Since the introduction of hybrid queries in OpenSearch 2.10, they have become increasingly popular among users who want to improve the relevance of their semantic search results. Hybrid queries combine full-text lexical search and semantic search in order to provide better results than either method alone. They are useful for a wide variety of applications, such as e-commerce, document search, log analytics, and data exploration. If you’re unfamiliar with hybrid queries, start by reading our earlier blog post that introduces hybrid search and presents its quality and performance results.
OpenSearch has been continuously enhancing its hybrid query capabilities and performance by introducing features like post-filters, aggregations, and query parallelization. However, when hybrid queries were first introduced, they did not support sorting of search results based on custom sort conditions. In OpenSearch 2.16, we added sorting capability to hybrid queries, allowing applications to sort results by specific fields or attributes. This enhancement provides greater flexibility and improves the relevance and usability of hybrid queries.
In this blog post, we will first review the query execution workflow, then explain how sorting works in hybrid queries, and finally demonstrate how to use this feature.
Query execution workflow
At a high level, query execution is divided into two main phases: query and fetch. During the query phase, OpenSearch retrieves matching results from each shard as objects containing document IDs and relevance scores. These results then move to the fetch phase, in which the full text for each document ID is retrieved from the shards. Finally, OpenSearch combines the results from all shards, generates the final search response, and sends this response to the user. Query processing is discussed in more detail in this blog post.
High-level logic of sorting in a hybrid query
In a typical hybrid query, results are retrieved based on both lexical and semantic relevance scores. The top-scoring documents from each shard are then combined to form the final result, prioritizing relevance over any other sorting criteria.
To enable sorting in this process, subquery results are retrieved according to the specified sort criteria. These sorted subquery results are then merged at the coordinator level, ensuring that the final output follows the user’s requested sort order rather than relying solely on relevance scores.
The following example illustrates the sorting workflow in a hybrid query. In this case, a user triggers a hybrid query with two subqueries, match and term, and requests that the search results be ordered by stock price in descending order.
First, the hybrid query executes the match and term subqueries separately, sorting each result set by the specified criterion—in this case, stock price. Unlike traditional sorting, which disregards relevance scores, hybrid queries include both the relevance score and the sorting fields in the results of the query phase. These values are then used in the normalization process. During normalization, relevance scores are used to calculate normalization scores, which act as tie-breakers when subquery results are combined. Finally, the subquery results are combined at the coordinator level to form the final result, ensuring that the output is sorted by stock price in descending order, as requested.
The following diagram illustrates the query phase workflow and the creation of the final shard result based on sorting criteria.
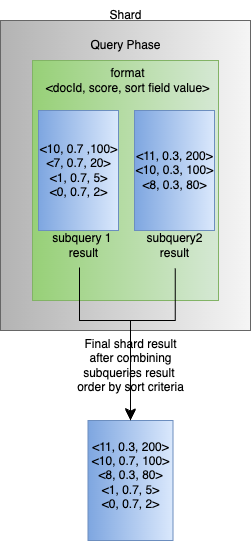
Detailed overview of sorting in a hybrid query
Building on the high-level logic discussed earlier, let’s now dive into the detailed process of sorting in a hybrid query. This can be broken down into two key steps:
- Sorting individual subquery results at the shard level.
- Merging the multiple subquery results based on the sorting criteria at the coordinator node.
The following diagram illustrates these steps in detail.
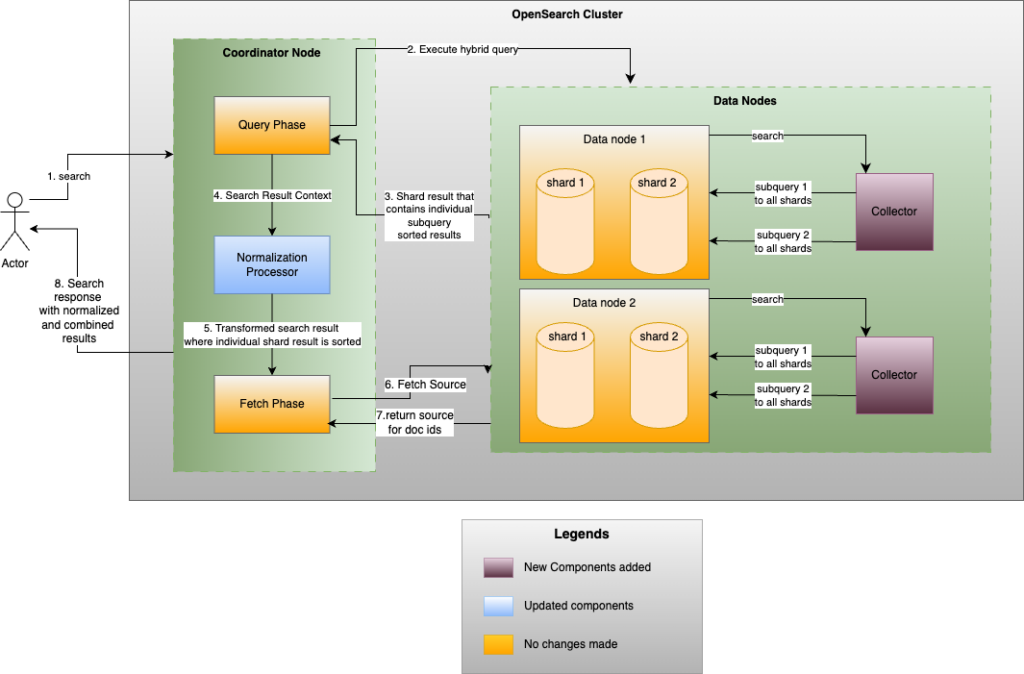
The coordinator node sends requests to data nodes to retrieve query results from each shard. Internally, during the query phase, the following process takes place:
- A collector runs on each shard to gather results for each subquery. As results are collected, they are inserted into a priority queue that is ordered based on the sorting criteria.
- At the end of the query phase, the subquery results are popped from the priority queue in sorted order.
Once the coordinator node receives responses from all the data nodes, the normalization process begins. This process assigns a score to each subquery result and merges it into a final sorted list according to the specified sorting criteria. After normalization, the results move to the fetch phase, in which the document IDs are used to retrieve the full document contents from the shards. The final search response is then sent to the user.
Sorting limitations
Because of the complexity involved in generating search results, the following limitations apply to sorting in hybrid queries:
- Sorting by multiple fields cannot include
_score: You cannot sort by multiple fields if one of the fields is_scorebecause subquery results can only be combined based on either the sort field or_score, but not both. Thus, a query similar to the following will return an error:{ "sort":[ { "foo":{ "order":"desc" } }, { "_score":{ "order":"asc" } ] } - Sorting is incompatible with
track_scores: When you specifytrack_scores=truein the search request, OpenSearch calculates scores during the fetch phase. However, this is impossible in hybrid queries. In a hybrid query, scores are initially calculated during the query phase and then normalized by the normalization processor. Iftrack_scoresis enabled, it triggers a recalculation of scores during sorting, which can produce incorrect results because the recalculated scores won’t reflect the normalization performed earlier in the process.
How to use sorting
To use sorting, add a sort clause to a hybrid query and define the sorting criteria:
GET /my-nlp-index/_search?search_pipeline=nlp-search-pipeline
{
"query":{
"hybrid":{
"queries":[
{
"match": {
"title": "wind"
}
},
{
"knn":{
"location":{
"vector":[5,4],
"k":3
}
}
}
]
}
},
"sort":[
{
"foo":{
"order":"desc"
}
}
]
}
For more information, see Using sorting with a hybrid query.
Wrapping up
In summary, we’ve shown how sorting works in hybrid queries, from sorting individual subquery results to combining them based on your chosen criteria. For more information, see the hybrid search documentation. Stay tuned for upcoming features like explainability and pagination, which will make hybrid queries more flexible and useful.



