
OpenSearch is a distributed, open source search and analytics suite used for a broad set of use cases like real-time application monitoring, log analytics, and website search. And it’s easy to imagine why you might want to query information from OpenSearch in those use cases. But you might not know how those queries actually work. Well, that’s what we’re going to explore in this blog! In particular, we’re going to take a closer look at how a query works by following a query through OpenSearch.
High-level concepts
In order to understand how a query works, you’ll need a high-level understanding of OpenSearch itself. To start, OpenSearch is document oriented; meaning the most basic unit for OpenSearch is a document. Rather than information stored as rows and columns as you see in tabular data, OpenSearch stores data as JSON documents. By default, documents added to an OpenSearch store are indexed. Indices are logical partitions of documents and the largest unit of data in OpenSearch. To index these documents, OpenSearch leverages the Apache Lucene search library which uses an inverted index (Wikipedia). An inverted index is a data structure that stores mappings of content to the location in a document (or set of documents). Rather than search each document and text directly, OpenSearch searches the index/indices allowing it to achieve it’s fast search responses.
A node is an instance of OpenSearch and a cluster is a collection of one or more OpenSearch nodes with the same cluster name. There are several different types of OpenSearch nodes that we can discuss in future blog posts (stay tuned), but at a high-level OpenSearch functionality is built off the distribution of tasks and work among all the nodes in a cluster. OpenSearch allows for indices to be subdivided into multiple shards and each shard is part of the OpenSearch index. You can copy those index shards as replica shards (or just replicas) which serve as redundant copies of data, increasing both resiliency and capacity for read requests.
A Query’s Journey
Now that we have reviewed OpenSearch components, let’s follow a query through OpenSearch. At a very high-level, a OpenSearch query can be broken down into two major phases; the query phase and the fetch phase.
Query Phase
In this phase, the query provided to OpenSearch is broadcasted to a copy of every shard across the entire index. Once received, the query is executed locally. The result is a priority queue of matching, sorted documents for each shard. This priority queue is simply a sorted list of the top n matching documents with top being determined by relevance and n being determined by pagination parameters set by the user (or the default if not set by the user). Relevance in this case is a score of how well each document it matches the query. The individual shards are responsible for the actual matching process as well as the scoring. So for example, if you have a three node cluster and wanted to search for “Hamster”, you could write a query like this;
curl -X GET "localhost:9200/_search?q=Hamster&pretty"
Once OpenSearch has your query, OpenSearch takes the following steps;
- The API or client sends your search query to Node 1.
- Node 1 sends the search request to a primary or replica shard for each shard in an index.
- Each shard executes the search locally and creates a locally sorted queue.
- Each shard returns doc ID and sort value of the all the documents in its local queue.
- Node 1 as the coordinator node, merges these values into a globally sorted list.
Figure 1: Query Phase
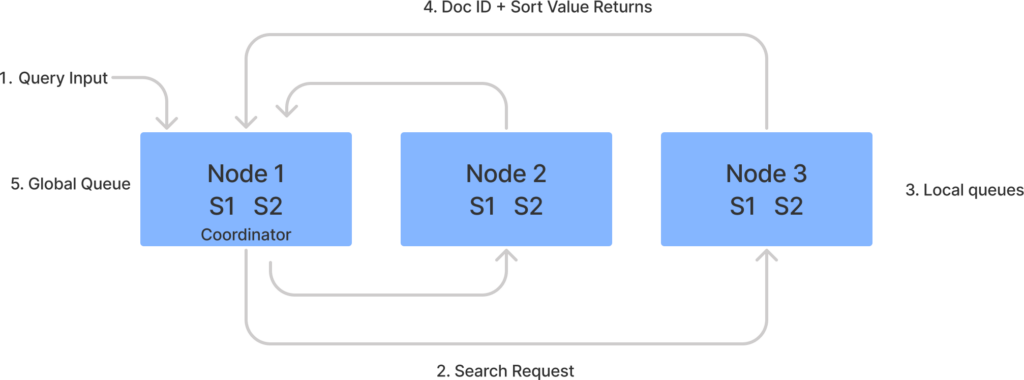
Note on coordinating nodes: Once OpenSearch learns about the query, the query can be sent to any available data node and that node can become the coordinating node for that query. These nodes delegate client requests to the shards on the data nodes, collects and aggregates the results into one final result, and sends this result back to the client. Often larger clusters will have dedicated coordinating nodes that manage search volume.
Fetch Phase
Now that the query phase has identified the documents that satisfy the request, OpenSearch needs to actually retrieve the documents. For the fetch phase, the coordinating node used the globally sorted priority list generated in the query phase to build the GET requests needed for the query. Using the same three node cluster as the earlier example, OpenSearch needs to collect all the results for your query (i.e. “Hamster”) and return them to you.
- The coordinating node uses the global list to identify which documents are needed.
- The coordinating node issues multiple GET requests to the relevant shards.
- Each individual shard loads the request document and returns them to the coordinating node.
- Once all the documents are returned, the results are returned to the client.
Figure 2: Fetch Phase
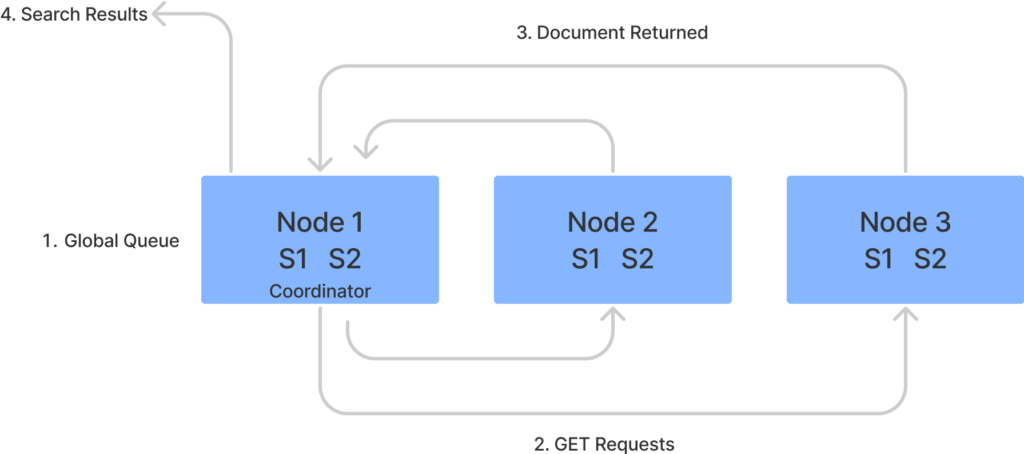
With the results returned, OpenSearch has completed the query!
Conclusion
And there you go, you now have a basic understanding of how an OpenSearch query works! What’s next? Well, we are planning two additional posts to bring your conceptional understanding to the next level;
- A Deeper Look at Queries: A look at how query scoring, routing, and balancing work.
- So you want to write an OpenSearch query: An overview of query basics such as Boolean Operators, Ranges Queries, Fields, Fuzzy Queries, and Wildcards.
If you’re interested in contributing please reach out on GitHub issues or the community forum. The more formal contribution guidelines are documented in the contributing guide.
Sources
- https://opensearch.org/docs/opensearch/index-data/
- https://opensearch.org/docs/opensearch/cluster/
- https://opensearch.org/docs/opensearch/ux/

