
In an era of AI revolutionizing how we interact with information, traditional keyword-based search has become increasingly insufficient. Users expect search engines to understand context, interpret natural language, and deliver intelligent results, so the ability to integrate machine learning (ML) capabilities directly into search operations has become increasingly crucial. OpenSearch’s ML inference processors solve this problem by allowing seamless integration of ML models into your ingest and search workflows. Whether you’re building a next-generation enterprise search platform or enhancing your existing search infrastructure with AI capabilities, ML inference processors provide the foundation for intelligent search experiences that meet modern user expectations.
What are ML inference processors?
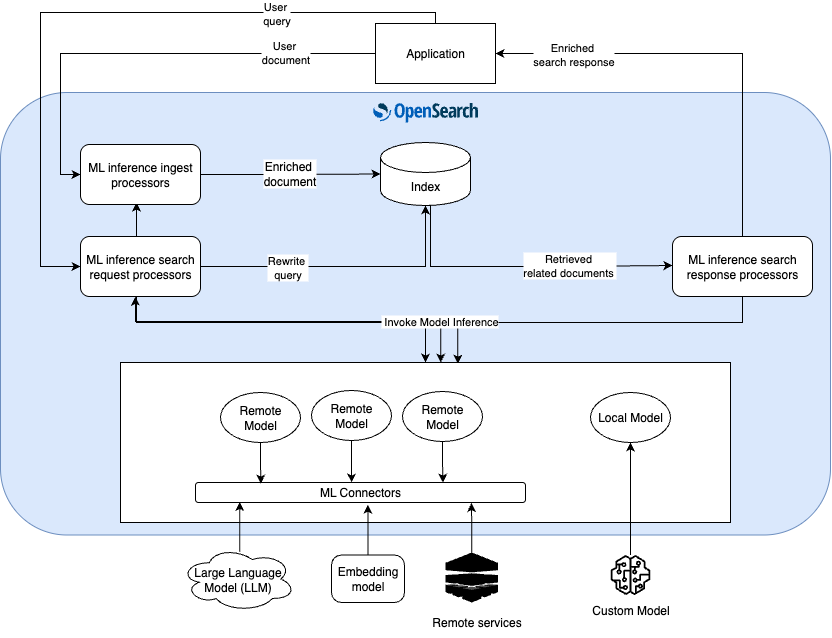
OpenSearch provides three types of ML inference processors, each serving a specific purpose in the ingest pipeline or search pipeline:
- ML inference ingest processors (released 2.14): These processors run model inference during document indexing, allowing you to use ML models to enrich or transform documents before they’re stored. For example, you can generate text embeddings or add sentiment labels to documents during indexing.
- ML search request processors (released 2.16): These processors run model inference on search queries before they’re executed, enabling query enhancement or transformation. They can rewrite queries based on ML model output, making them particularly useful for query understanding and expansion.
- ML search response processors (released 2.16): These processors run model inference to enrich search results before they’re returned to the user, enabling features like result reranking or adding ML-generated summaries to search results.
The following diagram illustrates how ML inference processors integrate with indexing, querying, and search result handling in OpenSearch. It shows the full end-to-end flow, including a user query or document, model invocation, and enriched responses.
Key benefits
ML inference processors offer the following key benefits:
- Flexibility: Support for both local and external ML models.
- Real-time processing: ML inference occurs during ingest and search operations.
- Customization: Extensive configuration options for input/output mapping.
- Ease of use: Once you configure ML inference processors in the search/ingest pipeline, they are applied automatically to every ingest/search operation.
Common use cases
ML inference processors enable various advanced search capabilities:
- Semantic search: Generate and search documents using text embeddings.
- Multimodal search: Combine text and image search.
- Query understanding: Enhance queries with ML-based understanding.
- Result ranking: Improve result relevance using ML models.
- Document enrichment: Add ML-generated metadata during indexing.
Getting started: Search and summarization pipeline
Let’s walk through a practical example of using ML inference search response processors to implement semantic search using a text embedding model and generate summarization using a large language model (LLM).
Step 1: Register models in OpenSearch
First, you need to register two models: a text embedding model for generating embeddings and an LLM for summarization. In this example, you’ll use the amazon.titan-embed-text-v2:0 text embedding model and the us.anthropic.claude-3-7-sonnet-20250219-v1:0 LLM.
Register a text embedding model:
POST /_plugins/_ml/connectors/_create
{
"name": "Amazon Bedrock: amazon.titan-embed-text-v2:0",
"function_name": "remote",
"description": "amazon.titan-embed-text-v2:0 model to generate embeddings",
"connector": {
"name": "Amazon Bedrock Connector: embedding",
"description": "The connector to bedrock Titan embedding model",
"version": 1,
"protocol": "aws_sigv4",
"parameters": {
"region": "{% raw %}{{aws_region}}{% endraw %}",
"service_name": "bedrock",
"model": "amazon.titan-embed-text-v2:0",
"dimensions": 1024,
"normalize": true,
"embeddingTypes": ["float"]
},
"credential": {
"access_key": "{% raw %}{{access_key}}{% endraw %}",
"secret_key": "{% raw %}{{secret_key}}{% endraw %}",
"session_token": "{% raw %}{{session_token}}{% endraw %}"
},
"actions": [
{
"action_type": "predict",
"method": "POST",
"url": "https://bedrock-runtime.${parameters.region}.amazonaws.com/model/${parameters.model}/invoke",
"headers": {
"content-type": "application/json",
"x-amz-content-sha256": "required"
},
"request_body": "{ \"inputText\": \"${parameters.inputText}\", \"dimensions\": ${parameters.dimensions}, \"normalize\": ${parameters.normalize}, \"embeddingTypes\": ${parameters.embeddingTypes} }"
}
]
}
}
{
"task_id": "BkfyvJcBIkSrvQFRJf_E",
"status": "CREATED",
"model_id": "B0fyvJcBIkSrvQFRJf_j"
}
POST /_plugins/_ml/models/B0fyvJcBIkSrvQFRJf_j/_predict
{
"parameters": {
"inputText": "cute women jacket"
}
}
{
"inference_results": [
{
"output": [
{
"name": "response",
"dataAsMap": {
"embedding": [
-0.09490113705396652,
0.09895417094230652,
0.02126065082848072,
...],
"embeddingsByType": {
"float": [
-0.09490113705396652,
0.09895417094230652,
0.02126065082848072,
... ]
},
"inputTextTokenCount": 5
}
}
],
"status_code": 200
}
]
}
POST /_plugins/_ml/connectors/_create
{
"name": "Amazon Bedrock: claude-3-7-sonnet-20250219-v1:0",
"function_name": "remote",
"description": "claude-3-7-sonnet-20250219-v1:0 model to generate review summary",
"connector": {
"name": "Amazon Bedrock Connector: claude-3-7-sonnet-20250219-v1:0",
"description": "The connector to bedrock claude-3-7-sonnet-20250219-v1:0",
"version": 1,
"protocol": "aws_sigv4",
"parameters": {
"region": "{% raw %}{{aws_region}}{% endraw %}",
"service_name": "bedrock",
"max_tokens": 8000,
"temperature": 1,
"anthropic_version": "bedrock-2023-05-31",
"model": "us.anthropic.claude-3-7-sonnet-20250219-v1:0"
},
"credential": {
"access_key": "{% raw %}{{access_key}}{% endraw %}",
"secret_key": "{% raw %}{{secret_key}}{% endraw %}",
"session_token": "{% raw %}{{session_token}}{% endraw %}"
},
"actions": [
{
"action_type": "predict",
"method": "POST",
"headers": {
"content-type": "application/json"
},
"url": "https://bedrock-runtime.${parameters.region}.amazonaws.com/model/${parameters.model}/invoke",
"request_body": "{ \"anthropic_version\": \"${parameters.anthropic_version}\", \"max_tokens\": ${parameters.max_tokens}, \"temperature\": ${parameters.temperature}, \"messages\": ${parameters.messages} }"
}
]
}
}
{
"task_id": "AkfavJcBIkSrvQFRP_9s",
"status": "CREATED",
"model_id": "A0favJcBIkSrvQFRP_-N"
}
POST /_plugins/_ml/models/A0favJcBIkSrvQFRP_-N/_predict
{
"parameters": {
"context": "Recently, i have been so wanting to get a lightwash denim jacket and i found the piece right here! i love that its cropped and so easy to wear. its not stiff at all and sized right. i got an xs my normal size and its so comfy and surprisingly soft. great find but just a bit pricey.. but probably bc its paige. too bad pilcrow couldn't have made something like this.",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "you are a helpful assistant, help me summarize the context from ${parameters.context}, and show me the summary in 60 words."
}
]
}
]
}
}
{
"inference_results": [
{
"output": [
{
"name": "response",
"dataAsMap": {
"id": "msg_bdrk_01EA4VRf9YVK1hVZeGojqDNc",
"type": "message",
"role": "assistant",
"model": "claude-3-7-sonnet-20250219",
"content": [
{
"type": "text",
"text": "# Summary\n\nThe author found a cropped light-wash denim jacket by Paige that they love. The jacket is comfortable, soft, not stiff, and fits well in their usual XS size. While they're pleased with the purchase, they feel it's somewhat expensive and wish a more affordable brand like Pilcrow offered a similar style."
}
],
"stop_reason": "end_turn",
"usage": {
"input_tokens": 123.0,
"cache_creation_input_tokens": 0.0,
"cache_read_input_tokens": 0.0,
"output_tokens": 77.0
}
}
}
],
"status_code": 200
}
]
}
Step 2: Create an ingest pipeline
Next, create an ingest pipeline that automatically generates embeddings for your documents. This pipeline uses an ML inference processor to extract text from the review_text field in each incoming document, send that text to your registered text embedding model, retrieve the generated embedding from the model’s response, and add the embedding to the document as a new review_embedding field:
PUT /_ingest/pipeline/titan_embedding_pipeline
{
"description": "Generate review_embedding for ingested documents",
"processors": [
{
"ml_inference": {
"model_id": "B0fyvJcBIkSrvQFRJf_j",
"input_map": [
{
"inputText": "review_text"
}
],
"output_map": [
{
"review_embedding": "embedding"
}
]
}
}
]
}
PUT /product-search-and-summarize
{
"settings": {
"index": {
"default_pipeline": "titan_embedding_pipeline",
"knn": true,
"knn.algo_param.ef_search": 100
}
},
"mappings": {
"properties": {
"review_embedding": {
"type": "knn_vector",
"dimension": 1024
}
}
}
}
Step 3: Ingest sample documents
Index sample product review documents to test the pipeline. The embeddings are generated automatically:
POST /_bulk
{
"index": {
"_index": "clothing_reviews",
"_id": "11364"
}
},
{
"review_id": 11364,
"clothing_id": 956,
"age": 83,
"title": "Great gift!!",
"review_text": "Got this poncho for christmas and loved it the moment i got it out of the box!! great quality and looks great cant go wrong with this purchase.",
"rating": 5,
"recommended": true,
"positive_feedback_count": 0,
"division_name": "General Petite",
"department_name": "Jackets",
"class_name": "Jackets"
},
{
"index": {
"_index": "clothing_reviews",
"_id": "16373"
}
},
{
"review_id": 16373,
"clothing_id": 956,
"age": 39,
"title": "Great \"cardigan\"",
"review_text": "If you're very small-framed and/or petite, i would size down in this. unless you want a really slouchy look and fit. i have very broad shoulders and very large biceps, and typically wear a m/l in retailer tops. sometimes if a top is a pullover style (as opposed to button-down) i have to size up to a 12 to get the top to accommodate my shoulder width and biceps. so i was leery the size 8/italian 44 would fit, but it does, with room to spare, albeit it is not as loose or long in the ar",
"rating": 4,
"recommended": true,
"positive_feedback_count": 5,
"division_name": "General",
"department_name": "Jackets",
"class_name": "Jackets"
}
Step 4: Configure a search pipeline
To enhance search queries, you’ll create a search pipeline that generates a summary of a search response using the configured LLM.
The ml_inference search request processor is configured to rewrite the match query as a k-NN query using the review_embedding field. It maps the query.match.review_text.query to the inputText parameter for the embedding model, which generates a vector representation of the review text. The output of this processor is stored in embedding, which is then used in the k-NN query to find similar reviews based on their embeddings.
The ml_inference search response processor configuration establishes a three-part mapping process for generating summaries using ML inference. First, the input_map takes the review_text field from each search result and maps it to a context variable for the model. Then the model_config formats this input as a structured messages array for the Claude model, using ${parameters.context} as a placeholder for the actual review text. Finally, the output_map directs the model’s response (found at content[0].text in Claude’s output) to be stored in review_summary in the search results. This complete flow allows the pipeline to automatically process search results through the ML model and attach generated summaries to the response, all configured through a single pipeline definition.
Create a search pipeline that combines semantic search with automatic summarization by configuring both request and response processors:
PUT /_search/pipeline/summarization_pipeline
{
"description": "conduct semantic search for product review and summarize reviews",
"request_processors": [
{
"ml_inference": {
"tag": "embedding",
"description": "This processor is to rewriting match query to knn query during search",
"model_id": "B0fyvJcBIkSrvQFRJf_j",
"query_template": "{\"query\":{\"knn\":{\"review_embedding\":{\"vector\":${modelPredictionOutcome},\"k\":5}}}}",
"input_map": [
{
"inputText": "query.match.review_text.query"
}
],
"output_map": [
{
"modelPredictionOutcome": "embedding"
}
]
}
}
],
"response_processors": [
{
"ml_inference": {
"tag": "summarization",
"description": "This processor is to summarize reviews during search response",
"model_id": "A0favJcBIkSrvQFRP_-N",
"input_map": [
{
"context": "review_text"
}
],
"output_map": [
{
"review_summary": "content[0].text"
}
],
"model_config": {
"messages": "[{\"role\":\"user\",\"content\":[{\"type\":\"text\",\"text\":\"you are a helpful assistant, help me summarize the context from ${parameters.context}, and show me the summary in 20 words.\"}]}]"
},
"one_to_one": true,
"ignore_missing": false,
"ignore_failure": false
}
}
]
}
Step 5: Search the documents
You can now run searches using your ML-enhanced pipeline. Run a semantic search query that will automatically convert your natural language question into vector embeddings and find similar reviews:
GET /product-search-and-summarize/_search?search_pipeline=summarization_search_pipeline
{
"query": {
"match": {
"review_text": "I am planning for a vacation to France. Find me a nice jacket"
}
}
}
The search response returns semantically relevant documents along with AI-generated summaries in the review_summary field, demonstrating both vector similarity matching and automatic text summarization:
{
"took": 109,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.38024604,
"hits": [
{
"_index": "product-search-and-summarize",
"_id": "2",
"_score": 0.38024604,
"_source": {
"review_embedding": [
-0.02479235,
-0.018683413,
0.024477331,
...
],
"review_id": 16373,
"clothing_id": 956,
"department_name": "Jackets",
"rating": 4,
"title": "Great \"cardigan\"",
"recommended": true,
"positive_feedback_count": 5,
"division_name": "General",
"review_text": "If you're very small-framed and/or petite, i would size down in this. unless you want a really slouchy look and fit. i have very broad shoulders and very large biceps, and typically wear a m/l in retailer tops. sometimes if a top is a pullover style (as opposed to button-down) i have to size up to a 12 to get the top to accommodate my shoulder width and biceps. so i was leery the size 8/italian 44 would fit, but it does, with room to spare, albeit it is not as loose or long in the ar",
"review_summary": "This top runs large. If you're petite, size down unless you prefer a slouchy fit. Size 8/Italian 44 fits even with broad shoulders.",
"class_name": "Jackets",
"age": 39
}
},
{
"_index": "product-search-and-summarize",
"_id": "1",
"_score": 0.34915876,
"_source": {
"review_embedding": [
-0.025242768,
0.041105438,
0.073424794,
...
],
"review_id": 11359,
"clothing_id": 956,
"department_name": "Jackets",
"rating": 5,
"title": "Love!!!",
"recommended": true,
"positive_feedback_count": 1,
"division_name": "General Petite",
"review_text": "I fell in love with this poncho at first sight. the colors are neutral so it can be worn with a lot. i'm a typical m and it does run large so i went with a s and it's perfect. long enough to cover leggings and great for the in between seasons. i've worn it at least five times since purchase and get compliments every time.",
"review_summary": "Poncho is loved for neutral colors, versatility. Buyer got size small despite being medium. Covers leggings, receives compliments.",
"class_name": "Jackets",
"age": 37
}
}
]
},
"profile": {
"shards": []
}
}
Conclusion
ML inference processors in OpenSearch represent a significant leap forward in search technology, bridging the gap between traditional keyword-based search and modern AI-powered experiences. Through the practical example demonstrated in this post, you’ve seen how these processors can seamlessly integrate embedding models for semantic search and LLMs for content summarization, creating a more intelligent and user-friendly search experience.
The combination of ingest-time processing for embeddings and search-time processing for summarization showcases the flexibility and power of OpenSearch’s ML inference processors. This architecture not only improves search relevance through vector similarity matching but also enhances the user experience by providing concise, AI-generated summaries of search results.
Next steps
For more information about ML inference processors, see the ML inference processor, ML inference search request processor, and ML inference search response processor documentation.
For a specific use case, see Semantic search tutorials.
We welcome your contributions! If you have a use case to share, consider adding a corresponding tutorial to the documentation.

