
With this latest version of the OpenSearch distribution (OpenSearch, OpenSearch Dashboards, as well as plugins and tools) you can enjoy a number of new features and enhancements as well as improvements to stability and efficiency.
One of the major new additions to 1.3.0 is a set of tools for observability between logs, metrics, and other live data. When critical, event-based information is correlated with other application or system data and reported centrally, availability issues are easier to identify and resolve. Try these new tools out (see Observability, below) and let the community know what you think.
Here is a list of major and minor feature enhancements that have been included in this release:
Index State Management
- Continuous Mode in Transform: With this release, you can now run transforms in a continuous mode based on a schedule. This enables you to keep an incremental transform job running on a group of source indices actively ingesting new data. At each run, only the modified buckets will be transformed, reducing the overhead for users who want to keep their transform up-to-date.
Observability
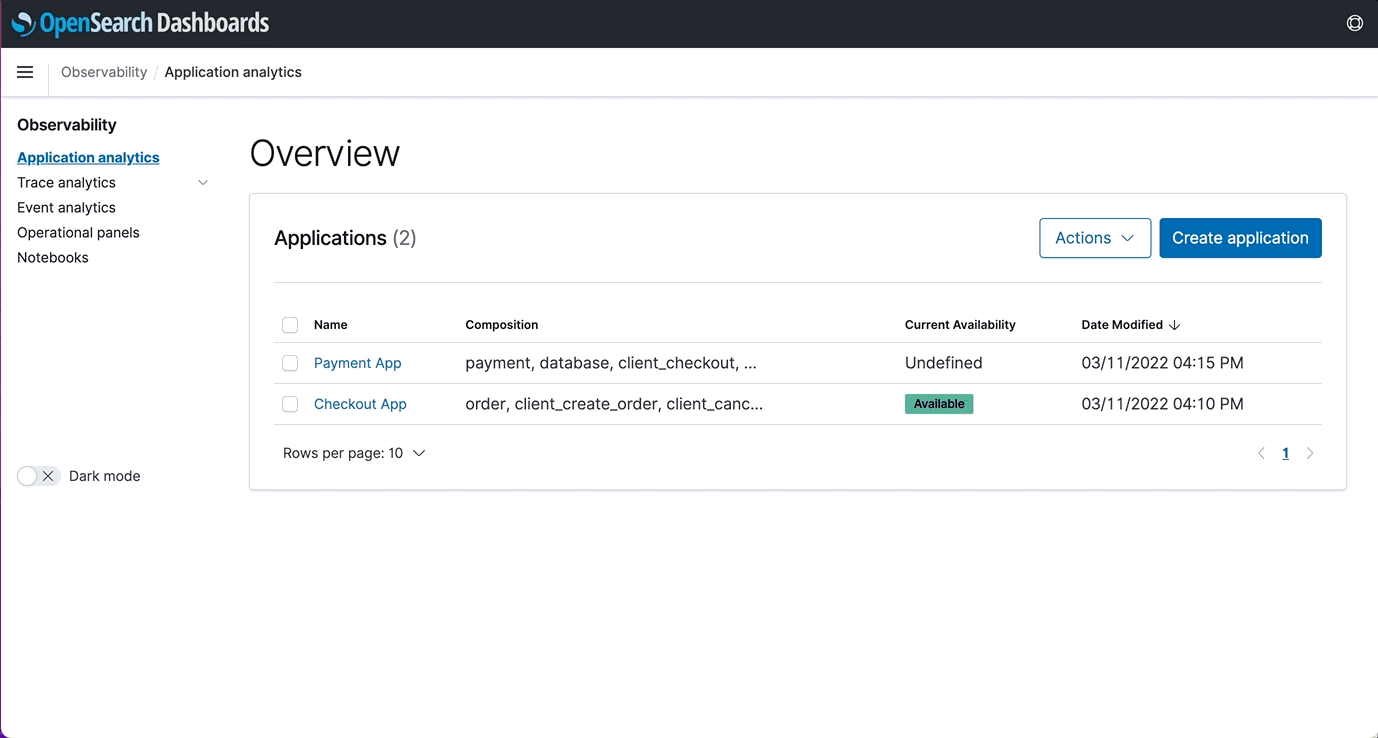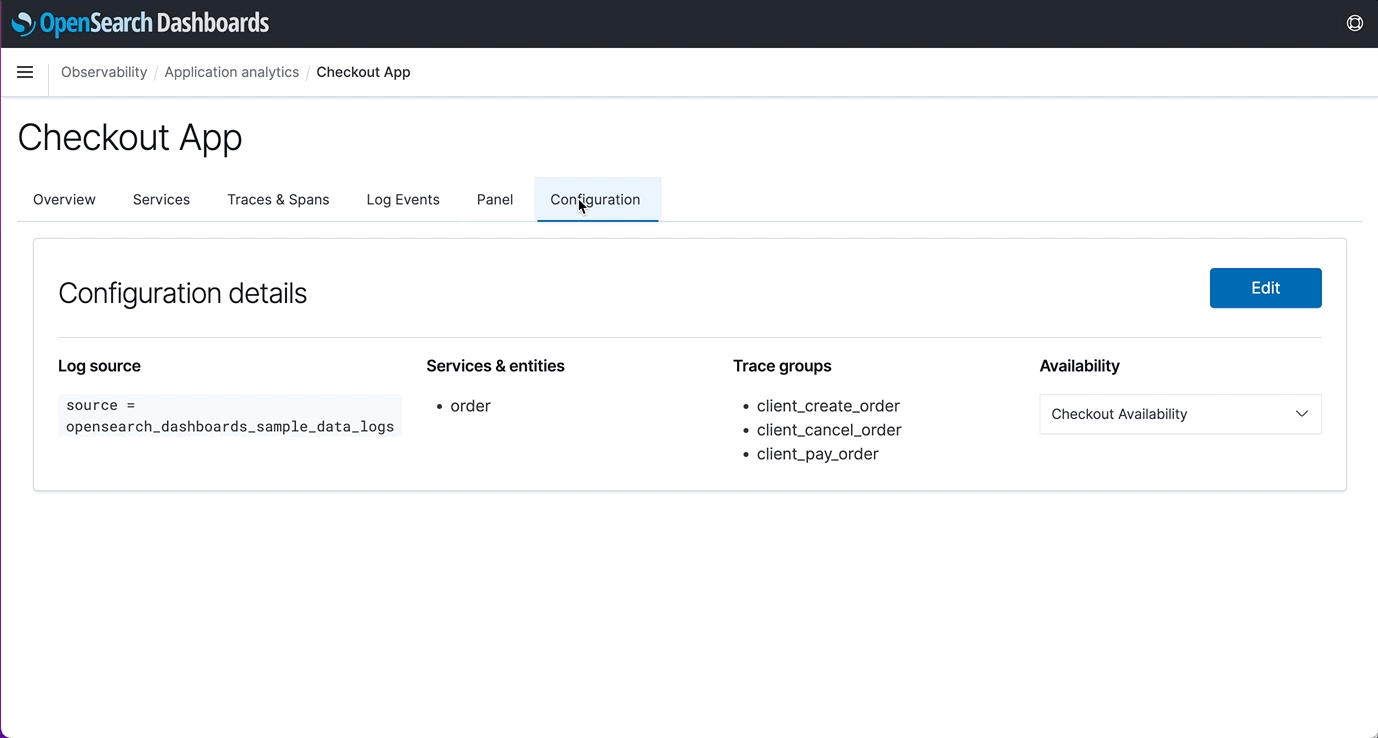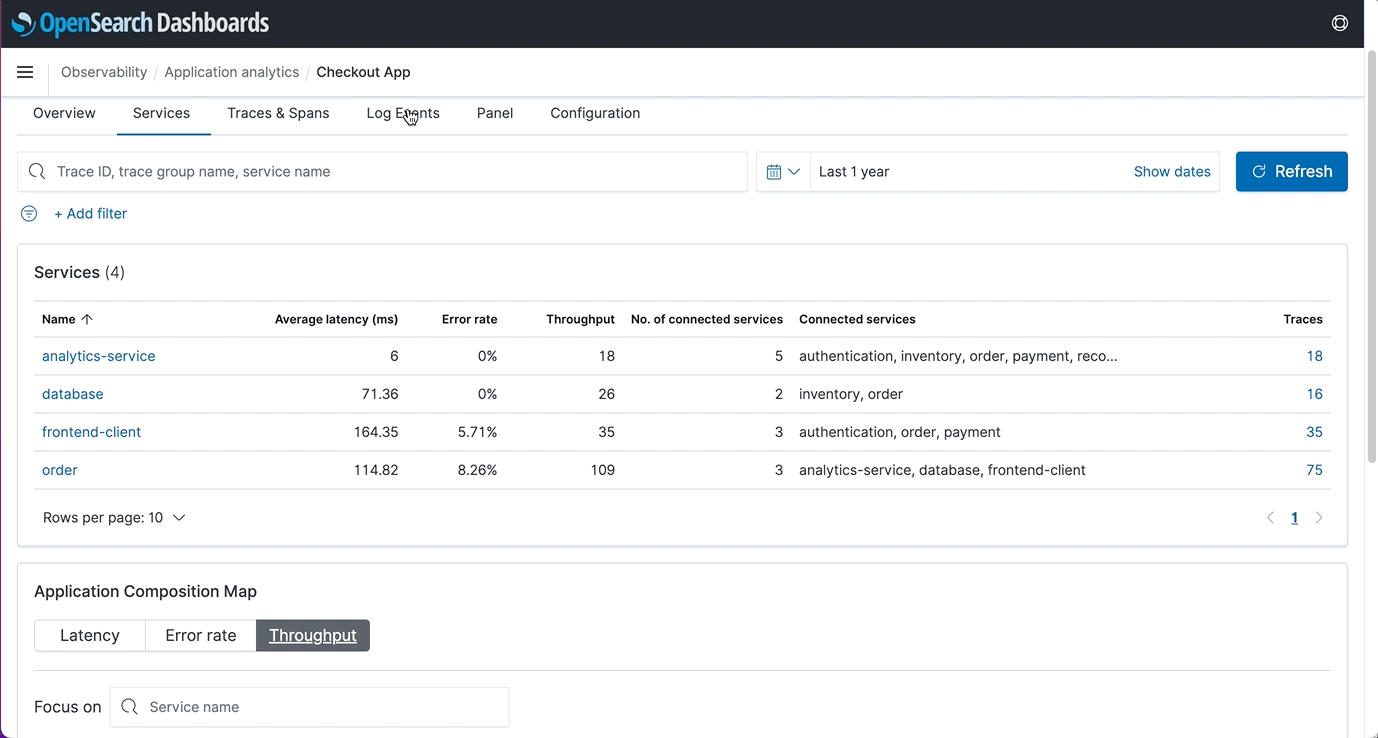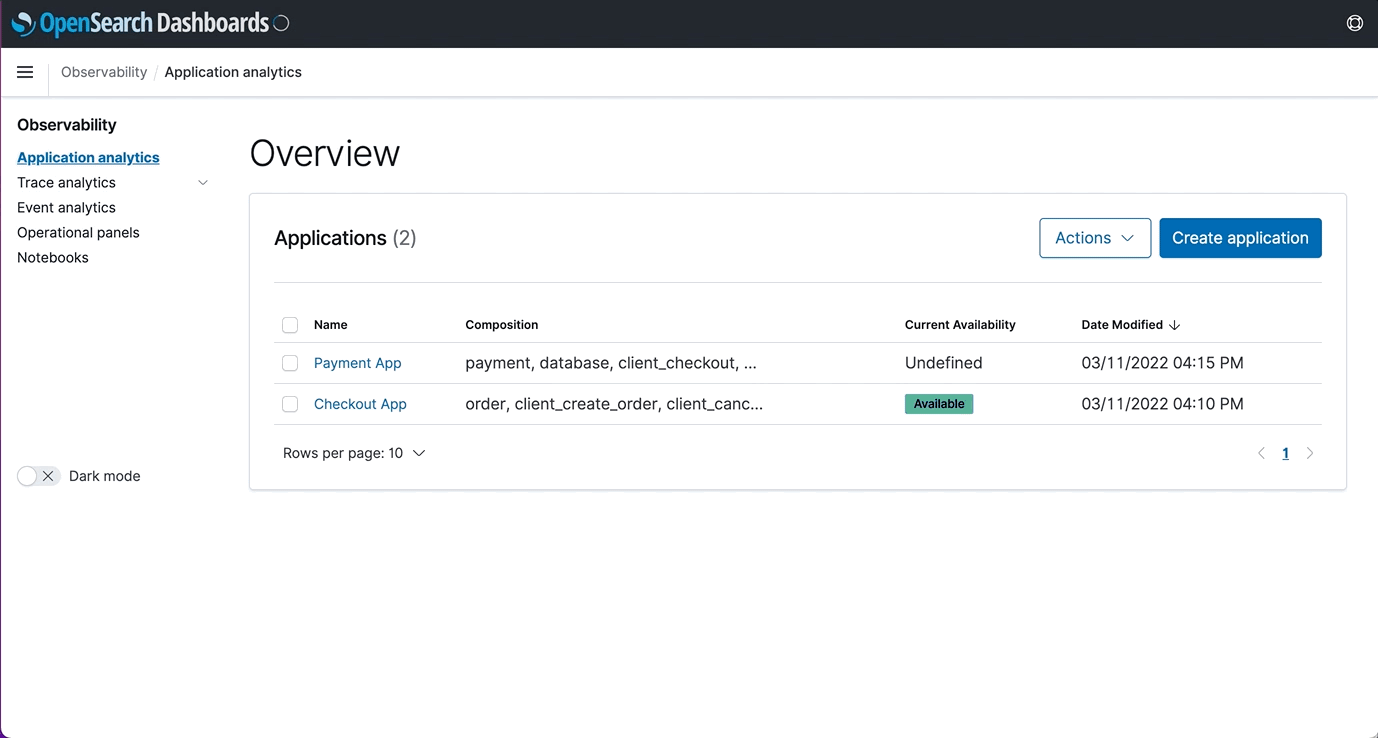
Users can now create custom Observability Applications to view the availability status of all their systems, where log events can be combined with trace and metric data, into a single view of system health empowering developers and IT Ops to resolve issues faster and with fewer escalations.
- App Analytics: In the past, users had to collate logs, traces, and metrics in separate views which made application monitoring difficult. With App Analytics Dashboards, users can now view application logs, traces, and metrics in one view instead of moving between different visualizations.
- Trace ID Correlation: Users who regularly track events across applications will now be able to use correlation ID (based on the Open Telemetry specification) to tie events together when viewing events and in-context visualizations.
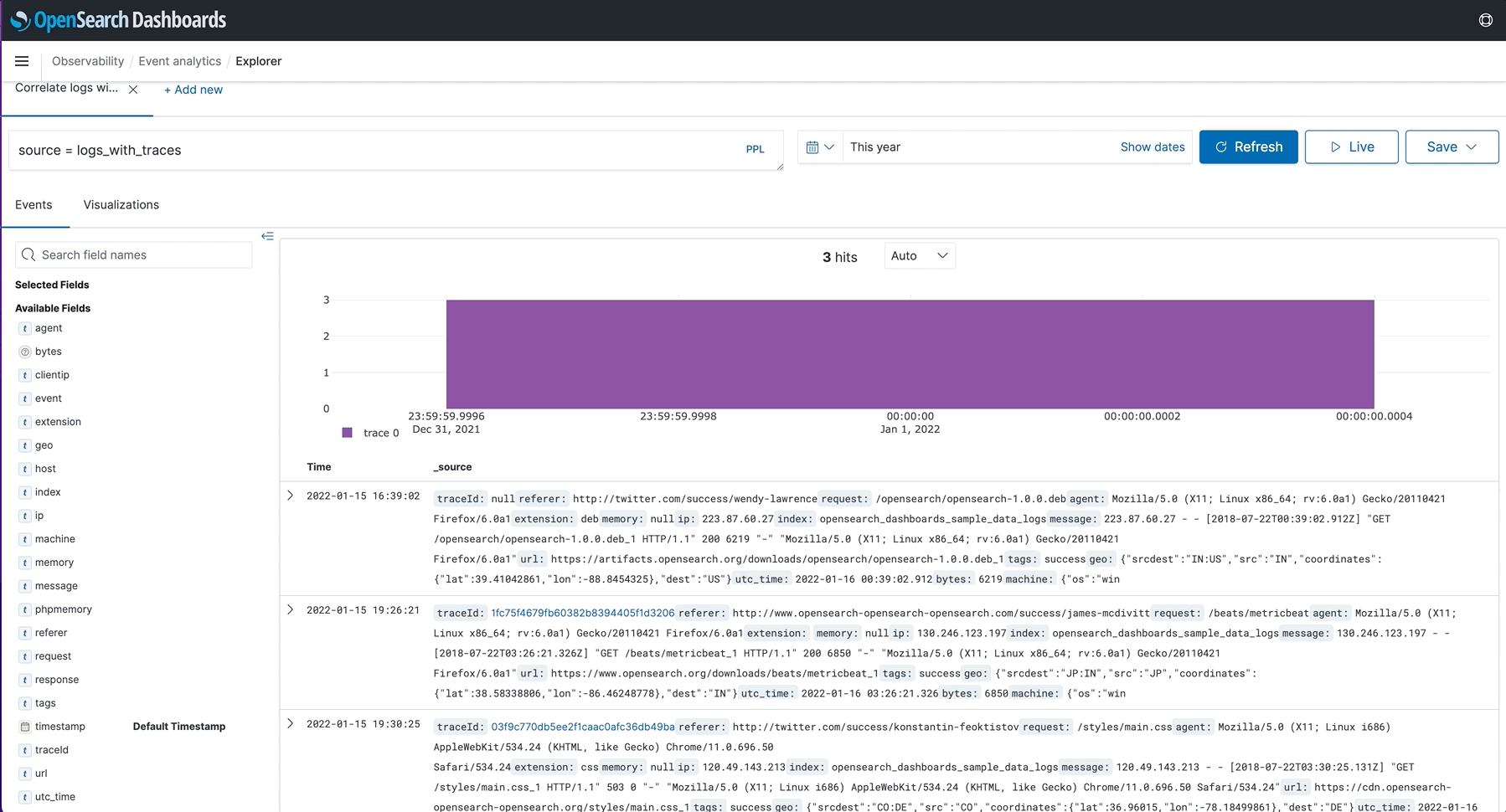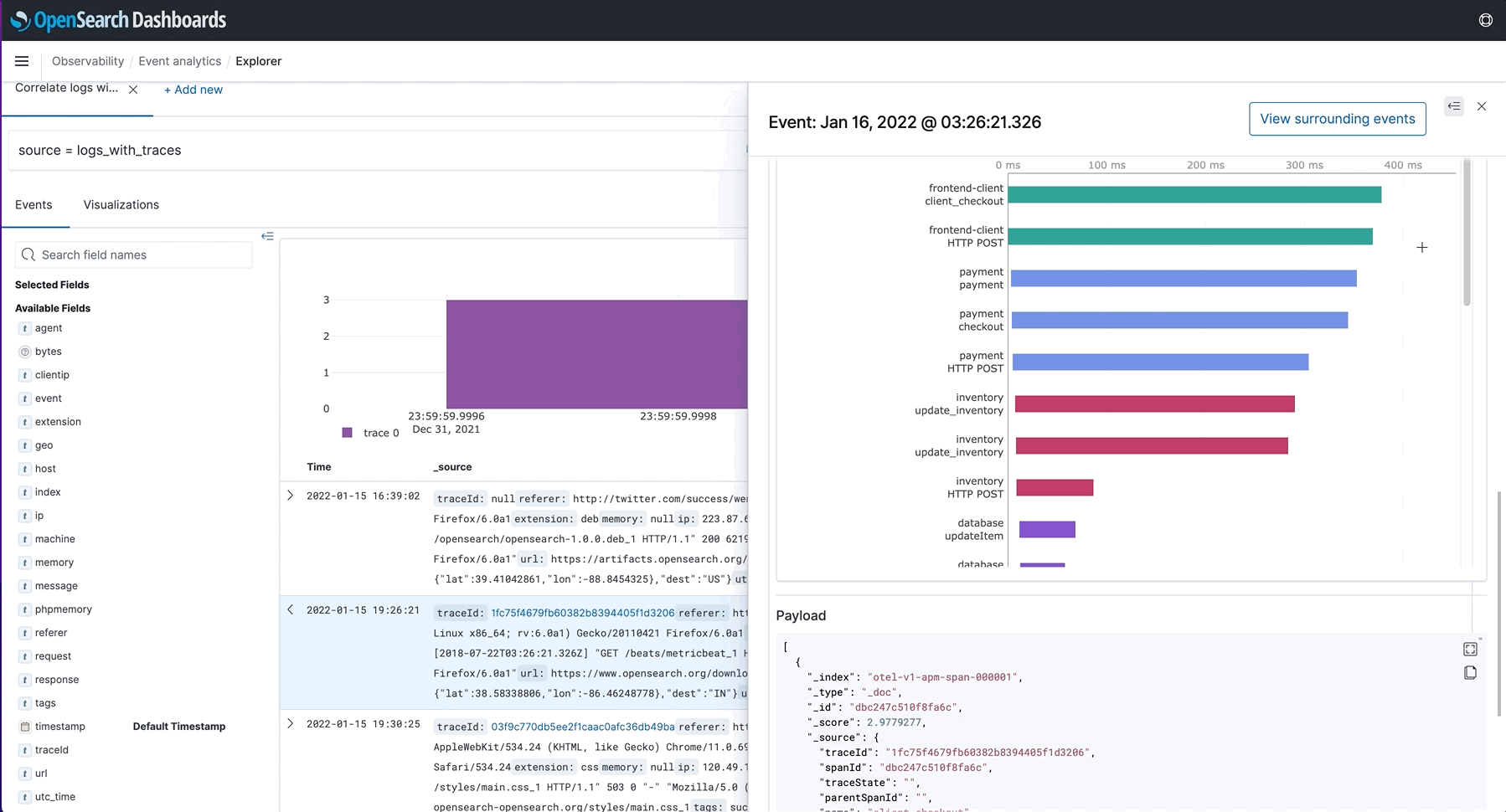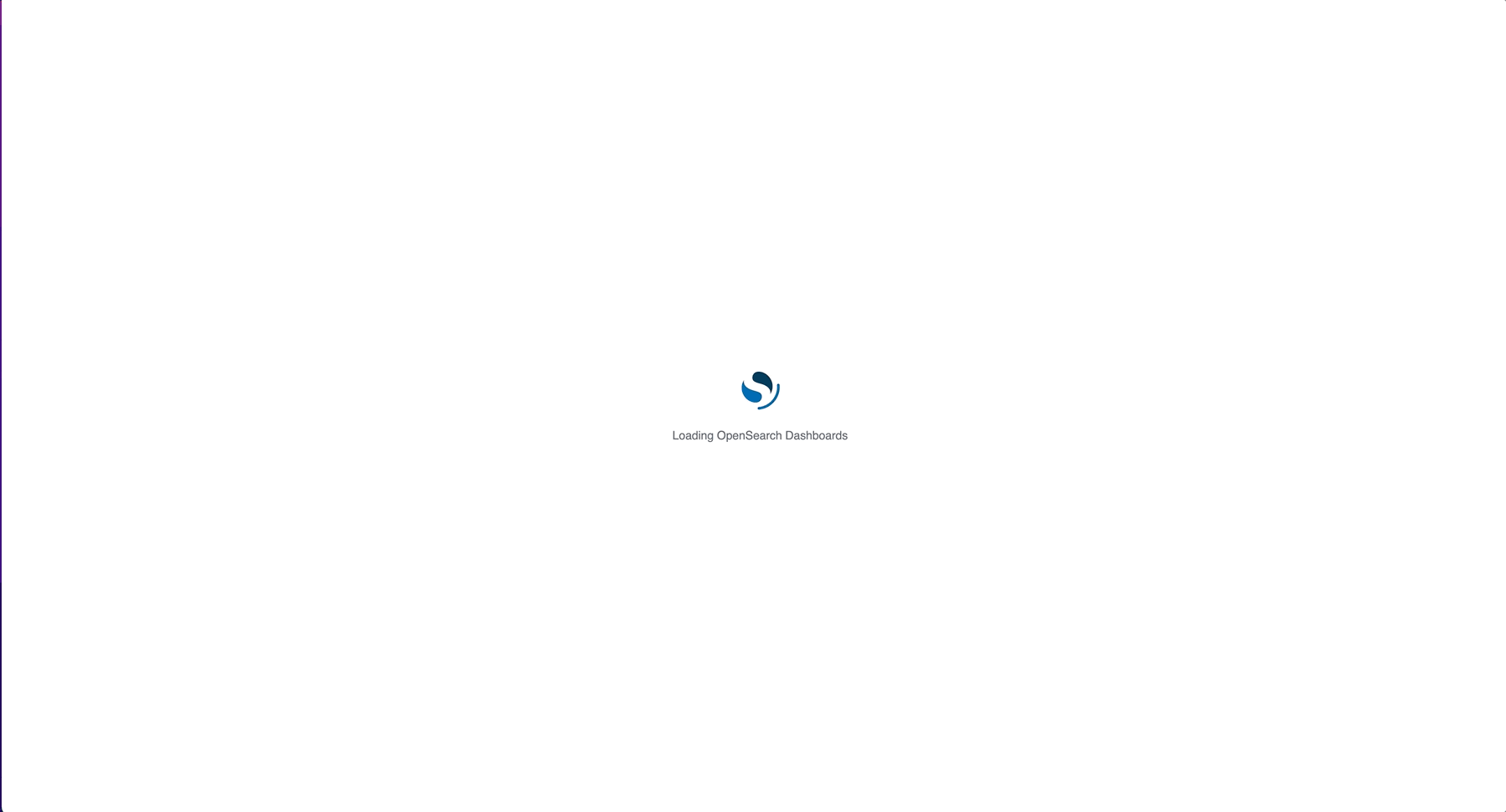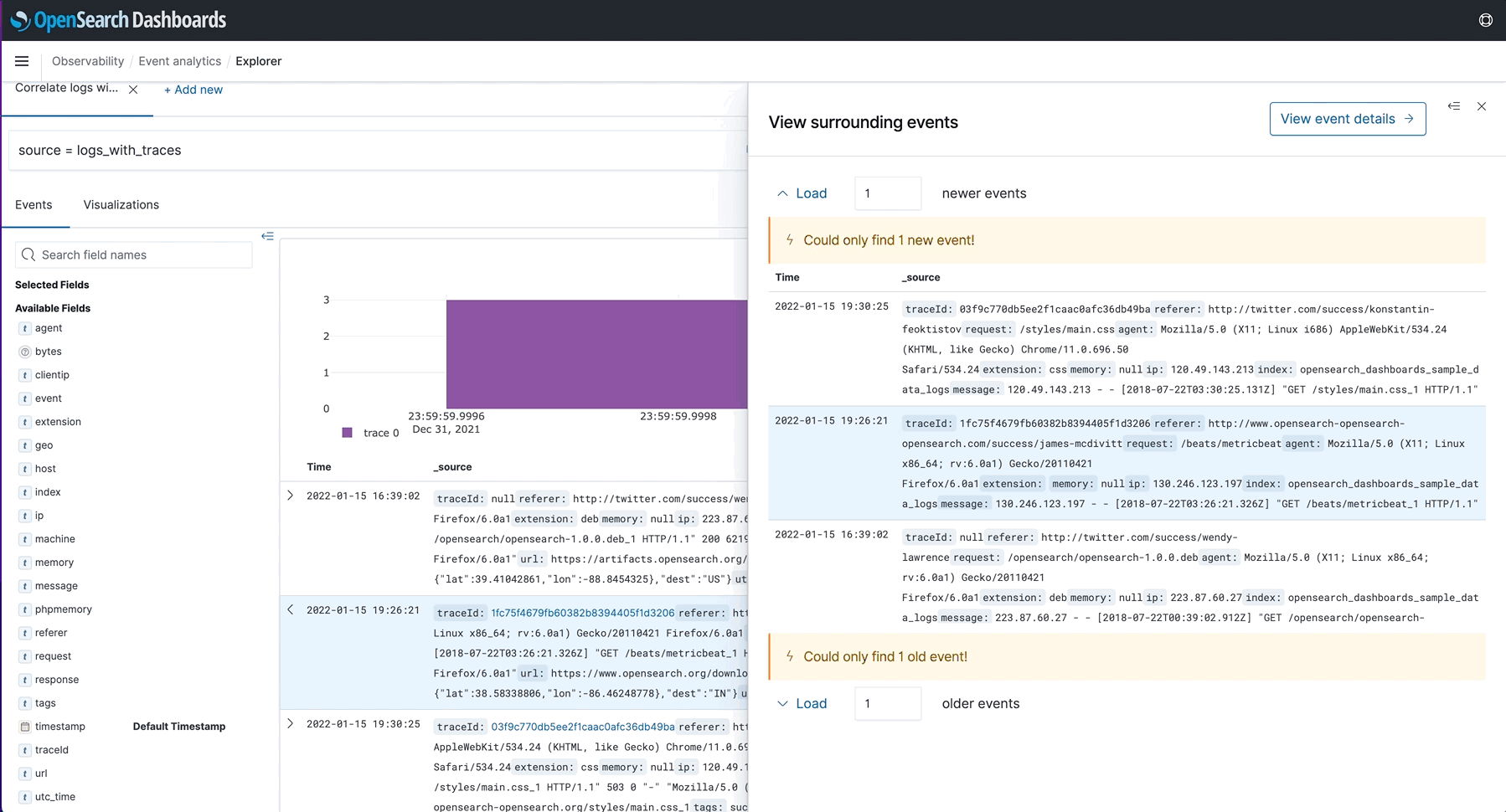
- Live Tail: Previously, when users were watching a live event take place, they had to manually refresh their view. Users can now configure the interval in which content is refreshed saving the hassle of manually refreshing.
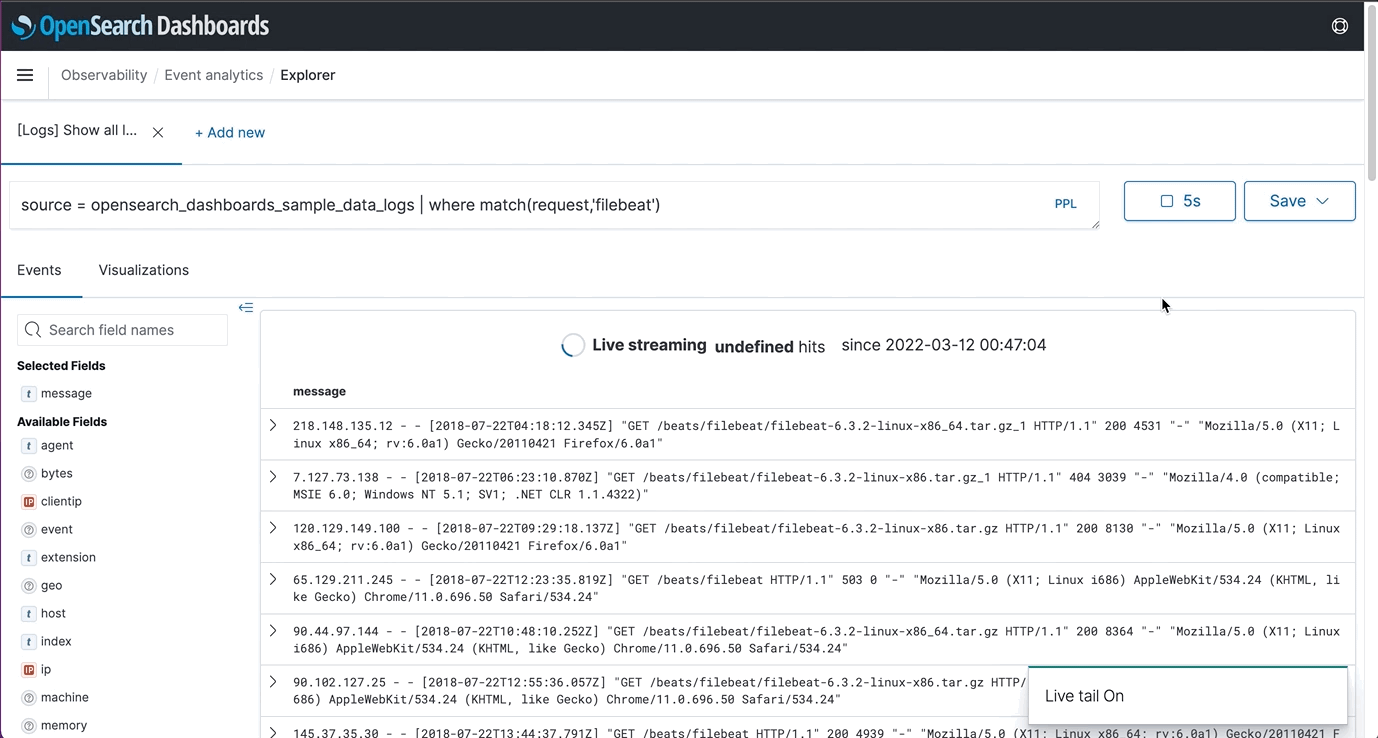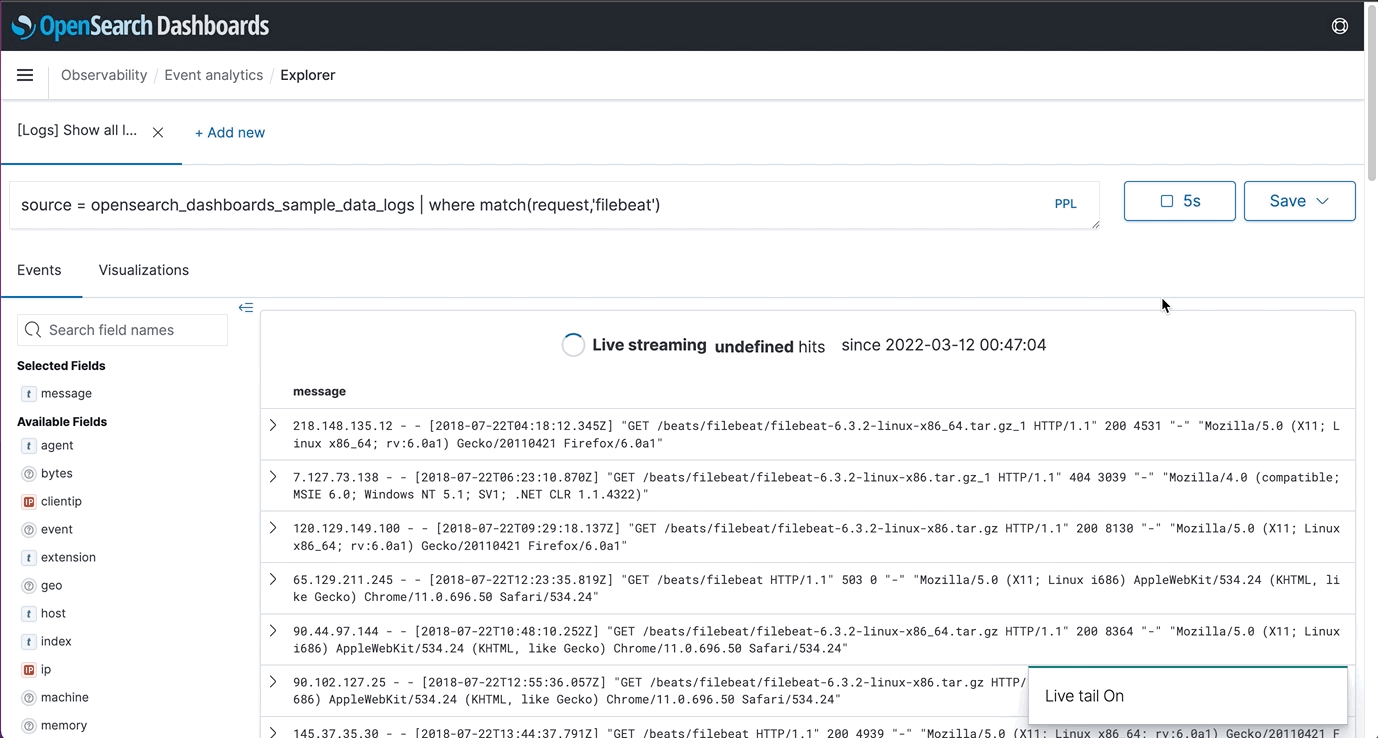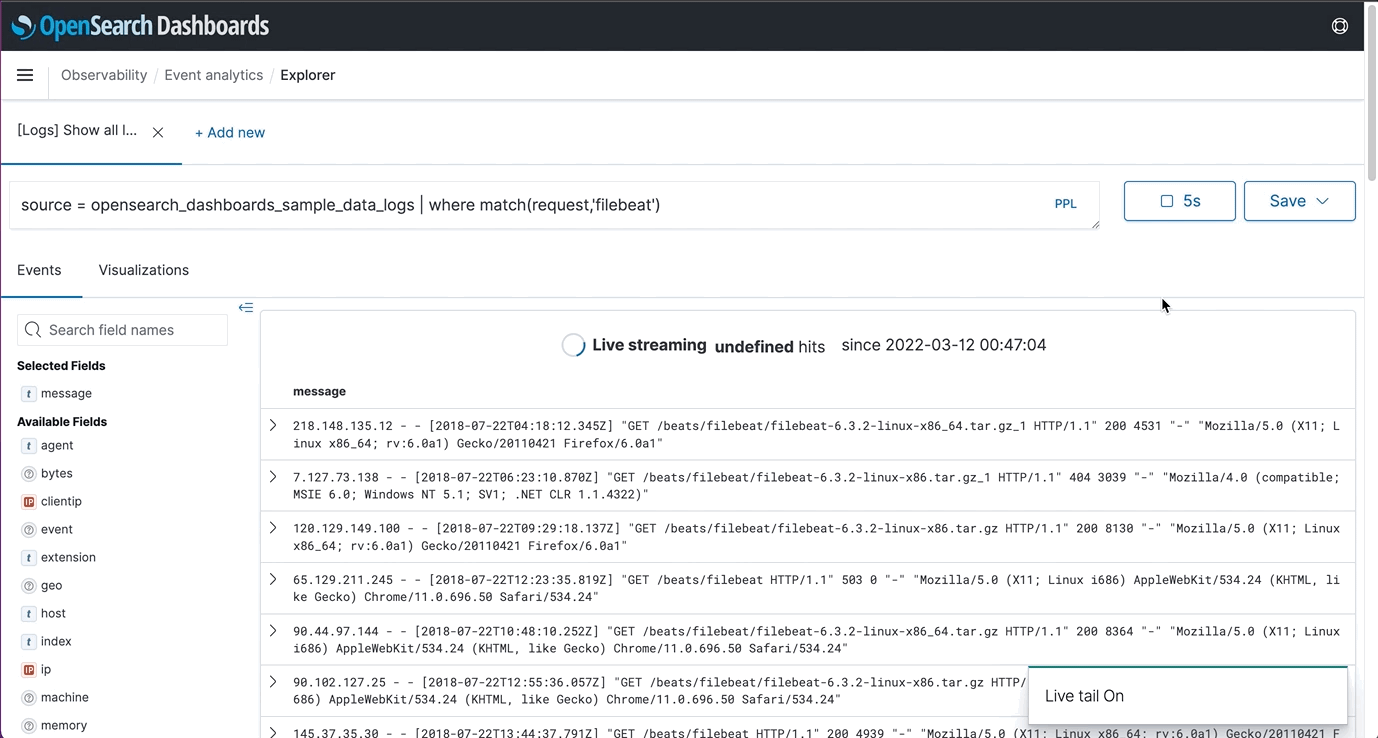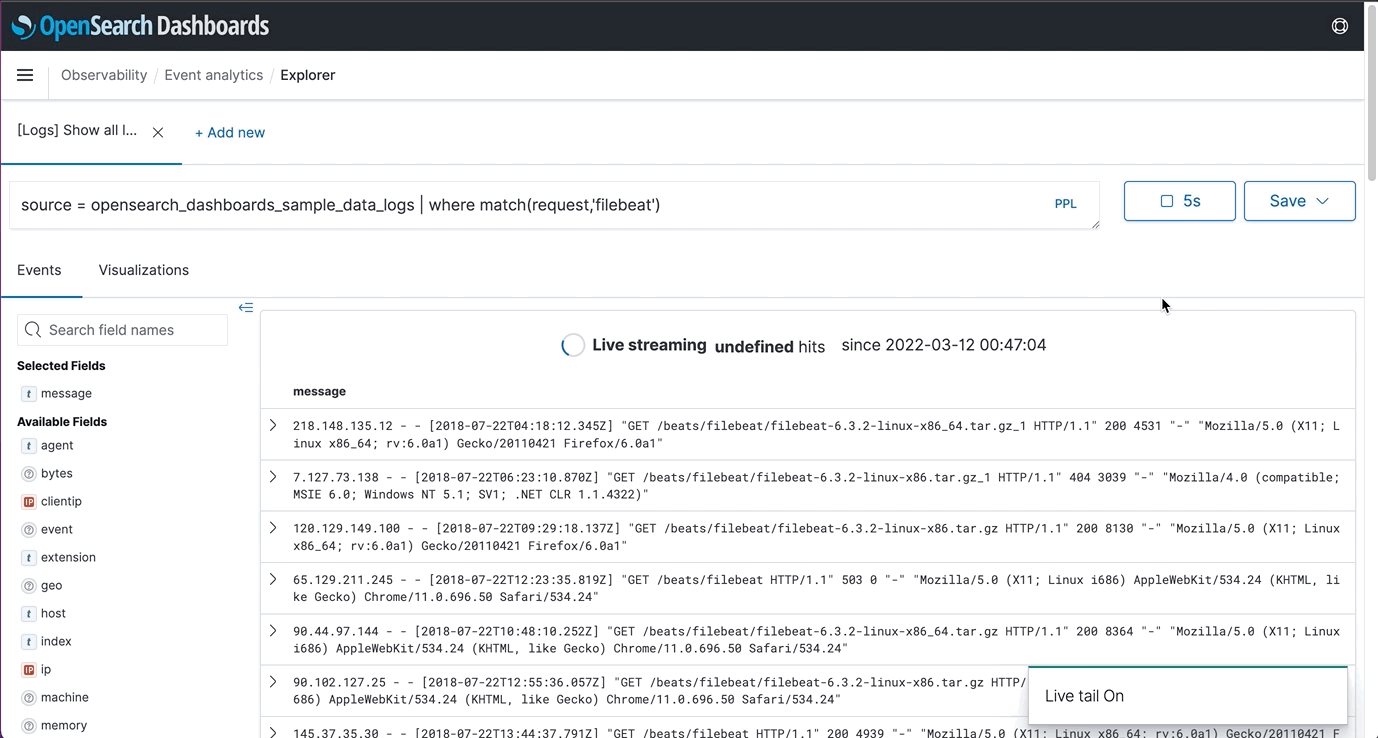
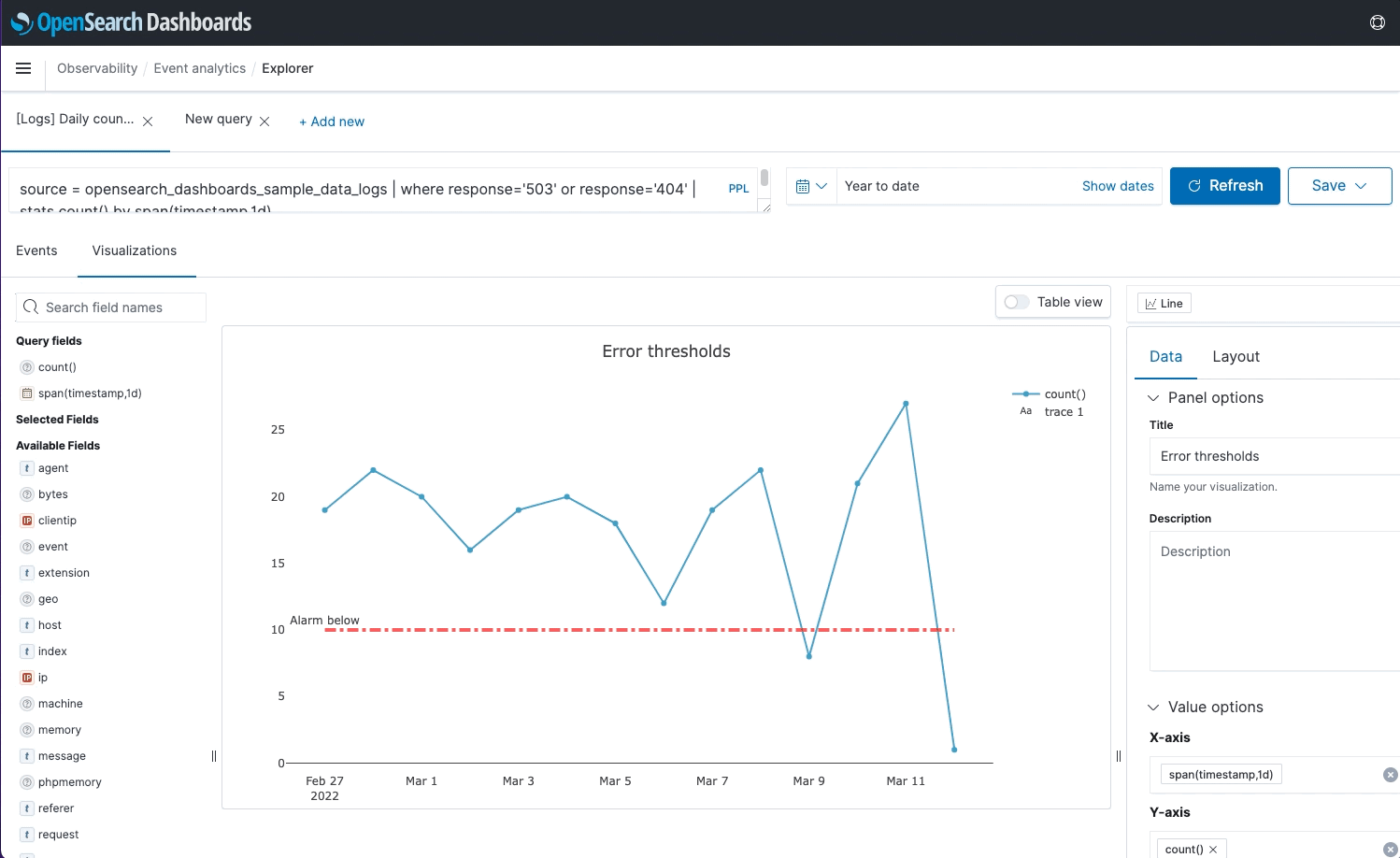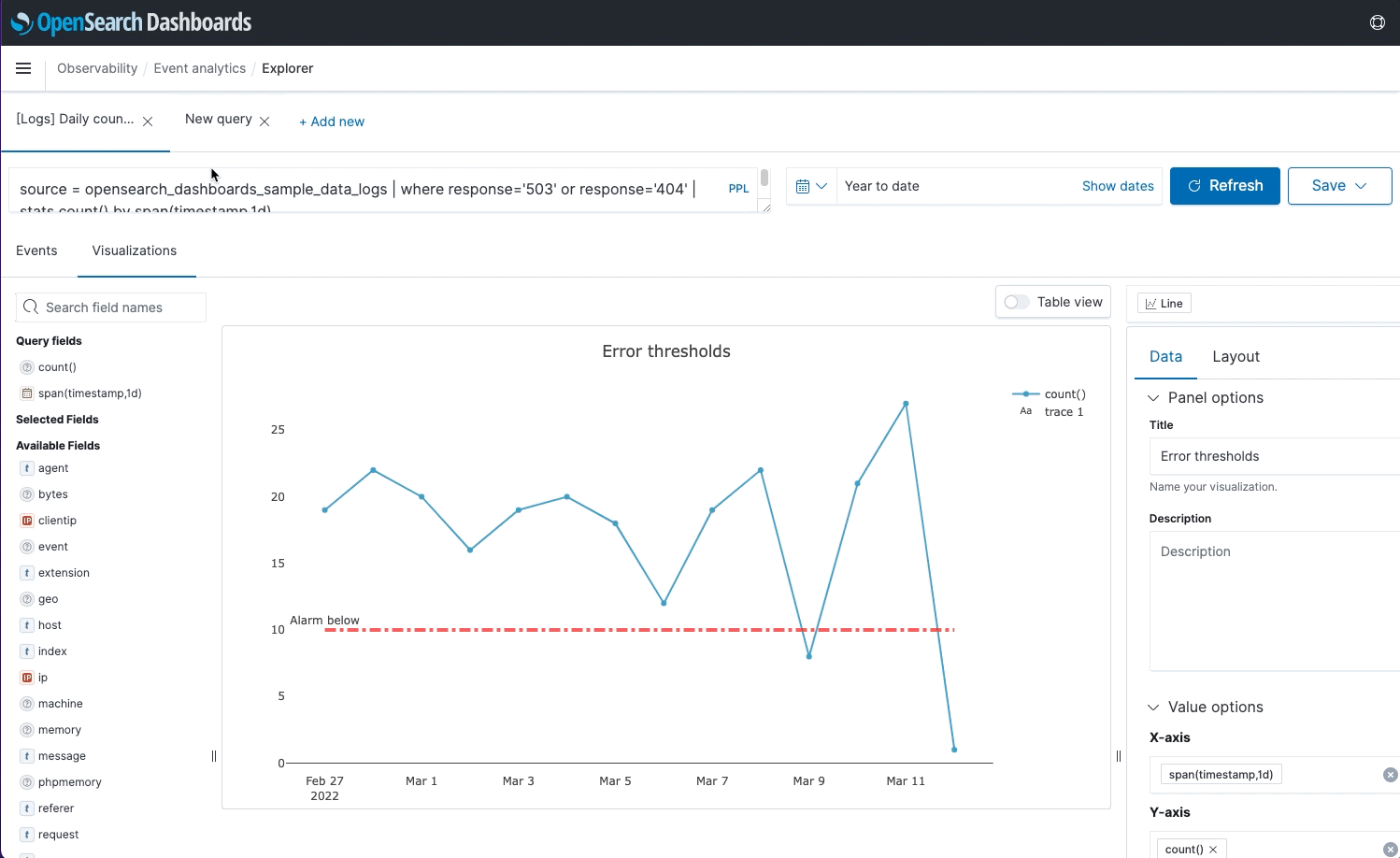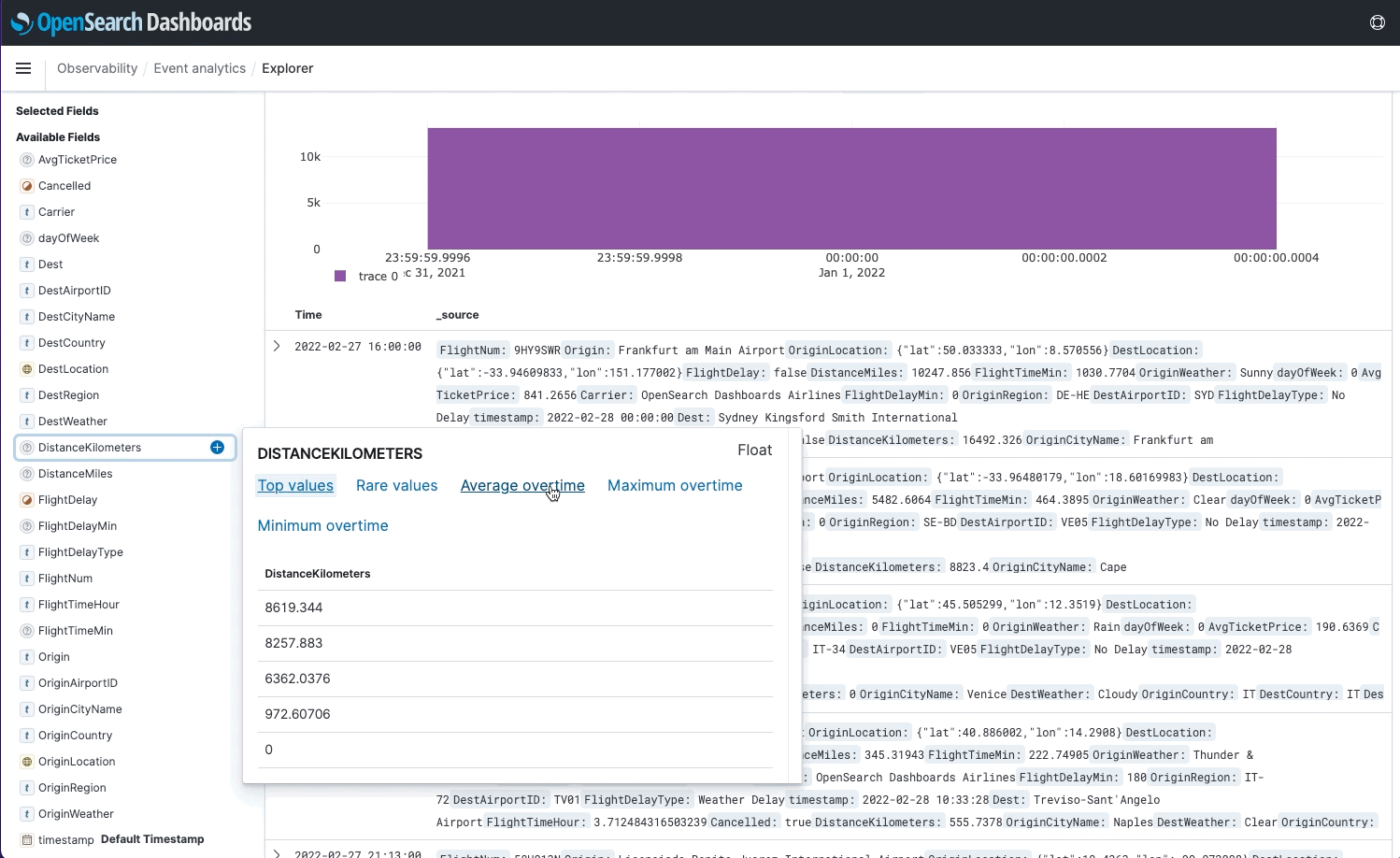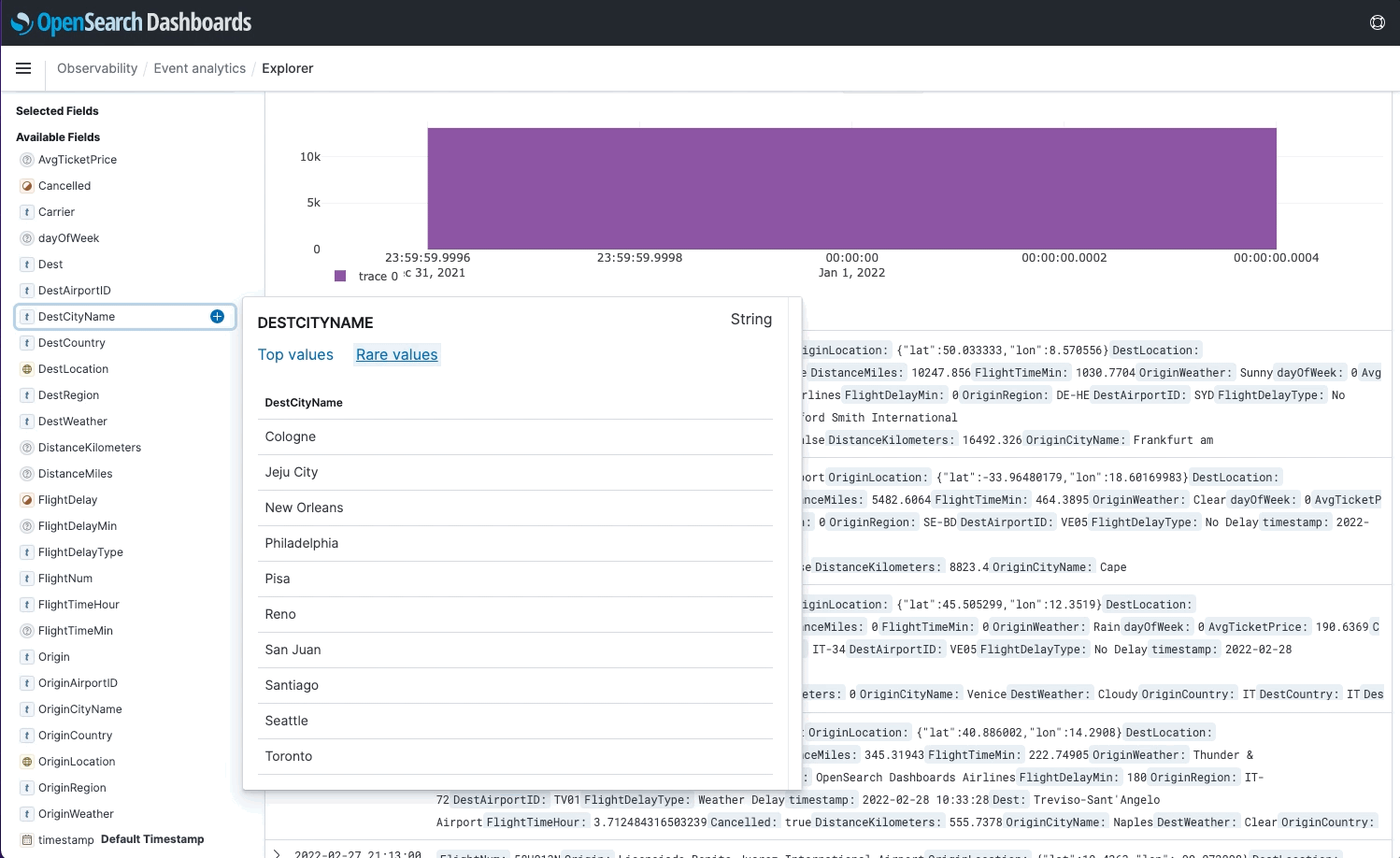
- Field Insights and Enhanced Visualization Support: Visualization types such as pie and heat maps were added as well as the ability to add named threshold markers as lines on the visualizations. When users want to know more about a metric that they are looking at, they can select “View surrounding events” to get a correlated picture. In the event a user needs a reference point for a future meeting, visualizations can now be saved to notebooks for convenience.
SQL and PPL
- PPL Runtime Fields: Users may opt out of formatting the schema upon writing the index (schema-on-write). This opt out can be used to speed up indexing time, or for additional presentation flexibility. Users who want to define their schema upon querying the index (schema-on-read), can now use regex and parse commands to further format their schema using PPL.
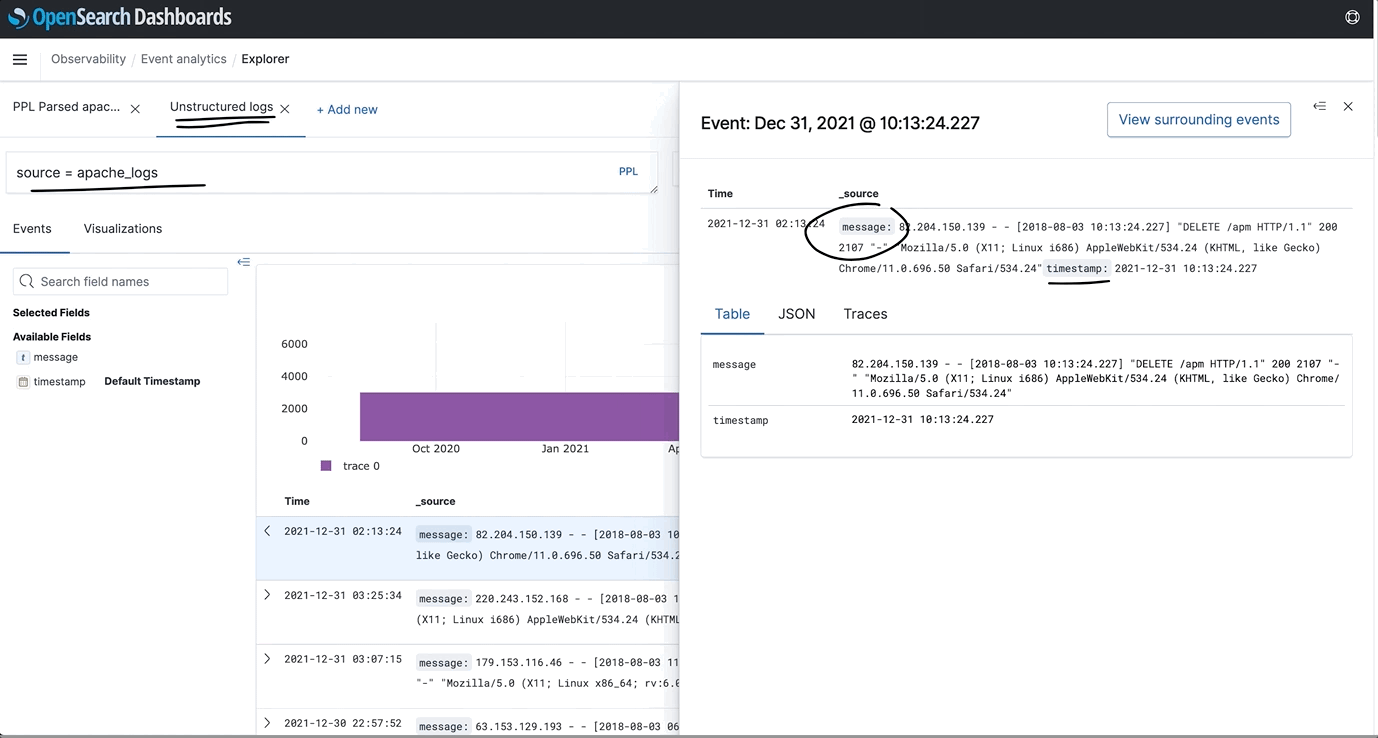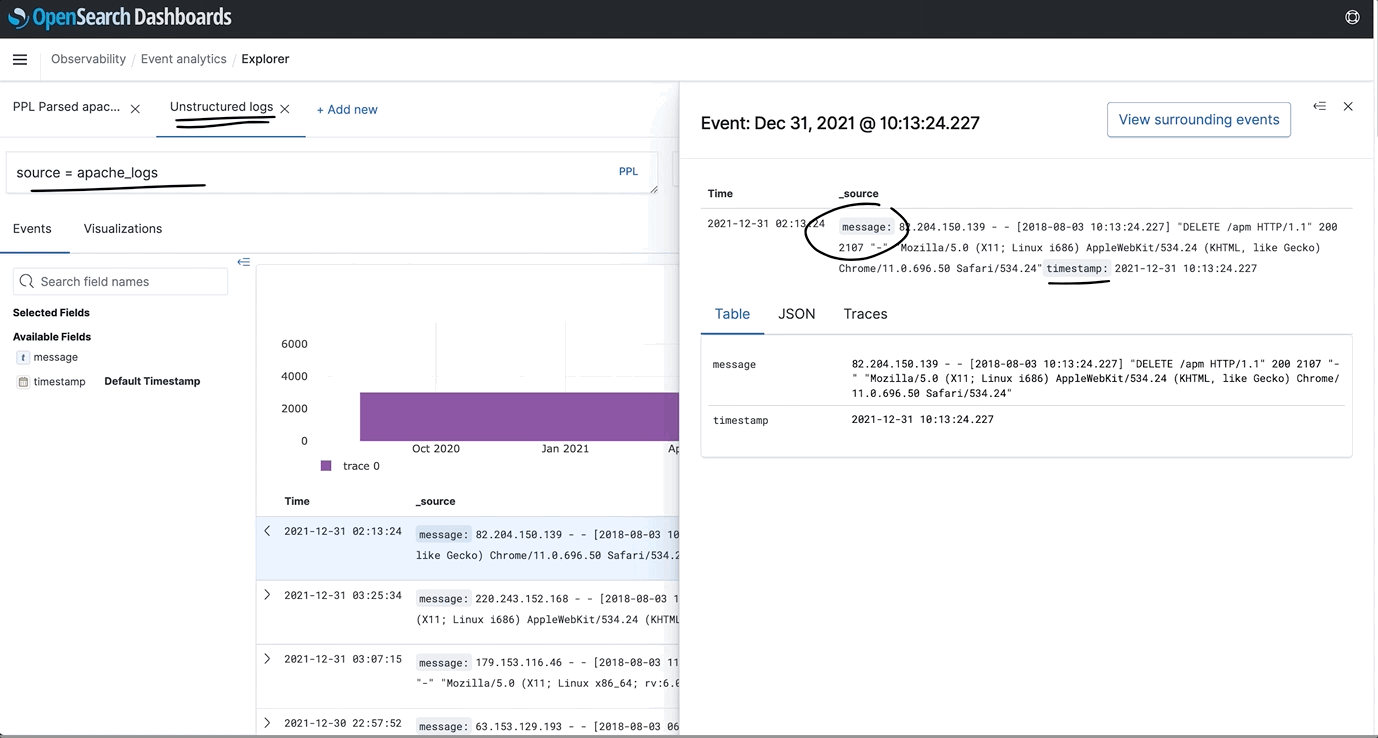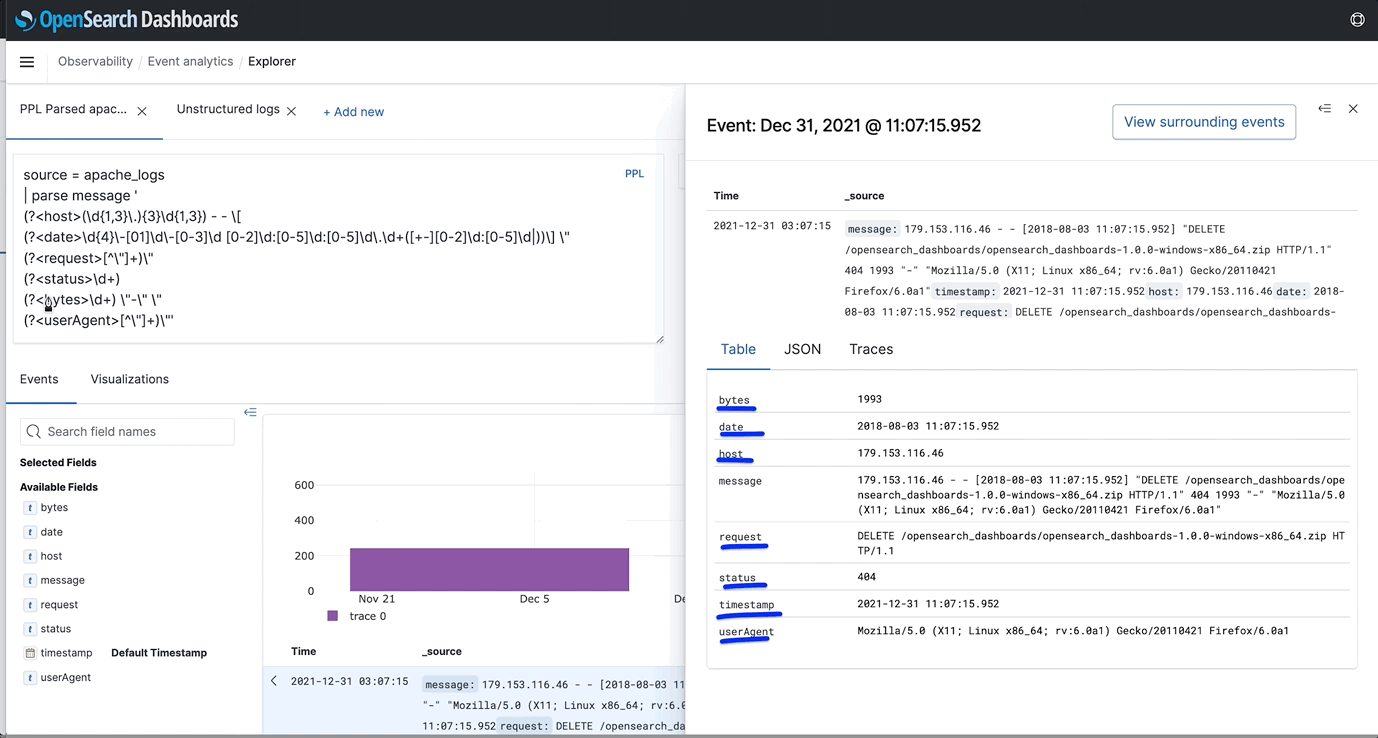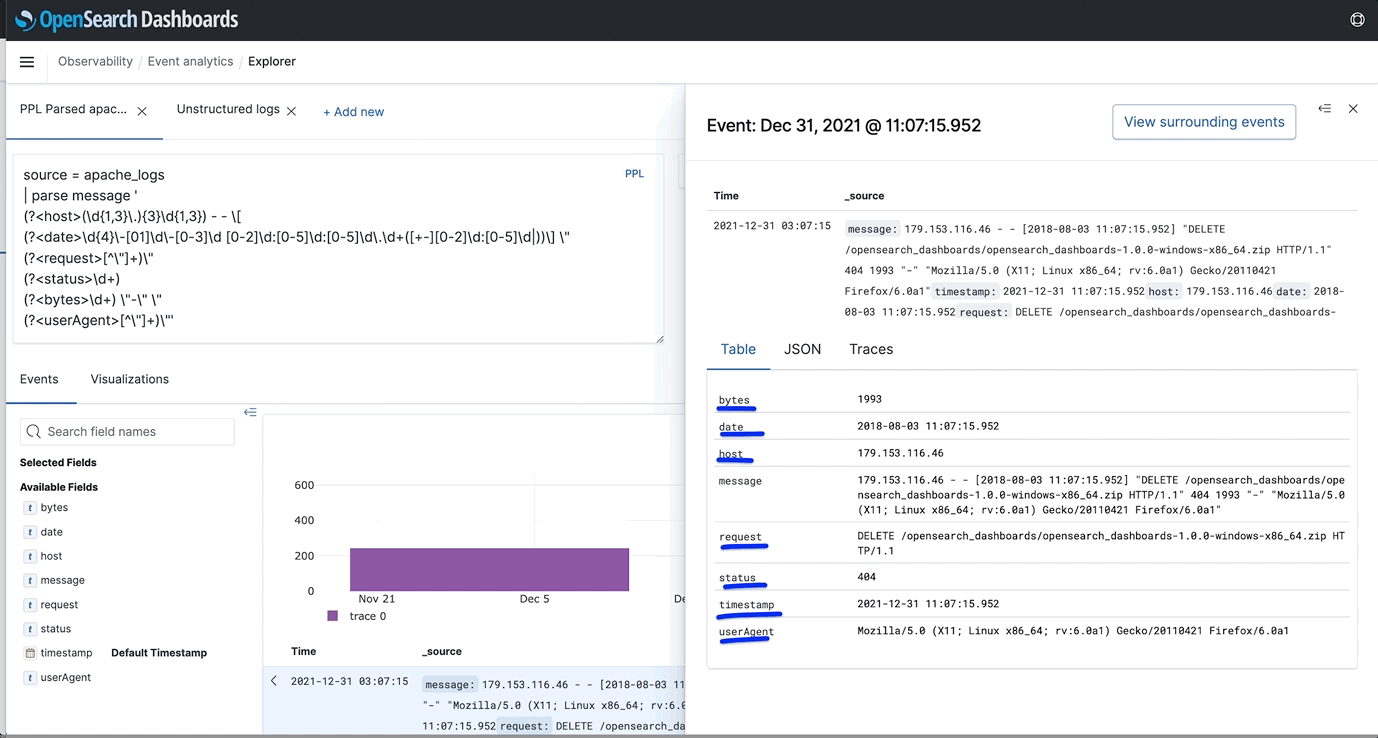
- Machine Learning Support in PPL (Piped Processing Language): Users can now process arbitrary observability events using Anomaly Detection based on Random Cut Forest (RCF) and K-means commands in PPL.
- Improved Aggregate Functions Support in SQL and PPL: Users expect to use aggregate functions in SQL and PPL. OpenSearch SQL and PPL now supports
ORDER BYand default query limit size. - Support for Group Field and Span in Stats Command: Users can now use group fields together and can span by a specified interval using the Stats command in PPL. Also, users can now create multiple time series’ with a single command.
- Comma-Separated Index Matching: Users can now query multiple indices using a comma separated value using PPL.
- CAST Function Supported in PPL: Users can now change datatypes using the
CASTfunction in PPL. - Support IN Clause in SQL and PPL: Users can now use the
INclause within SQL and PPL to select from within a value list. - Support date_nanos in SQL and PPL: Users can now search on indices with the field type of
data_nanos.
Alerting
- Cluster Metric Monitors: Users can now create monitors within Alerts which help administrators feel more confident about managing the health of their clusters. The new monitor reports on dimensions including, but not limited to CPU usage, JVM memory usage, and total number of documents coming into the cluster.
Anomaly Detection
- New Detector Validation: When setting up a new anomaly detector, the parameters specified will be validated to ensure that the criteria can initialize and that the detector will perform. The validation presented in the user interface and API will prevent detectors from being created which will not initialize.
ML Commons
- Machine Learning (ML) Commons: A new solution that makes it easy to develop new machine learning features. It allows engineers to leverage existing open source machine learning algorithms and reduce the efforts to build them from scratch. It also removes the necessity from engineers to manage the machine learning tasks which will help to speed the feature developing process.
- K-Means and Random Cut Forest Algorithm Support:
- K-means, an oft-used “clustering” algorithm, is now supported in OpenSearch.
- Random Cut Forest (RCF), an unsupervised algorithm for detecting anomalous data points within a data set, is now supported in OpenSearch..
- Both are available in ML Commons and can be accessed via the PPL user interface.
In planned future enhancements (see What’s Next, below), the OpenSearch 2.0.0 release will add distribution support for DEB X64 and RPM ARM64 in addition the those already offered.
You can keep informed about upcoming distributions on the distribution roadmap.
RPM & Debian Distributions
As of yesterday (March 16), the team identified the roadmap for 1.3.0 included references to RPM and Debian distributions. In late January, the distribution efforts started to be tracked on a separate board as distributions were decoupled from version releases. In this transition, the cards for RPM and Debian distributions were never removed from the 1.3.0 roadmap. The team regrets this error and have put measures into place to ensure that the roadmap will be more accurate moving forward.
What’s Next?
We have a number of features in-progress (see the OpenSearch Roadmap). Below we’ve highlighted a few:
- Document Returning Alerts: The new monitor type makes it easy to execute rules against log groups such as flow logs and DNS logs. Instead of a summary of the alerts triggered like in query or bucket based alerts, the monitor returns document ids for additional analysis and review.
- Search Backpressure: This feature aims to enhance the overall resiliency of OpenSearch and will introduce constructs to have fair rejections, minimize wasted work, improved search request cost estimation, and adds the ability to stabilize a cluster when under duress.
- Search Memory Tracking: The tasks framework already tracks latency and has some context about the query/work being done. The goal of this feature is to enhance this to start tracking additional stats of memory and CPU consumed per task allowing the tracking the cluster-wide resource consumption by a query.
- Drag and Drop: The new drag and drop experience will allow users of OpenSearch Dashboards to create data visualizations and gather insights without preselecting the visualization output and with the flexibility to change visualization types and index patterns on the fly.
In addition, OpenSearch 2.0.0 is already in development! The primary driver for the team to have an earlier 2.0.0 release is so that OpenSearch can get support for Lucene 9.0.0 in earlier. This change will likely enable some use of new Lucene features within the plugins, like KNN and Vector Field types. This release also allows for other breaking changes to be ready earlier, like inclusive naming. A few highlights include:
- Lucene 9.0.0: Lucene 9.0.0 includes several new features and performance improvements (Lucene 9.0.0 Documentation) that OpenSearch would like to make available to users, including K-NN support, Vectors, Big Endian, faster numeric indexing, faster sorting, concurrent merge scheduler, and prototype Java Jigsaw module support. Starting to use Lucene 9.0.0 as soon as possible is a priority. It will take a few releases to leverage the full value of it, but adding it with 2.0.0. is so exciting and has loads of potential for OpenSearch.
- Node.js Upgrade: OpenSearch Dashboards needs to upgrade the Node.js version from the current version, 10.24.1, which is no longer in support to a newer version. The target version of node for the upgrade will be v14.18.1. Node v14 which will be in LTS until 2023.
In addition to the above features, this release will replace non-inclusive terminology (e.g., master, blacklist, etc.) throughout OpenSearch with inclusive ones (e.g., leader, primary, allowlist). If you are curious, feel free to take a look at the project roadmap where you can find out the planned features and fixes with linked issues where you can provide feedback. Additionally, please take a look at the proposed 2022 release schedule.
How can you contribute?
We would love to see you contribute to OpenSearch! For almost any type of contribution, the first step is opening an issue. Even if you think you already know what the solution is, writing a description of the problem you’re trying to solve will help everyone get context when they review your pull request. If it’s truly a trivial change (e.g. spelling error), you can skip this step – but when in doubt, open an issue. If you’re excited to jump in, check out the “help wanted” tag in issues.
Do you have questions or feedback?
If you’re interested in learning more, have a specific question, or just want to provide feedback and thoughts, please visit OpenSearch.org, open an issue on GitHub, or post in the forums. There are also regular Community Meetings that include progress updates at every session and include time for Q&A.
Thank you!
From the team at the OpenSearch Project:
Thank you to all of the community members for their dedication to this open source effort. The long term goal at the outset was to collaborate with developers and build the most extensible and innovative logging and search tool in the world. That singular mission has not changed, and we could not do it without input and contribution from the open source community. A tip of the hat to you all; you’re a critical component for our mission to succeed!



