
Getting started guide
Learn how to begin using OpenSearch as a vector database in this 10-minute introduction video.
Read the guide
