
All OpenSearch indexes consist of shards, with each document in an index stored in a shard.
Traditionally, OpenSearch defines two shard types: primary shards and replica shards. The primary shard handles both indexing and search operations, while replica shards maintain a copy of the primary shard’s data to provide redundancy and serve search queries. You configure the number of shards at index creation time, and this number cannot be changed later without reindexing.
With the introduction of segment replication and remote storage in OpenSearch, this model has evolved. In segment replication, only the primary shard node performs indexing operations and writes segment files to a remote object store—such as Amazon Simple Storage Service (Amazon S3), Google Cloud Storage, or Azure Blob Storage. Replica shards then download the segment files from the object store in parallel, eliminating the need to replay indexing operations on each replica.
What’s new?
To separate indexing and search workloads, we’ve introduced new shard roles:
- Write replicas: Redundant copies of the primary shard. If a primary shard fails, a write replica can be promoted to primary to maintain write availability.
- Search replicas: Serve search queries exclusively and cannot be promoted to primaries.
For hardware separation between indexing and search workloads, we’ve introduced a new search node role. Primary shards and write replicas can be allocated to any node with the data role, while search replicas are allocated only to nodes with the search role. Nodes with the search role act as dedicated search-serving nodes.
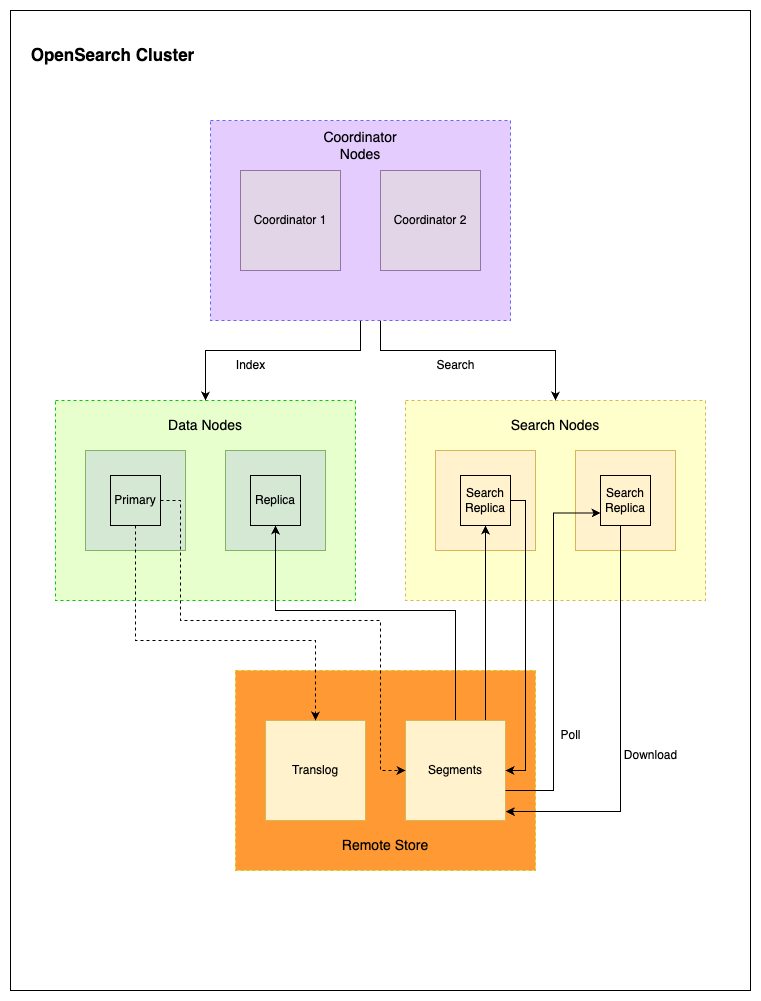
The following diagram shows an OpenSearch cluster with two coordinator nodes, two data nodes, and two search nodes, forming an indexing fleet and a search fleet. The index includes one primary shard, one write replica, and two search replicas. The primary shard and write replica are assigned to the data nodes, while the search replicas are assigned to the search nodes.
Each component is configured to perform the following:
- The remote store stores segment files and transaction logs. All replicas—including the write replica and search replicas—download segments from the remote store.
- The primary shard writes both segments and transaction logs to the remote store.
- The write replica downloads segments after the primary completes writing.
- The search replicas continuously poll the remote store for new segments.
Benefits
Separating indexing and search workloads provides the following benefits:
- Parallel and isolated processing: Improve throughput and predictability by isolating indexing and search.
- Independent scalability: Scale indexing and search independently by adding
dataorsearchnodes. - Failure resilience: Indexing and search failures are isolated, improving availability.
- Cost efficiency and performance: Use specialized hardware—compute optimized for indexing and memory optimized for search.
- Tuning flexibility: Optimize performance settings like buffers and caches independently for indexing and search.
- Failure isolation: Indexing and search issues are separated, which helps in troubleshooting failures.
- Scalable design: Scale indexing and search independently of each other.
Enabling indexing and search separation
For detailed instructions, see Separate index and search workloads.
Scale to zero with reader/writer separation: The search-only mode
In write-once, read-many scenarios—like log analytics or frozen time-series data—you can reduce resource usage after indexing completes. OpenSearch now supports a search-only mode through the _scale API, allowing you to disable primary shards and write replicas while leaving only search replicas active.
This significantly reduces storage and compute costs while maintaining full search capabilities, providing the following benefits:
- Scale down indexing capacity when writes are no longer needed.
- Free up disk and memory capacity by removing unnecessary write paths.
- Work smoothly with index lifecycle controls through
_open/_closeoperations. - Keep only search replicas active to reduce resource usage.
- Maintain green cluster health with active search paths.
- Auto-recover search replicas without manual intervention.
- Scale back up at any time to resume indexing.
- Scale search replicas based on search traffic during search-only mode.
OpenSearch maintains cluster health as GREEN when search-only mode is active despite disabling primaries and write replicas. This is because only search replicas are expected to be allocated, and they are all successfully assigned. This ensures operational stability and full search availability.
How it works
When the _scale API is called with { "search_only": true }, OpenSearch performs the following operations:
- Adds an internal search-only block to the index
- Scales down all primaries and write replicas
- Keeps only search replicas active
To resume indexing, run the _scale operation with { "search_only": false }. OpenSearch restores the original index state. Even in search-only mode, cluster health remains GREEN because all expected search replicas are allocated.
Benchmark comparison
We benchmarked indexing throughput and query latency across three cluster configurations using the http_logs workload in OpenSearch Benchmark. The test ran 50% of indexing first, followed by simultaneous indexing and an expensive multi-term aggregation query.
Cluster configurations
Using opensearch-cluster-cdk, we set up three different clusters on AWS. The followings table shows the node roles and associated costs based on the Amazon Elastic Compute Cloud (Amazon EC2) instance types used. Instance pricing is taken from Amazon EC2 Instance types.
Cluster 1 (c1-r6g): Standard cluster with Memory Optimized instances for data nodes
| Node role | Number of nodes | Instance type | Hourly cost | Total hourly cost |
|---|---|---|---|---|
| Data | 4 | r6g.xlarge | $0.20 | $0.81 |
| Coordinator | 2 | r6g.xlarge | $0.20 | $0.40 |
| Cluster manager | 3 | c6g.xlarge | $0.14 | $0.41 |
| $1.62 |
Cluster 2 (c2-c6g): Standard cluster with Compute Optimized instances for data nodes
| Node role | Number of nodes | Instance type | Hourly cost | Total hourly cost |
|---|---|---|---|---|
| Data | 4 | c6g.xlarge | $0.14 | $0.54 |
| Coordinator | 2 | r6g.xlarge | $0.20 | $0.40 |
| Cluster manager | 3 | c6g.xlarge | $0.14 | $0.41 |
| $1.36 |
Cluster 3 (c3-indexing-search): Indexing-and-search-separated cluster with Compute and Memory Optimized instances for data and search nodes
| Node role | Number of nodes | Instance type | Hourly cost | Total hourly cost |
|---|---|---|---|---|
| Data | 2 | c6g.xlarge | $0.14 | $0.27 |
| Search | 2 | r6g.xlarge | $0.20 | $0.40 |
| Coordinator | 2 | r6g.xlarge | $0.20 | $0.40 |
| Cluster manager | 3 | c6g.xlarge | $0.14 | $0.41 |
| $1.49 |
Result visualizations
The following charts show the indexing throughput and the query latency differences across these three clusters.
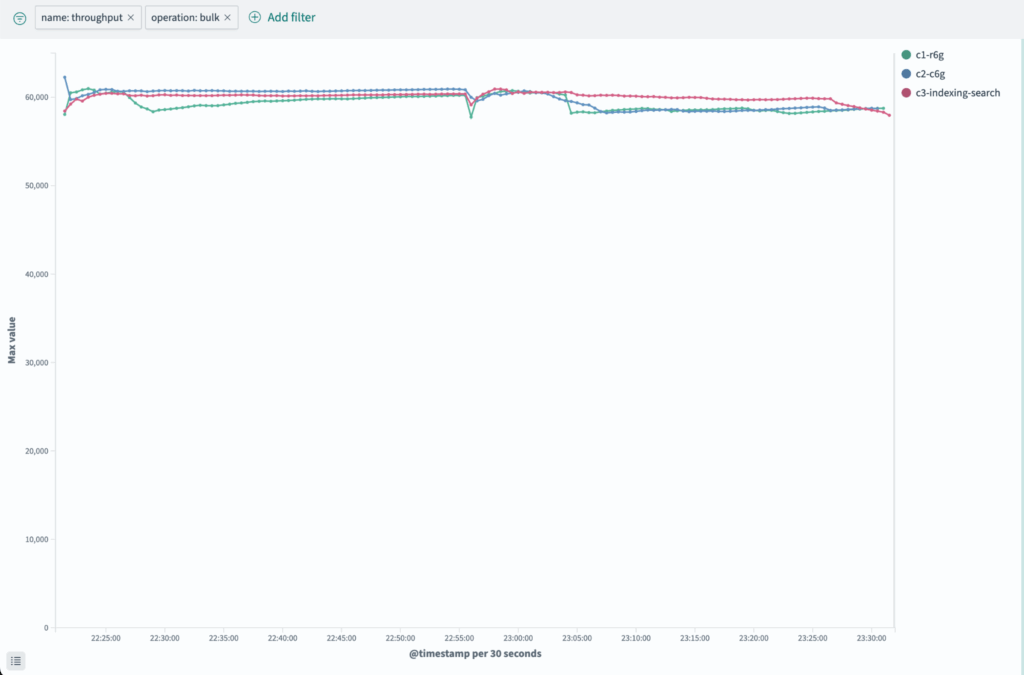
The following chart compares indexing throughput across the three cluster configurations.
The following chart shows how separating workloads improves query latency.
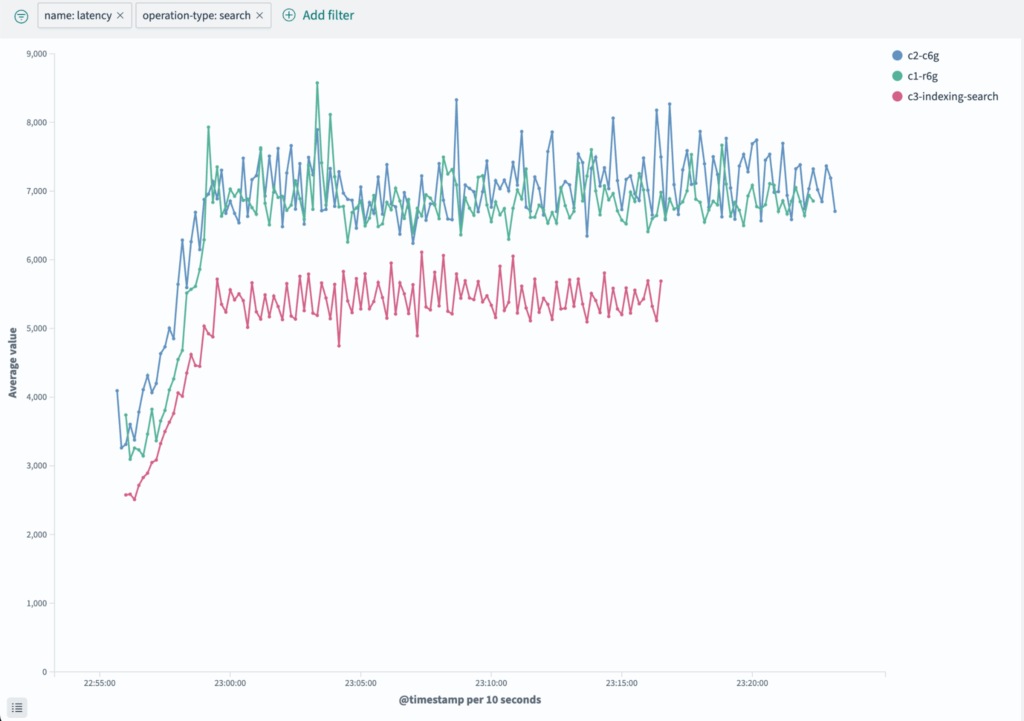
The results show that Cluster 3 slightly outperforms the other clusters in simultaneous indexing and search while significantly reducing query latency and lowering costs.
Result metrics and comparisons
The following tables provide comparisons between each cluster’s benchmark results.
Comparing Cluster 1 and Cluster 3
| Cluster 1 (5P, 3R) | Cluster 3 (5P, 1R, 1S) | Difference | ||
|---|---|---|---|---|
| Index throughput | Median | 58523.95095 | 59818.80119 | 2.16462 |
| Maximum | 58777.10938 | 60240.02344 | 2.42848 | |
| Query latency | p50 | 6725.72925 | 5358.19263 | -25.52235 |
| p90 | 7218.57544 | 5875.875 | -22.85107 | |
| p99 | 8073.80762 | 6180.44385 | -30.63475 | |
| p100 | 8575.49512 | 6312.8374 | -35.84217 | |
| Cost/hr | 1.62 | 1.49 | -8.72483 |
Comparing Cluster 2 and Cluster 3
| Cluster 2 (5P, 3R) | Cluster 3 (5P, 1R, 1S) | Difference | ||
|---|---|---|---|---|
| Index throughput | Median | 58520.82413 | 59818.80119 | 2.16985 |
| Maximum | 59169.29297 | 60240.02344 | 1.77744 | |
| Query latency | p50 | 6842.04297 | 5358.19263 | -27.69311 |
| p90 | 7708.91797 | 5875.875 | -31.19609 | |
| p99 | 8328.41211 | 6180.44385 | -34.75427 | |
| p100 | 8438.39258 | 6312.8374 | -33.67036 | |
| Cost/hr | 1.36 | 1.49 | 8.72483 |
Result summary
From these comparisons, we can see that Cluster 3 is slightly better (~2% improvement) for simultaneous indexing and search workloads and has much lower query latency (~34% improvement). This is achieved with ~8% lower cost per hour compared to Cluster 1.
Conclusion
Separating indexing and search workloads in OpenSearch gives you greater control over scaling, tuning, and optimizing your cluster. Whether you want to prioritize throughput, reduce latency, or manage costs, this approach helps meet the needs of modern applications.
Future work
Coordinator nodes currently handle both search and indexing requests. For full separation, consider routing indexing and search traffic to distinct coordinator node groups.


