Neural sparse search is a new, efficient method of semantic retrieval introduced in OpenSearch 2.11. Like dense semantic matching, neural sparse search interprets queries using semantic techniques, allowing it to handle terms that traditional lexical search might not understand. While dense semantic models excel at finding semantically similar results, they sometimes miss specific terms, particularly exact matches. Neural sparse search addresses this by introducing sparse representations, which capture both semantic similarities and specific terms. This dual capability enables better explanation and presentation of results through text matching by overcoming the limitations of purely semantic matching and offering a more comprehensive retrieval solution.
Neural sparse search first expands text (either a query or a document) into a larger set of terms, each weighted by its semantic relevance. It then uses Lucene’s efficient term vector computation to identify the highest-scoring results. This approach leads to reduced index and memory costs as well as lower computational expenses. For example, while dense encoding using k-NN retrieval increases RAM costs by 7.9% at search time, neural sparse search uses a native Lucene index, avoiding any increase in RAM cost at search time. Moreover, neural sparse search leads to a much smaller index size compared to dense encoding. A document-only model generates an index that is only 10.4% the size of a dense encoding index, and for a bi-encoder, the index size is 7.2% of a dense encoding index.
Given these advantages, we’ve continued to refine neural sparse retrieval to make it even more efficient. OpenSearch 2.15 introduced a new feature: the two-phase search pipeline. This pipeline splits the neural sparse query terms into two categories: high-scoring tokens that are more relevant to the search and low-scoring tokens that are less relevant. Initially, the algorithm selects documents using the high-scoring tokens and then recalculates the score for those documents by including both high- and low-scoring tokens. This process significantly reduces computational load while maintaining the quality of the final ranking.
The two-phase algorithm
The two-phase search algorithm operates in two stages:
- Initial Phase: The algorithm uses model inference to quickly select a set of candidate documents using high-scoring tokens from the query. These high-scoring tokens, which constitute a small portion of the total number of tokens, have significant weight—or relevance—allowing for a rapid identification of potentially relevant documents. This process significantly reduces the number of documents that need to be processed, thereby lowering computational costs.
- Recalculation Phase: The algorithm then recalculates the scores for the candidate documents selected in the first phase, this time including both high-scoring and low-scoring tokens from the query. Although low-scoring tokens carry less weight individually, they provide valuable information as part of a comprehensive evaluation, particularly when long-tail terms contribute significantly to the overall score. This allows the algorithm to determine final document scores with greater accuracy.
By processing documents in stages, this approach reduces computational overhead while mainitaining accuracy. The rapid selection in the first phase enhances efficiency, while the more detailed scoring in the second phase ensures accuracy. Even when handling a large number of long-tail terms, the results remain of high quality, with a notable improvement in computational efficiency.
Performance metrics
We measured the speed and quality of search results using neural sparse search.
Test environment
Performance was measured on OpenSearch clusters containing 3 m5.4xlarge nodes using OpenSearch Benchmark. The tests were conducted with 20 simultaneous clients, 50 warmup iterations, and 200 test iterations.
Test dataset
For search quality, we tested multiple BEIR datasets and measured the relative quality of the results. The following table presents parameter information for these datasets.
| Dataset | BEIR-Name | Queries | Corpus | Rel D/Q |
|---|---|---|---|---|
| NQ | nq | 3,452 | 2.68M | 1.2 |
| HotpotQA | hotpotqa | 7,405 | 5.23M | 2 |
| DBPedia | dbpedia-entity | 400 | 4.63M | 38.2 |
| FEVER | fever | 6,666 | 5.42M | 1.2 |
| Climate-FEVER | climate-fever | 1,535 | 5.42M | 3 |
p99 latency
The two-phase algorithm maintains the same inference time cost as the existing neural sparse search algorithm. To provide a clearer comparison of acceleration in the search phase, we excluded the inference step from latency calculations because inference is significantly affected by hardware type. The latency benchmark provided in this post uses raw vector search and excludes any additional impact resulting from inference time.
Doc-only mode
In doc-only mode, the two-phase processor can significantly decrease query latency, as shown in the following figure.
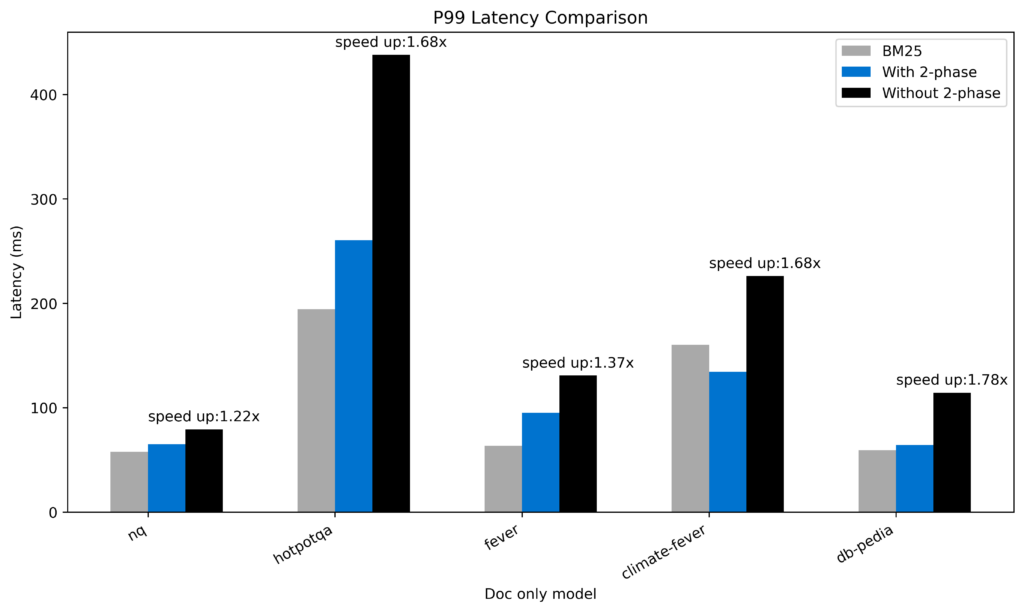
The following is the average latency:
- Without the two-phase algorithm: 198 ms
- With the two-phase algorithm: 124 ms
Depending on the data distribution, the two-phase processor achieved an increase in speed ranging from 1.22x to 1.78x.
Bi-encoder mode
In bi-encoder mode, the two-phase algorithm can significantly decrease query latency, as shown in the following figure.
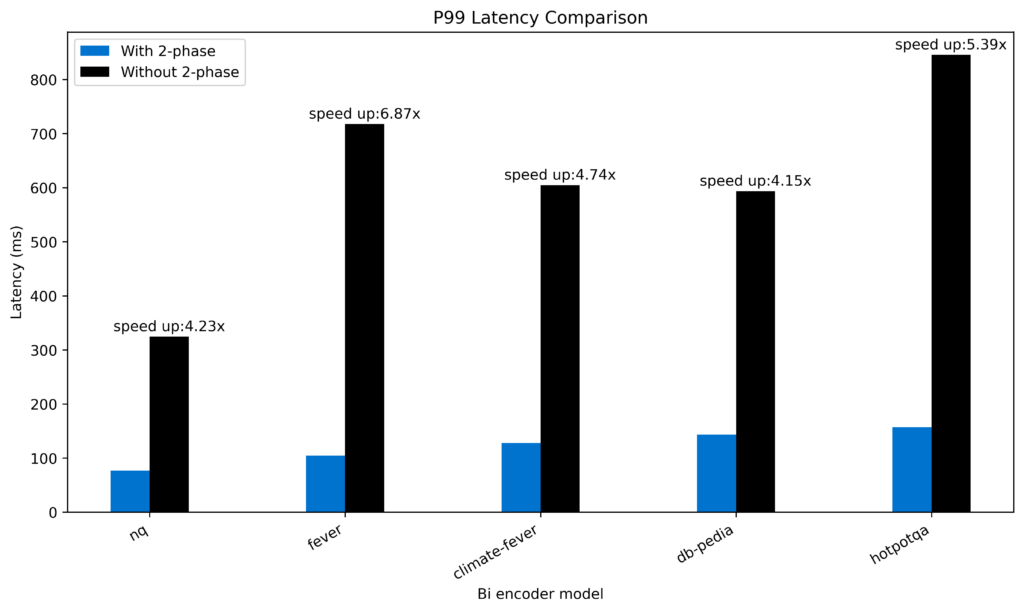
The following is the average latency:
- Without the two-phase algorithm: 617 ms
- With the two-phase algorithm: 122 ms
Depending on the data distribution, the two-phase processor achieved an increase in speed ranging from 4.15x to 6.87x.
Try it out
To try the two-phase processor, follow these steps.
Step 1: Set up a neural_sparse_two_phase_processor
First, configure a neural_sparse_two_phase_processor with the default parameters:
PUT /_search/pipeline/<custom-pipeline-name>
{
"request_processors": [
{
"neural_sparse_two_phase_processor": {
"tag": "neural-sparse",
"description": "This processor creates a neural sparse two-phase processor, which can speed up neural sparse queries!"
}
}
]
}
Step 2: Set the default search pipeline to neural_sparse_two_phase_processor
Assuming that you already have a neural sparse index, set the index’s index.search.default_pipeline to the pipeline created in the previous step:
PUT /<your-index-name>/_settings
{
"index.search.default_pipeline" : "<custom-pipeline-name>"
}
Next steps
For more information about the two-phase processor, see Neural sparse query two-phase processor.
Further reading
Read more about neural sparse search:
- Improving document retrieval with sparse semantic encoders
- A deep dive into faster semantic sparse retrieval in OpenSearch 2.12
- Advancing Search Quality and Inference Speed with v2 Series Neural Sparse Models


