

Storage is a key factor driving the infrastructure cost of your OpenSearch cluster. As your data grows, storage requirements can increase multifold, depending on whether OpenSearch stores documents in multiple formats. This is where derived source comes to the rescue, optimizing storage costs.
In this blog post, we will describe how documents are stored in OpenSearch and how to use derived source to retrieve those documents in a cost-effective manner.
How are documents stored in OpenSearch?
When documents are ingested, OpenSearch stores the original document body in the _source field. Additionally, the document’s fields are stored in various formats, such as indexed, stored, and doc values, as shown in the following image.
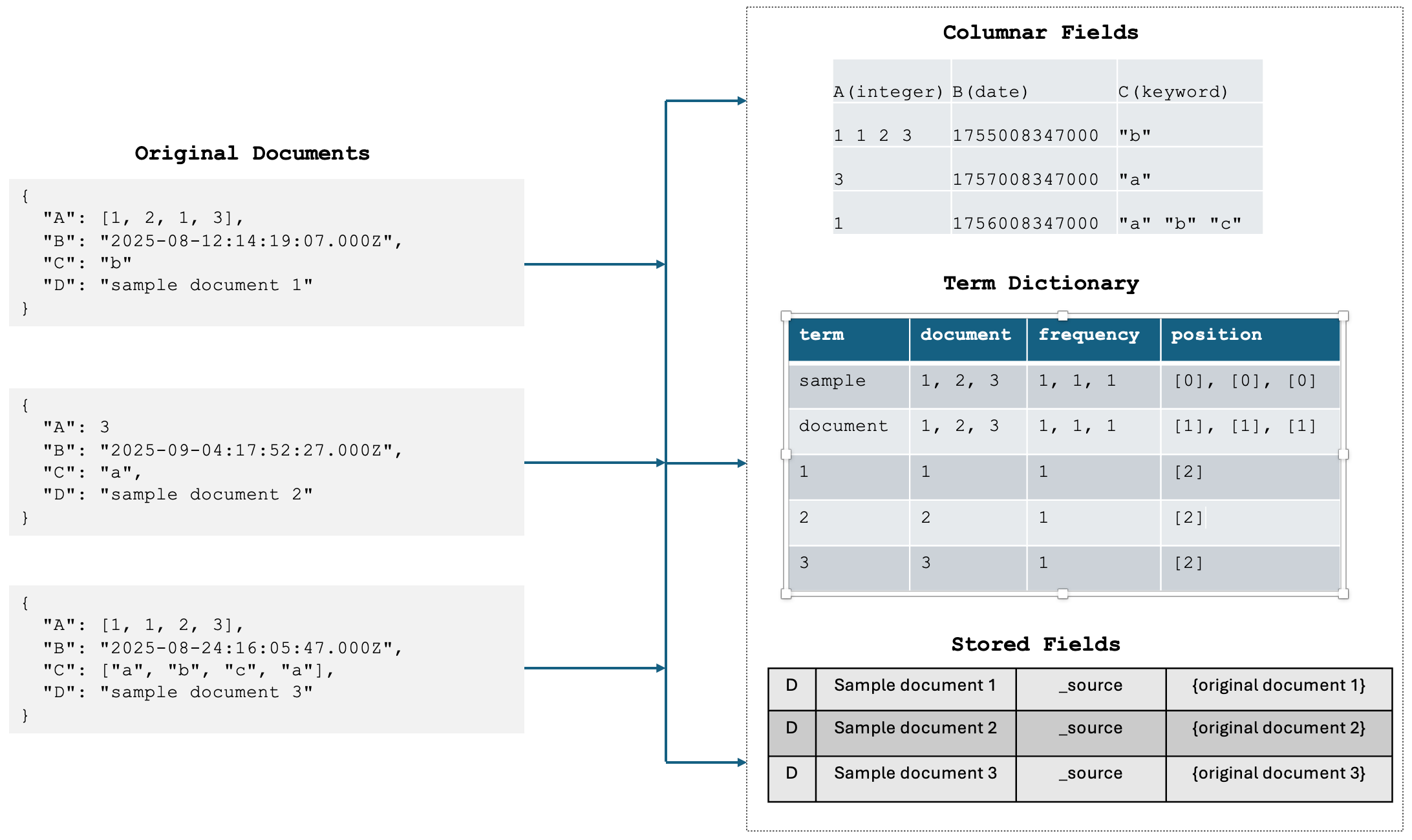 OpenSearch stores data in different formats because each field type requires values to be stored in a specific form for optimized search. For example, full-text search relies on an inverted index, whereas exact term aggregations on keyword fields rely on doc values. Because the original document is stored in a separate data structure comprising all the fields in a single location, it becomes easy to retrieve in the fetch phase. This setup reduces search latency at the expense of storage costs because of data duplication.
OpenSearch stores data in different formats because each field type requires values to be stored in a specific form for optimized search. For example, full-text search relies on an inverted index, whereas exact term aggregations on keyword fields rely on doc values. Because the original document is stored in a separate data structure comprising all the fields in a single location, it becomes easy to retrieve in the fetch phase. This setup reduces search latency at the expense of storage costs because of data duplication.
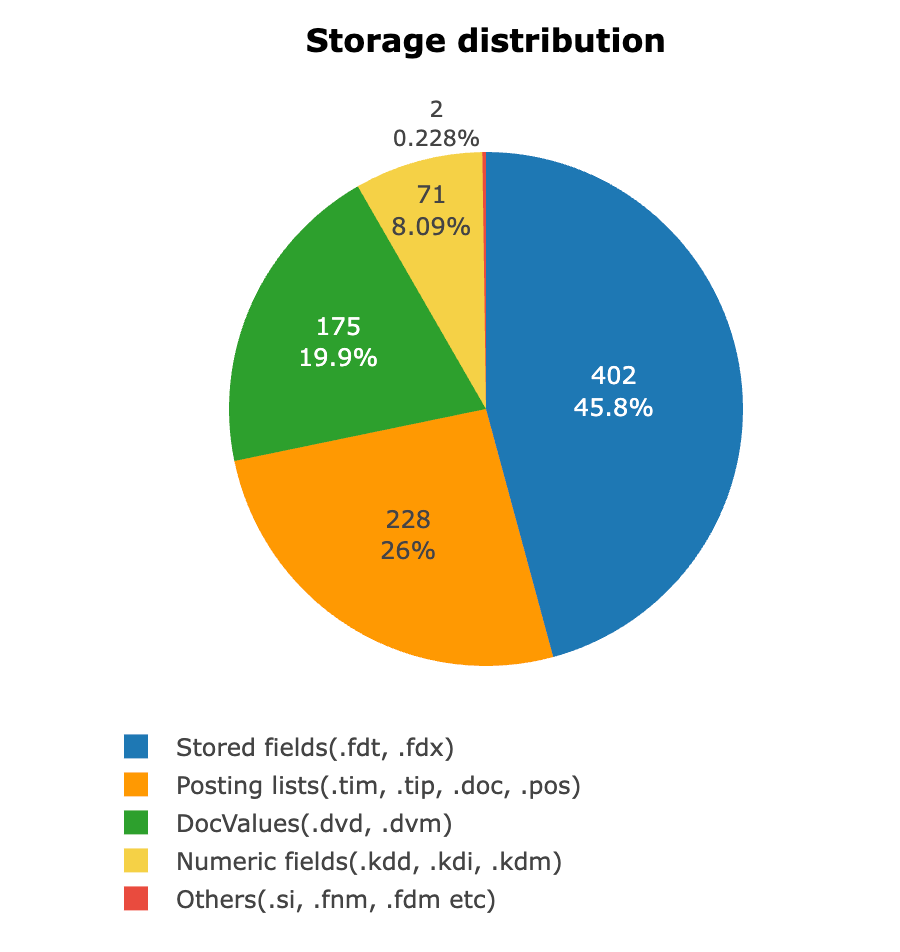
The following image shows the field distribution during an experiment conducted on a test dataset of roughly 1 billion documents stored in a single index.
 How does OpenSearch use the _source field?
How does OpenSearch use the _source field?
The _source field is not just used for document retrieval during search operations but also for operations like updates, reindex operations, scripted updates, and recovery operations. If you disable _source, these operations become unavailable, which prevents data recovery and is therefore not recommended.
OpenSearch 2.9.0 introduced ZSTD compression, offering a high compression ratio at a fast speed. In the same experiment measuring storage footprint, enabling ZSTD compression reduced the stored field size to 216 GB—about a 46% reduction. However, even with this reduction, stored fields still occupy a significant amount of storage.
What is derived source?
If your use case requires aggregations such as min, max, avg, sum, or terms but not the matched documents themselves, storing all the data provides diminishing returns because the actual documents are unnecessary—the aggregations alone are sufficient.
Starting with OpenSearch 3.2.0, you can use derived source for such use cases to optimize storage. Derived source mode modifies index behavior to exclude the _source field during ingestion, preventing data duplication and reducing storage requirements. These documents are retrieved dynamically using different forms of field storage (such as doc_values or stored fields) on demand. This approach preserves search functionality and supports operations that rely on _source data—such as reindexing, updates, scripted updates, and recovery—without actually storing the _source field.
With this modified document retrieval behavior, during the fetch phase of a search query, OpenSearch retrieves each field’s value using formats such as doc_values and stored fields, then combines the results to produce the final document, as shown in the following image.
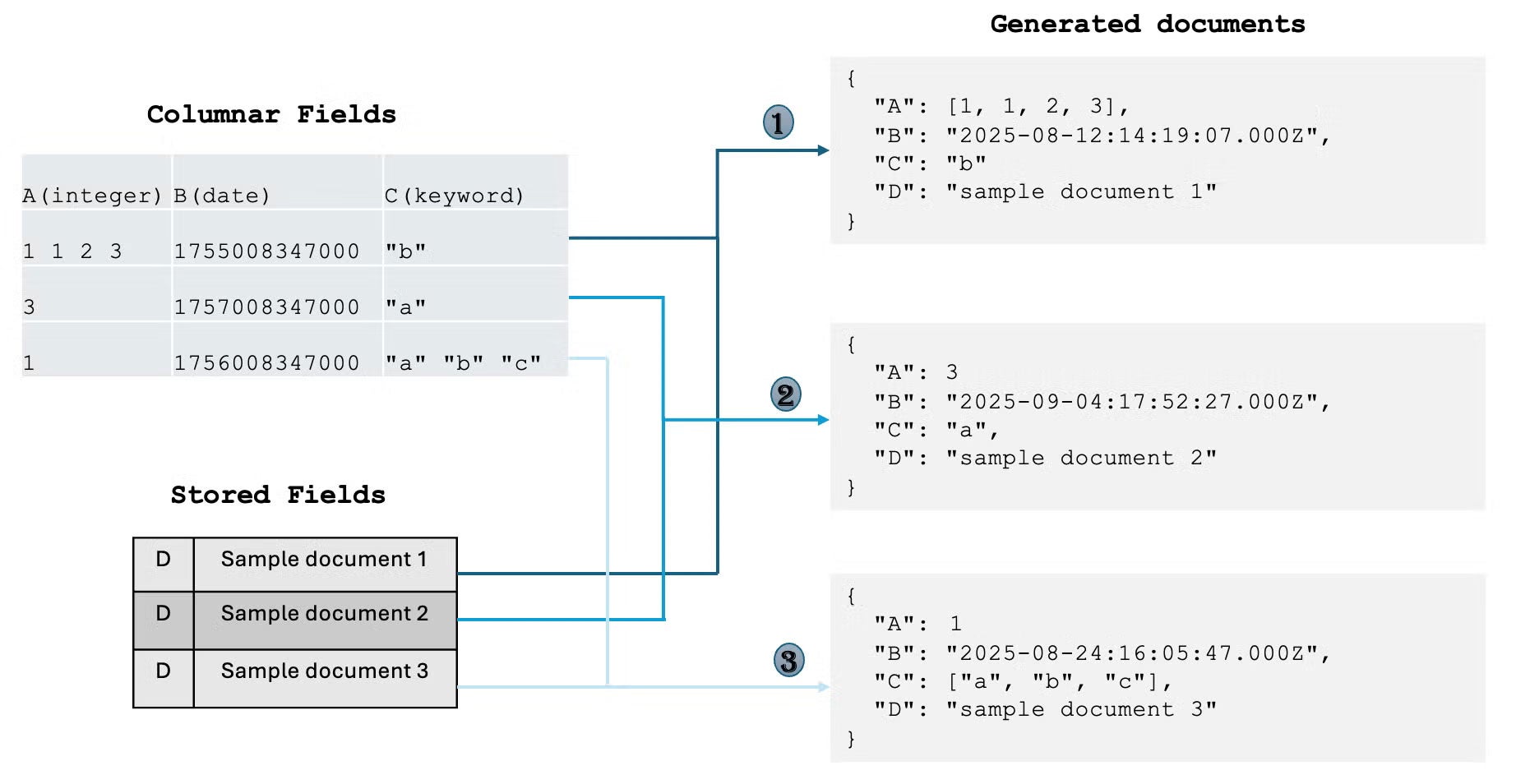 When configuring an index with derived source, OpenSearch validates that all fields are of supported types. When documents are accessed through operations such as search, update, or recovery, the derived source reconstructs each field’s value from either
When configuring an index with derived source, OpenSearch validates that all fields are of supported types. When documents are accessed through operations such as search, update, or recovery, the derived source reconstructs each field’s value from either doc_values or stored fields as defined in the index mapping. Because this requires reading data from each field’s disk location rather than a single _source fetch, you may notice some latency degradation when retrieving large numbers of documents.
How to configure derived source
You can configure derived source at the index level. Because it changes the default behavior of storing the original _source, this setting can’t be updated after the index is created. This restriction prevents mixed behavior between the original stored source and the dynamically generated source (which can appear similar to the original source in output).
To configure derived source, set derived_source.enabled to true in the index settings:
PUT sample-index1 { "settings": { "index": { "derived_source": { "enabled": true } } }, "mappings": { <index fields> } }
For more information, see Derived source.
Performance benchmarks
Based on experiment runs, derived source can provide significant storage reduction for certain workloads, as shown in the following table.
| Workload | Storage reduction |
|---|---|
| nyc_taxis | 41% |
| http logs | 43% |
| elb logs | 58% |
Search latency showed a regression ranging from 10% (for 1K documents in a terms aggregation) to 100% (for 10K documents in a match-all query). In some queries, however, latency improved, since reading from doc_values often avoids the decompression required when accessing the stored _source field.
Across these benchmarks, we observed significant indexing throughput improvements of up to 18%, along with a reduction in merge time ranging from 20% to 48%. This is due to lower CPU overhead when generating optimized segments, which also helps reduce merge overhead.
With a reduced index size, additional benefits become apparent: smaller shards enable faster recovery during node restarts or shard relocations, and smaller segments require less disk I/O and fewer page cache swaps, resulting in more efficient queries.
While file-based recovery remains fast, operation-based recovery can be slower due to the need to regenerate the _source. There are two types of operation-based recovery:
- Lucene based, which is impacted by document replication using derived source.
- Translog based, in which reading the original
_sourceinstead of regenerating it can still take up to twice as long because of how derived source handles documents in the translog.
To avoid the performance impact on translog-based recovery, you can disable derived source for the translog while keeping it enabled for the main index:
PUT sample-index1 { "settings": { "index": { "derived_source": { "enabled": true, "translog": { "enabled": false } } } } }
Limitations
While derived source provides significant storage savings, it imposes certain limitations on how query responses are generated and returned.
Date representation
For a date field with multiple formats specified, derived source uses the first format from the list for all requested documents, regardless of the original ingested value.
Geopoint representation
Geopoint field values can be ingested in multiple formats, but derived source always represents them in the fixed format {"lat": lat_val, "lon": lon_val}. Some precision loss may occur during indexing, and the same degree of precision loss may appear in derived source.
Order and deduplication of multiple value fields
Derived source automatically sorts and, for keyword fields, deduplicates values in multi-value arrays, as shown in the following example:
1. Keyword field a. Ingested source { "keyword": ["b", "c", "a", "c"] } b. Derived source { "keyword": ["a", "b", "c"] } 2. Number field a. Ingested source { "number": [3, 1, 2, 1] } b. Derived source { "number": [1, 1, 2, 3] }
For field-level limitations, see the specific supported field documentation in Supported fields.
What’s next?
While derived source currently supports most commonly used field types, there are some limitations when defining these fields in index mappings. In the future, we plan to remove these limitations in order to make derived source available for more use cases. Our development roadmap also includes expanding support to additional field types, such as range and geoshape fields. Beyond expanding functionality, we’re focusing on performance optimizations to improve document retrieval strategies, which will reduce search latency when requesting large numbers of documents. These combined improvements will make derived source more flexible and performant across a broader range of scenarios.
We encourage you to try out derived source in your applications and share your feedback with us on the OpenSearch forum. Your insights help us prioritize future improvements and ensure we’re building features that meet your needs.
