
The recent release of OpenSearch 3.0 propelled the project’s tech stack forward with groundbreaking developments in performance, search, generative AI, and much more. OpenSearch 3.1 brings further innovation into the 3.x line with a host of updates to help you boost indexing performance, improve search results, dig deeper into your observability data, build more powerful agentic AI solutions, and maintain security for your OpenSearch deployments. Following are a selection of highlights from the latest version of OpenSearch; for a comprehensive view of new functionality, please visit the release notes. To get started with OpenSearch, download your preferred distribution or explore the toolkit with OpenSearch Playground.
Vector database and generative AI
OpenSearch 3.1 introduces new capabilities designed to increase vector search performance, simplify application development and management, and enhance observability for machine learning (ML) deployments.
Increase performance and improve costs for vector search with GPU processing
Released as experimental in OpenSearch 3.0, GPU acceleration for index builds is now generally available and production-ready in OpenSearch 3.1. With GPU acceleration enabled, you can take advantage of the parallel processing power of GPUs for computationally intensive index build operations, shaving time-to-build by a factor of 9.3x while reducing costs by 3.75x compared to CPU-based solutions. For a deep dive into the capabilities unlocked by GPU acceleration, see our blog post “GPU-accelerated vector search in OpenSearch: A new frontier.”
Enhance agent management with the Update Agent API
OpenSearch 3.1 introduces a valuable enhancement to agent management with the new Update Agent API. Previously, users had to create entirely new agents whenever they needed to modify configurations such as model IDs, workflow tools, or prompts, leading to unnecessary overhead and abandoned agent instances. The new API allows direct updates to existing agents, streamlining agent management and eliminating the need for agent recreation.
Access metrics and gain insights into machine learning operations
The ML Commons toolset is now fully integrated with the OpenSearch metrics framework, unlocking comprehensive monitoring capabilities with complete OpenTelemetry compatibility. The framework includes both dynamic instrumentation, offering the ability to capture runtime metrics along critical code paths, as well as static collection via scheduled jobs that report state-level metrics. Users can manage metrics collection through configurable settings, enabling detailed visibility into ML Commons operations and gaining deeper insights into observability data over time as metrics are incrementally captured. Now you can build robust observability solutions for tracking key usage patterns, performance trends, and potential bottlenecks in ML Commons deployments for improved system optimization and troubleshooting.
Boost efficiency for Faiss index searches with Lucene HNSW graph search
OpenSearch 3.1 enables Lucene’s HNSW graph search algorithm to run directly on existing Faiss indexes. While the Faiss C++ library requires loading the entire index into memory and lacks concurrent search optimization, Lucene supports partial byte loading and incorporates an effective early termination mechanism. This allows users to perform large-scale vector search in memory-constrained environments, including searches that would be impossible with Faiss C++; for example, with this functionality, you can now run a vector search on a 30 GB Faiss index within an instance that features 16 GB of memory. In quantization workflows, the early termination functionality can deliver up to 2x faster performance compared to Faiss C++.
Simplify workflow development with OpenSearch Flow upgrades
OpenSearch Flow features significant upgrades in this release, including a redesigned workflow detail page that simplifies end-to-end configuration with a unified view of all ingest and search components. A dynamic layout and contextual editing offer enhanced usability with a cleaner, easier-to-manage view of complex architectures. In addition, a new workflow template for semantic search using sparse encoders simplifies deployment of search-by-text and ranks results by semantic similarity, improving the quality and relevance of search experiences. The template applies the OpenSearch Neural Sparse Encoder to convert text into sparse vectors for a cost-efficient approach compared to dense (k-NN) retrieval, especially for smaller indexes of 10 million or fewer documents.
Improve search recall with OnDisk 4x compression rescoring
OpenSearch 3.1 enhances OnDisk 4x compression with default rescoring support for new indexes using 4x compression, offering a user-configurable balance between improved search accuracy and efficient data storage. This update preserves high search recall quality while maintaining the performance and efficiency benefits of compression. Users have the flexibility to further optimize performance; for example, to achieve even better recall, you can set the oversampling factor to a value higher than its default value of 1.0. Those who prefer the previous behavior have the option to explicitly set rescore to false.
Streamline semantic search set up with semantic field type
OpenSearch 3.1 introduces a new semantic field type for streamlining semantic search setup. You can define a semantic field in your index mapping with an associated ML model ID and OpenSearch will automatically create the appropriate embedding field based on the model’s metadata, eliminating the need to manually configure knn_vector or rank_features. Upon ingestion, OpenSearch uses the ML model you defined to generate vector embeddings without the need for a custom ingest pipeline. You can also enable text chunking by setting a simple flag in the mapping, allowing long text inputs to be split into passages automatically. Additionally, the neural query now supports semantic fields directly, so you can query with plain text and let OpenSearch handle embedding generation and field resolution.
Simplify MCP management with new APIs and persistent tools
OpenSearch 3.0 introduced built-in Model Context Protocol (MCP) support to provide seamless integration with AI agents. The 3.1 release enhances this functionality by exposing two additional APIs: The update MCP tools API, which allows MCP tools to be updated, and the list MCP tools API, which can review all of the MCP tools in the system. A new system index is also included, allowing the MCP tools to persist in the system index so that tools won’t be lost after a restart at the cluster or node level.
Search
This release introduces an array of new functionality to improve search results and advance resource management.
Test, evaluate, and optimize search algorithms with Search Relevance Workbench
For search teams, maintaining high-quality search results requires ongoing evaluation and tuning. Search practitioners often rely on homegrown scripts or standalone tools to measure, compare, and optimize results, missing out on the advantages of a built-in toolset. With OpenSearch 3.1, search teams can now deploy a comprehensive suite of tools, integrated into their OpenSearch search engine, to support improving search quality through experimentation and optimization.
Search Relevance Workbench lets you explore, experiment with, and tune your search strategies in OpenSearch. Presented at this month’s Berlin Buzzwords search conference, Search Relevance Workbench offers the ability to compare search algorithm results, evaluate search quality based on user activity via User Behavior Insights, and dive deep into search evaluation using metrics such as NDCG within the OpenSearch UI. Integrated with OpenSearch Dashboards, Search Relevance Workbench offers direct access to source data and comprehensive testing options to support real-world optimization and fast time-to-results. Visit the documentation to learn how to get started. Special thanks to the team at OpenSource Connections for their contributions to this toolset.
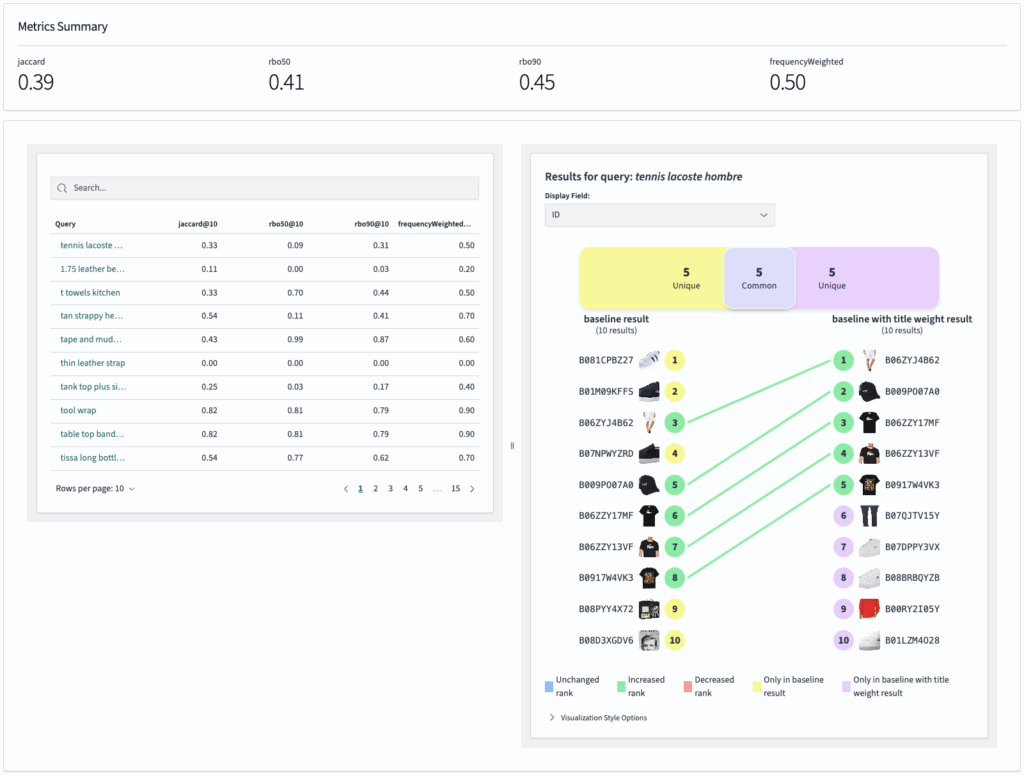
Visualize the impact of changes to search results across queries, with the ability to investigate a specific query.
Accelerate search performance with star tree index functionality
OpenSearch 3.1 makes star-tree indexes generally available to all users. Released as experimental in version 2.18, star-tree indexes can increase the performance of aggregations by up to 100x and support a comprehensive range of query and aggregation types. To learn more about the capabilities star-tree indexes can deliver, see our blog post “The power of star-tree indexes: Supercharging OpenSearch aggregations.”
Enhance control of cluster resources with workload management improvements
With this release, OpenSearch users can take advantage of index-based auto-tagging, a powerful tool for managing groups of tenants and defining rules for how they consume cluster resources, without the need to explicitly tag search requests via headers. This simplifies resource management for search workloads and improves the resiliency of the cluster by giving greater control to the cluster administrator, who can define which groups of search requests receive how much of a cluster’s memory and CPU resources.
Improve response times for hybrid queries
This release introduces advanced document collection and scoring techniques that boost hybrid search performance, delivering improvements of up to 65% in query response times and up to 3.5x in throughput. These algorithmic enhancements optimize how OpenSearch identifies and ranks matching documents during the fusion of lexical and semantic search results, making hybrid search even more efficient for production workloads.
Observability, log analytics, and security analytics
OpenSearch 3.1 incorporates a number of new capabilities to support observability and analytics workloads for deeper insights into monitored systems and applications.
Power complex analytics with upgraded tracing and correlation capabilities
As organizations adopt distributed systems and microservices architectures, they often struggle to correlate logs and traces across different formats and multiple clusters. OpenSearch 3.1 addresses these challenges with support for custom index names containing OpenTelemetry spans, logs, and service maps. Users can also map the custom fields timestamp, serviceName, spanId, and traceId for log indexes that do not follow the OpenTelemetry format. Additionally, for enterprises running large-scale distributed systems across multiple OpenSearch clusters, a new cross-cluster search capability for traces enables seamless trace analysis across cluster boundaries. New features for trace-to-logs correlation, combined with improvements to the trace Gantt chart, service map visualization, and hierarchical trace views, make it easier to monitor, troubleshoot, and maintain complex distributed applications regardless of logging format or deployment architecture.
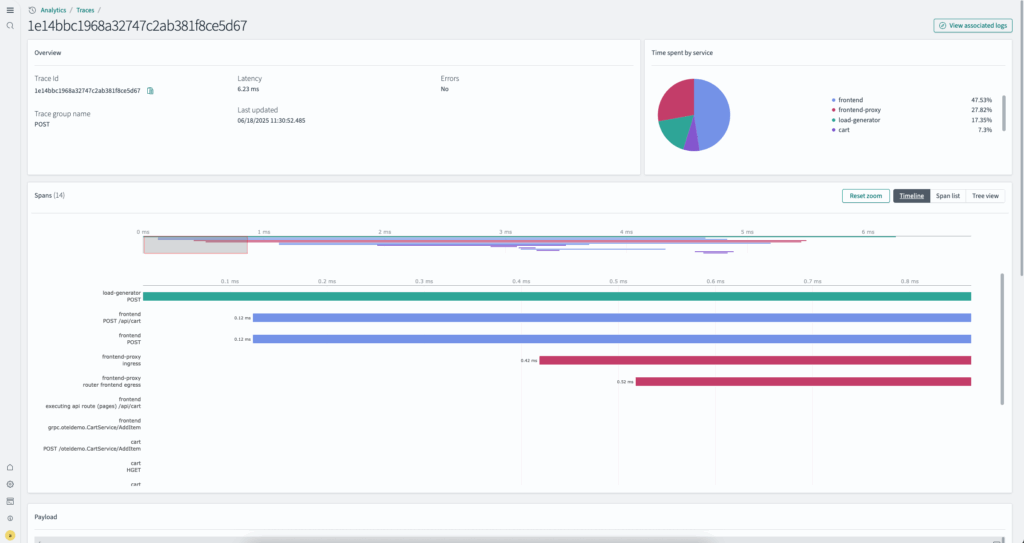
Visualize trace details, pinpoint latency and service impact, and correlate logs to accelerate investigations.
Analyze and query nested JSON structures with new PPL commands
As organizations store increasingly complex JSON data in OpenSearch, they can face challenges when attempting to analyze and query nested JSON structures efficiently. Data engineers and analysts frequently need to extract specific values from deeply nested JSON objects or transform nested arrays into a more analyzable format. OpenSearch 3.1 introduces a solution with powerful JSON functions and new Piped Processing Language (PPL) commands for JSON manipulation. New json_extract, json_value, and related JSON functions allow you to easily access and manipulate specific elements within JSON structures, while the flatten and expand commands let you transform nested JSON data into a tabular format for easier analysis. These capabilities eliminate the need for complex workarounds and enable sophisticated analysis of JSON data directly within OpenSearch, streamlining data processing workflows and improving analytical capabilities. Additional updates include more than 20 new PPL commands and functions, offering additional ways to explore your data with OpenSearch’s observability tools.
Security
OpenSearch 3.1 includes several updates designed to help you maintain the security of your OpenSearch deployments.
Improve Security plugin performance with an immutable user object
This release provides several updates designed to improve performance for the Security plugin, including an update that makes the user object immutable. This reduces the number of serializations and deserializations required as this object is passed internally within the cluster while handling a request. With an immutable user object, the user must only be serialized once after successful authentication and is reused subsequently, reducing performance overhead. In addition, ongoing efforts to optimize privilege evaluation now encompass tenant_permissions. Now OpenSearch roles take full advantage of precomputed data structures. Clusters using multi-tenancy (especially those with a large number of tenants) will realize performance gains across a range of different request types.
Improve security posture with resource sharing and access control enhancements
This release introduces experimental functionality designed to improve the security posture of OpenSearch deployments. While there is no change to the end user experience, this feature moves the sharing and access authorization setup from individual plugins to the Security plugin. Plugins will be required to onboard to this new feature; for this experimental feature release, Anomaly Detection has been updated to support the new authorization framework. To ensure a seamless experience, this feature must be enabled alongside Anomaly Detection’s own filter_by_backend_roles feature flag. Note that we recommend using this feature only on newly created 3.1 clusters because the tools used to migrate existing clusters are yet to be released.
Getting started
You can find the latest version of OpenSearch on our downloads page or check out the visualization tools on OpenSearch Playground. For more information, visit the release notes, documentation release notes, and updated documentation. If you’re exploring a migration to OpenSearch from another software provider, we offer tools and documentation designed to assist this process, available here.
Feel free to visit our community forum to share your valuable feedback on this release and connect with other OpenSearch users on our Slack instance.