
Building effective AI agents requires more than just powerful language models—it demands the ability to remember and learn from past interactions. OpenSearch 3.3 introduces agentic memory, a comprehensive persistent memory system that enables AI agents to maintain context, extract knowledge, and build understanding across conversations using OpenSearch’s proven search and storage infrastructure.
In this blog post, we’ll explore the memory challenges facing AI agents, introduce agentic memory’s core concepts, and demonstrate how to integrate it with your agent frameworks.
Memory challenges in AI agent development
Effective AI agents need more than just language understanding—they require the ability to maintain context and learn from interactions over time. Current AI systems process each conversation independently, lacking the persistent memory that enables meaningful, evolving relationships with users.
Developers building AI agents face several technical challenges when implementing memory capabilities:
Token limit management: Large language models (LLMs) have finite context windows, requiring developers to implement strategies for managing conversation history within processing limits.
Custom infrastructure overhead: Without dedicated memory solutions, teams often build bespoke systems for storing conversation data, user preferences, and agent state, duplicating effort across projects.
Intelligent retrieval complexity: Raw conversation storage alone isn’t sufficient. Developers need sophisticated systems to extract meaningful insights and surface relevant information contextually.
Storage without understanding: Traditional approaches focus on data persistence rather than intelligent memory formation, lacking built-in capabilities to identify and extract valuable patterns from interactions.
These technical limitations create user experience problems:
- Financial advisors losing track of client investment goals discussed in previous sessions.
- Coding assistants forgetting established development preferences and project contexts.
- Customer service agents requiring users to repeat information shared in earlier interactions.
Without effective memory systems, AI conversations remain fragmented rather than building meaningful, continuous relationships.
The following image illustrates the difference between agents operating without persistent memory and those enhanced with comprehensive memory capabilities.
 Introducing OpenSearch agentic memory
Introducing OpenSearch agentic memory
OpenSearch agentic memory addresses these challenges by providing a comprehensive memory management system built on OpenSearch’s proven search and storage infrastructure. This solution enables AI agents to maintain both immediate conversational context and persistent knowledge across interactions, creating more intelligent and personalized user experiences.
The system is designed around several core principles:
Unified platform approach: Use existing OpenSearch infrastructure for both search workloads and agent memory, reducing operational complexity and infrastructure costs.
Intelligent processing capabilities: Configurable strategies automatically extract insights, preferences, and summaries from raw conversations using integrated LLM processing.
Framework flexibility: REST API design enables integration with any agent framework or custom implementation without vendor dependencies.
Hierarchical organization: Namespace-based memory organization provides structured access control and efficient retrieval for multi-user, multi-agent environments.
Production scalability: Built on OpenSearch’s distributed architecture in order to handle enterprise-scale memory workloads with consistent performance.
Core components of agentic memory
OpenSearch agentic memory consists of several key components that work together to provide both short-term context and long-term intelligence for your agents.
The following image shows the OpenSearch agentic memory architecture and how these components interact within the agentic memory system.
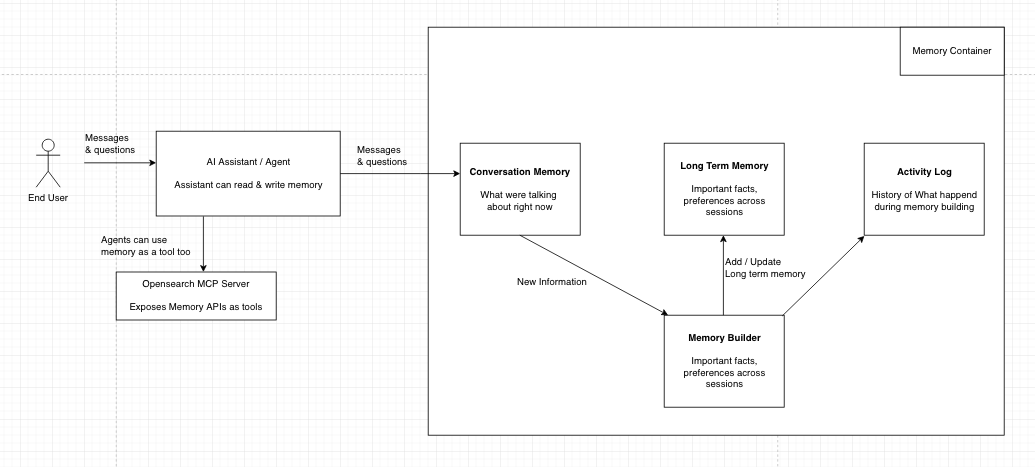 Memory containers
Memory containers
A memory container is a logical container that holds all memory types for a specific use case, such as a chatbot, research assistant, or customer service agent. Each container can be configured with:
- Text embedding models: For semantic search capabilities across stored memories.
- LLMs: For intelligent knowledge extraction and processing in long-term memory.
- Memory processing strategies: For defining how long-term memories are processed and organized.
- Namespaces: For partitioning memories by context, user, agent, or session.
The following example shows how to create a memory container with these configurations:
POST /_plugins/_ml/memory_containers/_create
{
"name": "customer-service-agent",
"description": "Memory container for customer service interactions",
"configuration": {
"embedding_model_type": "TEXT_EMBEDDING",
"embedding_model_id": "your-embedding-model-id",
"llm_id": "your-llm-model-id",
"strategies": [
{
"type": "USER_PREFERENCE",
"namespace": ["user_id"]
},
{
"type": "SUMMARY",
"namespace": ["user_id", "session_id"]
}
]
}
}
Memory types
Each memory container stores four distinct types of memory:
Sessions: Manage conversation sessions and their metadata. Each session represents a distinct interaction context between users and agents, containing session-specific information such as start time, participants, and session state.
The following example demonstrates how to create a session:
POST /_plugins/_ml/memory_containers/<memory_container_id>/memories/sessions
{
"session_id": "user123_session_456",
"summary": "Customer support conversation",
"metadata": {
"user_id": "user123",
"channel": "web_chat"
},
"namespace": {
"user_id": "user123"
}
}
Working memory: Stores active conversation data and structured information that agents use during ongoing interactions. This includes recent messages, current context, agent state, execution traces, and temporary data needed for immediate processing.
Long-term memory: Contains processed knowledge and facts extracted from working memory over time. When inference is enabled, LLMs analyze working memory content to extract key insights, user preferences, and important information, storing it as persistent knowledge that survives across sessions.
History: Maintains an audit trail of all memory operations (add, update, delete) across the memory container, providing a comprehensive log of how memories have evolved over time.
Memory processing strategies
Memory processing strategies define the intelligence layer that transforms raw conversations into meaningful long-term memories. They determine what information should be extracted, how it should be processed, and where the resulting memories should be stored. Each strategy is configured with specific namespaces where extracted memories will be consolidated.
OpenSearch agentic memory provides three built-in strategies:
SEMANTIC: Stores facts and knowledge mentioned in conversations for future reference. For example, “Customer mentioned they use AWS Lambda for serverless processing and prefer Node.js for development.”
USER_PREFERENCE: Stores user preferences, choices, and communication styles. For example, “User prefers detailed technical explanations over high-level summaries” or “User prefers email notifications over SMS alerts.”
SUMMARY: Creates running summaries of conversations, capturing main points and decisions scoped to a session. For example, “User inquired about OpenSearch pricing, discussed cluster sizing requirements, and requested implementation timeline.”
Use the following configuration to set up memory strategies when creating a memory container:
POST /_plugins/_ml/memory_containers/_create
{
"name": "customer-service-agent",
"description": "Memory container for customer service interactions",
"configuration": {
"embedding_model_type": "TEXT_EMBEDDING",
"embedding_model_id": "your-embedding-model-id",
"llm_id": "your-llm-model-id",
"strategies": [
{
"type": "SEMANTIC",
"namespace": ["user_id"]
},
{
"type": "USER_PREFERENCE",
"namespace": ["user_id"]
},
{
"type": "SUMMARY",
"namespace": ["user_id", "session_id"]
}
]
}
}
By default, all strategies exclude personally identifiable information (PII) from long-term memory records.
Namespaces
Namespaces are flexible JSON key-value pairs that provide organizational structure within your memory containers. You can define any keys that fit your use case—there is no predefined schema. These user-defined, application-specific keys give you full control over how you organize your memory data, making namespaces powerful for multi-tenant systems, whether multi-agent, multi-user, or both.
Namespaces serve several important purposes:
- Organizational structure: Separate different types of memories (preferences, summaries, entities) into distinct logical containers.
- Access control: Control which memories are accessible to different agents or in different contexts.
- Multi-tenant isolation: Segregate memories for different users or organizations.
- Focused retrieval: Query specific types of memories without searching through unrelated information.
For example, you might structure namespaces for user and session tracking as follows:
{
"user_id": "user123",
"session_id": "session-456"
}
Alternatively, you can use custom keys tailored to your domain:
{
"department": "sales",
"region": "us-west",
"customer_tier": "enterprise"
}
The following example shows how to use namespaces when storing memories:
POST /_plugins/_ml/memory_containers/<memory_container_id>/memories
{
"messages": [
{
"role": "user",
"content": [
{
"text": "I prefer email notifications over SMS",
"type": "text"
}
]
}
],
"namespace": {
"user_id": "user123",
"session_id": "session-789",
"org_id": "ecommerce-bot"
},
"payload_type": "conversational",
"infer": true
}
Integration with agent frameworks
OpenSearch agentic memory is built as a framework-agnostic solution, meaning it works with any agent framework through a standard REST API interface. Whether you’re using LangChain, LangGraph, Amazon Bedrock Agents, or building custom implementations, you can integrate persistent memory capabilities through standard HTTP requests without framework-specific dependencies or vendor lock-in.
Advanced features
Beyond the core memory management capabilities, OpenSearch agentic memory offers several advanced features that provide greater flexibility and control over how memories are processed, searched, and stored.
Inference modes
OpenSearch agentic memory supports two inference modes controlled by the infer parameter (defaults to false):
Raw storage (infer: false): Stores messages and data directly in working memory without LLM processing. This is the default mode, useful for simple conversation history or when you want to handle processing in your application.
Intelligent extraction (infer: true): Uses configured LLMs to extract key information, facts, and insights from conversations, automatically processing them into long-term memory using the configured strategies.
Semantic search capabilities
Built on OpenSearch’s powerful search engine, agentic memory provides sophisticated retrieval capabilities. Agentic memory supports the full OpenSearch query domain-specific language (DSL), giving you complete flexibility to search and retrieve memories using any query type—term queries, range filters, semantic search, aggregations, or any combination of OpenSearch’s powerful query capabilities.
The following example demonstrates a search query for user preferences:
GET /_plugins/_ml/memory_containers/<memory_container_id>/memories/long-term/_search
{
"query": {
"bool": {
"must": [
{"term": {"namespace.user_id": "user123"}},
{"match": {"strategy_type": "USER_PREFERENCE"}}
]
}
},
"sort": [
{"created_time": {"order": "desc"}}
]
}
Structured data storage
Beyond conversations, agentic memory supports multiple payload types for different data needs:
Conversational payload: For storing conversation messages between users and assistants.
Data payload: For structured, non-conversational data such as agent state, checkpoints, or reference information.
The following example demonstrates storing structured data:
POST /_plugins/_ml/memory_containers/<memory_container_id>/memories
{
"structured_data": {
"agent_state": "researching",
"current_task": "analyze customer feedback",
"progress": 0.75,
"tool_invocations": [
{
"tool_name": "ListIndexTool",
"tool_input": {"filter": "*,-.plugins*"},
"tool_output": "green open security-auditlog-2025.09.17..."
}
]
},
"namespace": {
"agent_id": "research-agent-1",
"session_id": "session456"
},
"metadata": {
"status": "checkpoint",
"branch": {
"branch_name": "main",
"root_event_id": "evt-12345"
}
},
"tags": {
"data_type": "trace",
"priority": "high"
},
"payload_type": "data",
"infer": false
}
You can also store binary data using Base64 encoding with the binary_data field for specialized use cases.
Best practices
The following recommendations will help you implement agentic memory effectively in production environments, covering memory system design, strategy optimization, operational efficiency, and framework integration.
Designing effective memory systems
Structure your memory implementation around your agent’s specific use cases and user needs:
- Use working memory for immediate conversational context and temporary agent state.
- Use long-term memory with inference for persistent knowledge and user preferences.
- Implement namespace patterns that align with your application’s user and session management.
Optimizing memory strategies
Configure memory processing to extract the most valuable insights:
- Use
SEMANTICstrategy for knowledge accumulation and fact extraction. - Apply
USER_PREFERENCEstrategy to learn and remember user choices and preferences. - Implement
SUMMARYstrategy for conversation context compression. - Test different strategy combinations to find what works best for your specific domain.
Efficient memory operations
Balance performance with contextual richness in your memory operations:
- Retrieve relevant memories at conversation start for context establishment.
- Use targeted queries: recent working memory for immediate context, long-term memory for historical insights.
- Store interactions promptly to maintain accurate conversation history.
- Remember that long-term memory extraction is asynchronous—design for eventual consistency.
Integration approaches
When connecting with agent frameworks:
- Build abstraction layers that map framework interfaces to OpenSearch APIs.
- Implement proper error handling and connection management for production use.
- Design namespace strategies that support your application’s multi-tenancy needs.
- Consider caching patterns for frequently accessed memory data.
Getting started
To implement agentic memory in your agents, use these steps:
- Create a memory container with appropriate embedding and LLM models:
curl -X POST "localhost:9200/_plugins/_ml/memory_containers/_create" \ -H "Content-Type: application/json" \ -d '{ "name": "my-agent-memory", "description": "Memory for my AI agent", "configuration": { "embedding_model_type": "TEXT_EMBEDDING", "embedding_model_id": "your-embedding-model-id", "llm_id": "your-llm-model-id", "strategies": [ { "type": "USER_PREFERENCE", "namespace": ["user_id"] } ] } }'
- Add memories during agent interactions:
curl -X POST "localhost:9200/_plugins/_ml/memory_containers/<memory_container_id>/memories" \ -H "Content-Type: application/json" \ -d '{ "messages": [ {"role": "user", "content": [{"text": "I prefer concise responses", "type": "text"}]}, {"role": "assistant", "content": [{"text": "I will keep my responses brief and to the point", "type": "text"}]} ], "namespace": {"user_id": "user123"}, "payload_type": "conversational", "infer": true }'
- Search and retrieve relevant memories:
curl -X GET "localhost:9200/_plugins/_ml/memory_containers/<memory_container_id>/memories/long-term/_search" \ -H "Content-Type: application/json" \ -d '{ "query": { "bool": { "must": [ {"term": {"namespace.user_id": "user123"}}, {"match": {"strategy_type": "USER_PREFERENCE"}} ] } } }'
- Integrate with your agent framework using the patterns shown above for LangChain, LangGraph, or custom implementations.
Example use cases
The following examples demonstrate how OpenSearch agentic memory can be applied across different industries and workflows to create more intelligent, context-aware AI agents.
Customer service with persistent context
Build agents that maintain customer relationship history:
- Store customer interactions with inference enabled to capture preferences and past issues.
- Use
USER_PREFERENCEstrategy to learn communication styles and service preferences. - Organize by customer ID using namespaces for data isolation and efficient access.
- Connect with existing support systems through structured data storage.
Knowledge-building research assistants
Create agents that accumulate expertise over time:
- Store research queries and findings in working memory for immediate context.
- Use
SEMANTICstrategy to build interconnected knowledge bases across research topics. - Maintain research history to track methodology evolution and decision rationale.
- Enable cross-session knowledge building for complex, long-term research projects.
Team-based AI collaboration
Deploy agents that support collaborative workflows:
- Implement namespace hierarchies for team, project, and individual memory separation.
- Store agent decision traces for process transparency and improvement.
- Enable controlled knowledge sharing while maintaining appropriate access boundaries.
- Track collaborative processes through structured conversation summaries.
Conclusion
OpenSearch agentic memory addresses one of the most significant challenges in AI agent development: creating systems that remember, learn, and build context over time. By combining OpenSearch’s robust search capabilities with intelligent memory processing, developers can build more effective AI agents without managing complex memory infrastructure.
The combination of flexible memory types, configurable processing strategies, and hierarchical organization makes OpenSearch agentic memory suitable for a wide range of applications—from customer service bots that remember user preferences to research assistants that accumulate knowledge across sessions. The REST API design ensures compatibility with existing agent frameworks while providing the scalability needed for production deployments.
As AI agents become more prevalent in business applications, the ability to maintain persistent, intelligent memory will differentiate truly useful agents from simple question-and-answer systems. OpenSearch agentic memory provides the foundation for building these next-generation AI experiences.
Ready to get started? Explore the complete agentic memory documentation and begin building smarter agents today.


