This blog has been updated for technical accuracy on 17 Nov 2022.
The roadmap for Data Prepper is publicly available. Data Prepper is a component of the OpenSearch Project that accepts, filters, transforms, enriches, and routes data at scale. It is a key component of the trace analytics feature, which helps developers use distributed trace data to find and fix performance problems in distributed applications. The roadmap outlines a plan to enable Data Prepper to ingest logs and metrics from telemetry data collection agents, such as Fluent Bit and the Open Telemetry Collector. Data Prepper is the single data ingestion component for log and trace data pipelines that can scale to handle stateful processing of complex events such as trace data, aggregation transforms, and log-to-metric calculations.
Data Prepper Overview
Data Prepper is a data ingestion component of the OpenSearch Project that pre-processes documents before storing and indexing in OpenSearch. To pre-process documents, Data Prepper allows you to configure a pipeline that specifies a source, buffers, a series of processors, and sinks (Figure 1). Once you have configured a data pipeline, Data Prepper takes care of managing source, sink, and buffer properties and maintaining state across all instances of Data Prepper on which the pipelines are configured. A single instance of Data Prepper can have one or more configured pipelines. A pipeline definition requires at least a source and sink attribute to be configured and uses the default buffer and no processor if they are not configured.
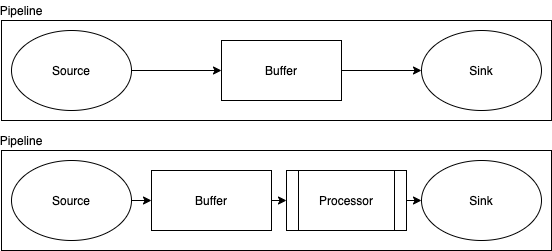
Figure 1: Data Prepper pipelines and attributes
- Source is the pipeline’s input component. It defines the mechanism through which a pipeline will consume records. The source component could consume records either by receiving over HTTP/HTTPS or reading from external endpoints like Fluent Bit, Beats, OpenTelemetry collectors, Kafka, Amazon SQS, and Amazon CloudWatch.
- Buffer is a temporary store of data and can be either in-memory or disk based. The default buffer will be an in-memory queue and is the only option available in the initial release.
- Sink is the pipeline’s output component. It defines one or more destinations to which a pipeline will publish the records. A sink destination can be services like OpenSearch, Amazon S3, or another pipeline. By using another pipeline as the sink, customers can chain multiple Data Prepper pipelines.
- Processors are intermediary processing units that filter, transform, and enrich the records into the desired format before publishing to the sink. The processor is an optional component of the pipeline, and if not defined, the records will be published in the format as defined in the source. You can have more than one processor, and they are executed in the order they are defined in the pipeline specification. For example, a pipeline might have one processor that removes a field from the document, followed by another processor that renames a field.
Data Prepper supports trace analytics data processing, as shown in Figure 2, and includes support for OpenTelemetry collector as a source, a raw-trace processor for trace data processing, and a service-map processor for service map creation.
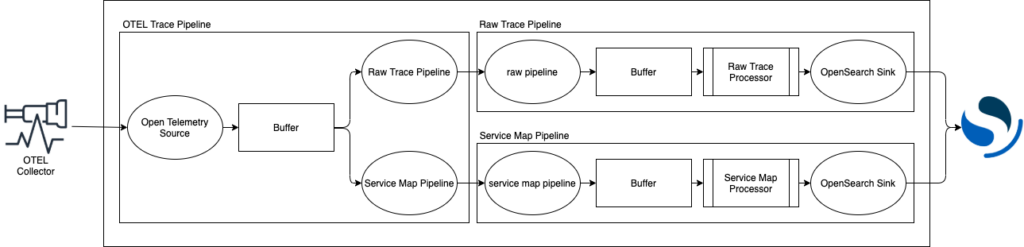
Figure 2: Trace analytics data processing pipeline
Roadmap
The roadmap for Data Prepper is published in the Data Prepper OpenSearch Project repository on GitHub. It gives you visibility on plans for new features, enhancements, and bug fixes, and we look forward to your feedback on it. In late 2021, the focus is on log collection from multiple sources through Data Prepper where they can be ingested, viewed, and analyzed in OpenSearch Dashboards. The Data Prepper 1.2 release provides users the ability to send logs from Fluent Bit to OpenSearch or Amazon OpenSearch Service and use Grok to enhance the logs. These logs can then be correlated to traces coming from the OTEL Collectors to further enhance deep diving into your service problems using OpenSearch Dashboards. Below are the key features that we are targeting for the Data Prepper 1.2 release:
- HTTP Source Plugin (support for Fluent Bit)
- Grok processor
- Logstash template support for Grok
- Sample code and tutorials on creating processors
If you want to add something that is not in the public roadmap for OpenSearch Data Prepper, that’s a perfect opportunity to contribute! We are looking for contributors to help develop new processors and new source plugins and accelerate development of processors and source plugins on the roadmap. This public roadmap follows the same principles in the blog post outlining the OpenSearch public roadmap. It is worth emphasizing a few points:
- Date and milestones reflect intentions rather than firm commitments. Dates may change as anyone learns more or encounters unexpected issues. The roadmap will help make changes more transparent so that anyone can plan around them accordingly.
- You can create a feature request in the relevant GitHub repo for the feature and socialize the request. A maintainer or someone else in the community may pick up this feature and work on it. As progress is made, the maintainers will help get the feature onto the roadmap.
- You can build a feature yourself. To do this create a proposal as a GitHub issue in the relevant repo and use the feature request. Offer your commitment to build it. The maintainers will work with you to figure out how best to proceed. See OpenSearch FAQ 1.19 for more details.
- Would you like to contribute? Maybe you don’t know where to start. The Data Prepper maintainers curate good first issues. These are issues that we believe new contributors could take on. Please comment on the issue if you would like to work on it.
Learn more about Data Prepper by accessing the code, examples, and documentation in the Data Prepper GitHub repository. You also can connect with us and provide feedback in our forum category.