
Metarank is an open-source secondary ranker that can perform advanced search results by reordering the results with a LambdaMART learning to rank (LTR) model. In this post, we’ll discuss why and when an LTR approach to ranking may be helpful and how Metarank implements LTR on top of OpenSearch.
Ranking in Lucene and OpenSearch
OpenSearch, being a close relative to the Apache Lucene project, uses a traditional approach to search results ordering:
- In the retrieval stage, Lucene builds a result set of all the documents matching the query from the inverted index within each shard.
- In the per-shard scoring stage, a BM25 scoring function scores each document and orders them accordingly.
- In the collection stage, each per-shard list of scored documents merges together in a final sequence of top-N matching documents.
BM25 is a strong baseline for text relevance, but it only takes into account frequencies of terms in the query and some basic statistics on the collection of documents in the index. A more intuitive overview of the logical parts of BM25 formula is shown in the following diagram, taken from Lectures 17-18 of the Text Technologies for Data Science (TTSDS) course at the University of Edinburgh.

The BM25 scoring function can typically be applied to all documents in the result set, so running the function should not become a CPU bottleneck on large sets.
But in common use cases like e-commerce, term frequencies and index statistics are not the only factors affecting relevance. For example, using implicit visitor behavior and item metadata may improve relevance, but these metadata factors should be included in the scoring function.
OpenSearch provides a custom scoring function through the script_score query:
GET /_search
{
"query": {
"script_score": {
"query": {
"match": { "message": "socks" }
},
"script": {
"source": "doc['click_count'].value * _score"
}
}
}
}
In the example above, the function multiplies the BM25 score from the stored column and the per-document number of clicks, click_count, this document receives. With this approach, you can:
- Use item metadata from stored fields in the ranking, for example, item price.
- Put external ranking factors into the scoring function, like having a separate set of weights for mobile and desktop visitors.
But the script_score approach also has a set of important drawbacks:
- Because the scoring function is invoked on each matching document, you cannot perform any complex computations inside the document.
- Because no common scoring formula exists, you have to invent your own scoring function.
- Because scoring formulas typically have a set of constants and weights, you have to choose the best values for parameters.
- Feature values used in the ranking formula should be either stored in the index, which requires frequent full reindexing, or served outside the search, which requires a custom satellite Feature Store.
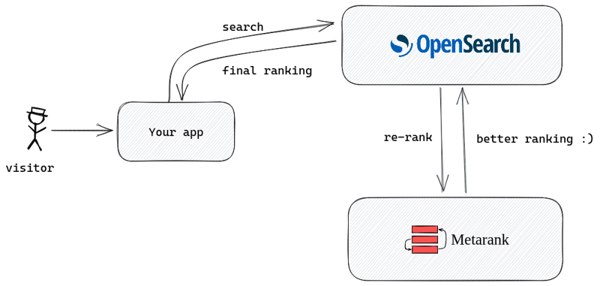
Secondary re-ranking
However, another approach to ranking exists: secondary/multi-level re-ranking. Secondary ranking splits the retrieval and multiple re-ranking phases into independent steps:
- The first-level index retrieves a full set of results without any extra ranking at all.
- The second-level fast rankers like BM25 perform an initial scoring to reduce the number of matching documents to a top-N most relevant document, focusing on recall metrics.
- Finally, the third-level slow ranker reorders only the top-N candidates into the final ranking, focusing on a precision metric.
This approach is widespread in the industry. For a good overview, watch a talk Berlin Buzzwords 2019: Michael Sokolov & Mike McCandless–E-Commerce search at scale on Apache Lucene on how multi-stage ranking is implemented on amazon.com.

Multi-level ranking also comes with a set of tradeoffs:
- It operates only on top-N candidates, so if your first-level ranker under-scored a document that wasn’t included in the top-N set, it may be missing from the final ranking.
- You might have been forced to build a multi-stage system in house because, before now, there were no open-source solutions for this multi-level ranking.
But because final re-ranking happens outside your search application and happens only on a top-N subset of documents, you can implement complex LTR algorithms like LambdaMART.
Metarank
Metarank is an open-source secondary re-ranker that:
- Implements LambdaMART on top of the embedded feature engineering pipeline. A couple of other ranking model implementations, like BPR and BERT4Rec, are on the roadmap.
- Contains a YAML DSL query that defines ranking factors such as rates, counters, windows, and UA/Referer/GeoIP parsers.
As a secondary re-ranker, it’s agnostic to the way you perform the candidate retrieval. It should be integrated with your app, not the search engine.
Metarank’s ranking predictions are based on past historical click-through events. These events are analyzed, aggregated into a set of implicit judgments, and later used to train the machine learning (ML) model. Finally, in the real-time inference stage, the model tries to predict the best ranking based on past visitor behavior.
Preparing historical events
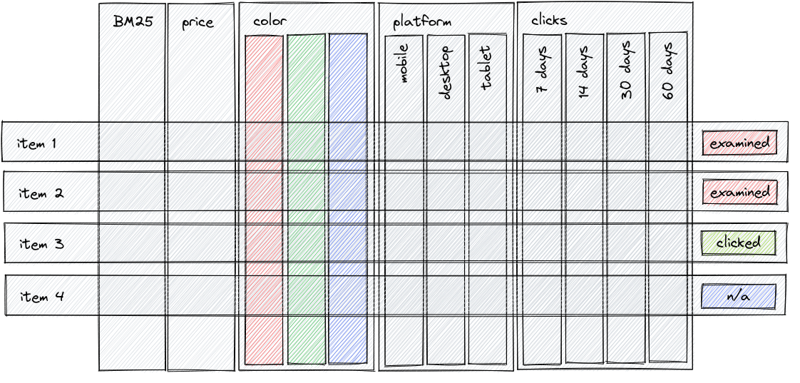
Metarank uses historical click-through events as an ML training dataset, looking at parameters such as:
- What visitor or item-specific information was updated, like item price, tags, and CRM visitor profile.
{
"event": "item",
"id": "81f46c34-a4bb-469c-8708-f8127cd67d27",
"item": "product1",
"timestamp": "1599391467000",
"fields": [
{"name": "title", "value": "Nice jeans"},
{"name": "price", "value": 25.0},
{"name": "color", "value": ["blue", "black"]},
{"name": "availability", "value": true}
]
}
- Impression: How and when a visitor accessed an item listing. For example, impression measures the relevancy of search results, collections, or recommendation widgets.
{
"event": "ranking",
"id": "81f46c34-a4bb-469c-8708-f8127cd67d27",
"timestamp": "1599391467000",
"user": "user1",
"session": "session1",
"fields": [
{"name": "query", "value": "socks"}
],
"items": [
{"id": "item3", "relevancy": 2.0},
{"id": "item1", "relevancy": 1.0},
{"id": "item2", "relevancy": 0.5}
]
}
- Interaction: How a visitor interacted with an item from the list, for example, click, add-to-cart, or a mouse hover.
{
"event": "interaction",
"id": "0f4c0036-04fb-4409-b2c6-7163a59f6b7d",
"impression": "81f46c34-a4bb-469c-8708-f8127cd67d27",
"timestamp": "1599391467000",
"user": "user1",
"session": "session1",
"type": "purchase",
"item": "item1",
"fields": [
{"name": "count", "value": 1},
{"name": "shipping", "value": "DHL"}
],
}
Mapping events to ranking factors
Metarank has a rich DSL, which can help you map feedback events to the actual numerical ranking factors. Apart from some simple cases, like directly using item metadata numerical fields, Metarank can also handle complex ML features.
You can perform a one-hot/label encoding of low-cardinality string fields:
- name: genre
type: string
scope: item
source: item.genre
values:
- comedy
- drama
- action
Extract and one-hot encode a mobile/desktop/tablet category from the User-Agent field:
- name: platform
type: ua
field: platform
source: ranking.ua
Perform a sliding window count of interaction events for a particular item:
- name: item_click_count
type: window_count
interaction: click
scope: item
bucket_size: 24h // make a counter for each 24h rolling window
windows: [7, 14, 30, 60] // on each refresh, aggregate to 1-2-4-8 week counts
refresh: 1h
Or see rates for each item:
- name: CTR
type: rate
top: click // divide number of clicks
bottom: impression // to number of examine events
scope: item
bucket: 24h // aggregate over 24-hour buckets
periods: [7, 14, 30, 60] // sum buckets for multiple time ranges
There are many more feature extractors available, so check the Metarank docs for other examples and a more detailed quickstart guide.
These feature extractors map events into numerical features and form a set of implicit judgments, which are later used for ML model training.
Sending requests
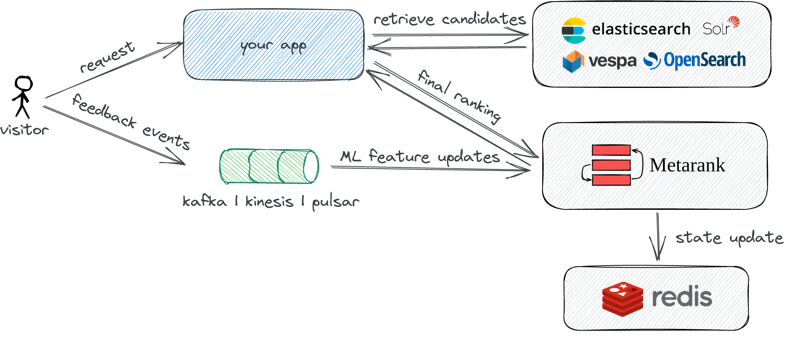
To integrate LTR between search applications, OpenSearch and Metarank require a couple of additions to your current setup:
-
- It’s time to start collecting visitor feedback events if you’re not yet doing so. You can either roll your own or use existing open-source telemetry collectors like Snowplow Analytics.
- Metarank uses Redis as a state store. The Redis node sizing usually depends on your ML feature setup and number of users. You can check the Metarank RAM usage benchmark for ballpark estimations for your use case.
- After receiving a response with top-N candidates from OpenSearch, you need to send an extra request to Metarank to perform re-ranking.
An example re-ranking request is the same as the ranking event above:
{
"event": "ranking",
"id": "id1",
"items": [
{"id":"72998"}, {"id":"67197"}, {"id":"77561"}, {"id":"68358"},
{"id":"72378"}, {"id":"85131"}, {"id":"94864"}, {"id":"68791"},
{"id":"109487"}, {"id":"59315"}, {"id":"120466"}, {"id":"90405"},
{"id":"117529"}, {"id":"130490"}, {"id":"92420"}, {"id":"122882"},
{"id":"113345"}, {"id":"2571"}, {"id":"122900"}, {"id":"88744"},
{"id":"95875"}, {"id":"60069"}, {"id":"2021"}, {"id":"135567"},
{"id":"122902"}, {"id":"104243"}, {"id":"112852"}, {"id":"102880"},
{"id":"96610"}, {"id":"741"}, {"id":"166528"}, {"id":"164179"},
{"id":"71057"}, {"id":"3527"}, {"id":"6365"}, {"id":"6934"},
{"id":"114935"}, {"id":"8810"}, {"id":"173291"}, {"id":"1580"},
{"id":"1917"}, {"id":"135569"}, {"id":"106920"}, {"id":"1240"},
{"id":"85056"}, {"id":"780"}, {"id":"1527"}, {"id":"5459"},
{"id":"8644"}, {"id":"60684"}, {"id":"7254"}, {"id":"44191"},
{"id":"97752"}, {"id":"2628"}, {"id":"541"}, {"id":"106002"},
{"id":"2012"}, {"id":"79357"}, {"id":"6283"}, {"id":"113741"},
{"id":"27660"}, {"id":"34048"}, {"id":"1882"}, {"id":"1748"},
{"id":"34319"}, {"id":"1097"}, {"id":"115713"}, {"id":"2916"}
],
"user": "alice",
"session": "alice1",
"timestamp": 1661345221008
}
Metarank will respond with the same set of requested items, but in another ordering:
{
"items": [
{"item": "1580", "score": 3.345952033996582},
{"item": "5459", "score": 2.873959541320801},
{"item": "8644", "score": 2.500633478164673},
{"item": "56174", "score": 2.2979140281677246},
{"item": "2571", "score": 2.0133864879608154},
{"item": "1270", "score": 1.807900071144104},
{"item": "109487", "score": 1.7143194675445557},
{"item": "589", "score": 1.706472396850586},
{"item": "780", "score": 1.7030035257339478},
{"item": "1527", "score": 1.6445566415786743},
{"item": "60069", "score": 1.6372750997543335},
{"item": "1917", "score": 1.6299139261245728}
]
}
Re-ranking latency
The main drawback of secondary re-ranking is extra latency: Apart from the initial search request, you need to perform an extra network call to the ranker. Metarank is no exception, and latency depends on the following things:
- State encoding format: Metarank can store aggregated user and item state in JSON format in Redis, but it takes more memory and is much slower to encode-decode than a custom binary format.
- Network latency between Metarank and Redis: Metarank pulls all features for all re-ranked items in a single large batch request. There are no multiple network calls and only a constant overhead.
- Request size: The more items you ask to re-rank, the more data needs to be loaded.
- Number of features used: The more per-item features that are defined in the config, the more data that is loaded during the request processing.
Based on a RankLens dataset, you can build a latency benchmark to measure a typical request processing time, dependent on the request size.
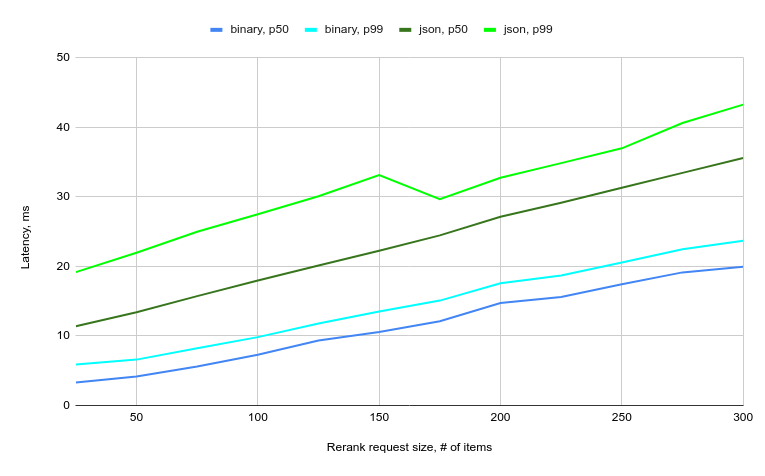
So while planning your installation, expect Metarank to have an extra 20–30ms latency budget.
OpenSearch Remote Ranker Plugin RFC
OpenSearch Project maintainers are currently discussing a new approach for a better and more flexible re-ranking framework: [RFC] OpenSearch Remote Ranker Plugin (semantic).
The main idea is that the OpenSearch Project will:
- Define the common ranking API and handle the re-ranking process internally; there will be no need to send multiple queries from the application to different backends.
- Implement this common API across multiple rankers, which can be hot-swappable and does not require modifying application code while reimplementing.
To quote the original RFC:
The OpenSearch Semantic Ranker is a plugin that will re-rank search results at search time by calling an external service with semantic search capabilities for improved accuracy and relevance. This plugin will make it easier for OpenSearch users to quickly and easily connect with a service of their choice to improve search results in their applications.
The plugin will modify the OpenSearch query flow and do the following:
- Get top-N BM25-scored document results from each shard of the OpenSearch index.
- Preprocess document results and prepare them to be sent to an external “re-ranking” service.
- Call the external service that uses semantic search models to re-rank the results.
- Collect per-shard results into the final top-N ranking.
Metarank developers are already collaborating with the OpenSearch team on this proposal and plan to support the Remote Ranker Plugin API when it is released.
