As an open-source enthusiast, I believe in the power of collaboration to make open-source projects faster and more efficient. In this blog post, I will share how my team at Linagora, contributing to the Apache James project, identified and addressed a performance issue in the OpenSearch Java client using benchmark tools and flame graphs, in collaboration with the OpenSearch community.
Apache James, also known as Java Apache Mail Enterprise Server, is an open-source email server written in Java. It implements common email protocols like SMTP, IMAP, or JMAP. Apache James is easy to customize with a wide range of extension mechanisms. It is even easy to use as a toolbox to assemble your own email server! Apache James proposes an innovative architecture for email servers: James is stateless and relies on NoSQL databases and message brokers for state management. Thus, administrating James is as easy as managing any modern web application: no sharding or protocol-aware load balancing is required. Apache James uses OpenSearch for search-related features in the distributed mail server setup.
When operating an email server, performance is a concern, as email is a massively used application and is generally considered to be critical. Often, with even a medium-sized deployment, handling over 1,000 requests per second is not uncommon. We use a range of tools for benchmarking the performance of Apache James. Our docs explain some of the benchmarks we suggest our administrators run to identify performance bottlenecks and malfunctions in their clusters.
Apache James relies on OpenSearch as its search engine for its email database. It takes as a dependency the opensearch-java client. We frequently run performance tests with custom Gatling benchmarks. We specifically wanted to regression test performance when we migrated from Elasticsearch 7.10 to OpenSearch for licensing reasons (as an Apache project, we must use licenses compatible with the Apache License 2.0). We realized the OpenSearch requests were slower and started investigating why.
Identifying the performance issue
Flame graphs are powerful visualization tools that can help developers analyze the execution flow of their code and identify bottlenecks. By analyzing the flame graphs, we were able to identify specific areas of code that were causing the performance issue. We used async-profiler to generate a flame graph and found that frequent SPI lookups were causing the performance issue.
Here is the flame graph we used to diagnose this issue. It was taken with async-profiler from within an Apache James container:
./profiler -d 120 -e itimer -f opensearch_2.4.0.html 1
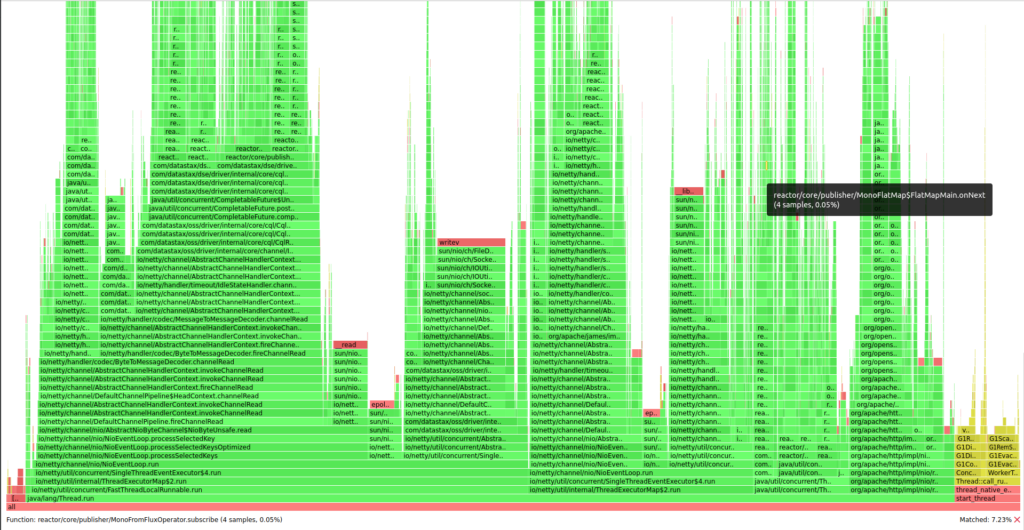
Then we searched for "opensearch" using the search widget in the upper-left corner of the flame graph, which shows the client thread (on the right) with the HttpClient event loop and Apache James calls to the OpenSearch client (small stack traces in the center):
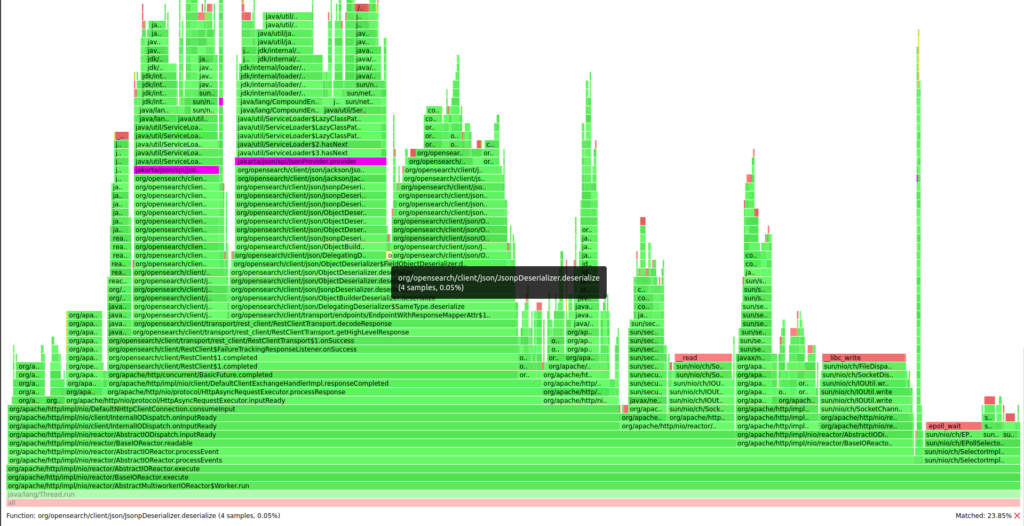
Here are some observations on the client event loop:
- We spend a huge amount of resources performing SPI calls in order to locate the JSON parser implementation. It not only consumes CPU (roughly 26% of client CPU consumption)/heap allocations, but it also blocks the HTTP event loop, which can be catastrophic: the client relies on a few thread-submitting requests in parallel, thus blocking the thread seriously impacts overall latencies and throughput.
- Unsurprisingly, JSON parsing takes 11% of the client’s CPU and 24% of its heap allocation.
- Event loop busyness takes around 60% of the event loop CPU and 25% of heap allocations, which appears normal.
- 2.3% of the event loop CPU is our binding to a Reactor reactive library, which, again, is normal: converting futures and enqueuing tasks takes time.
To mitigate calls to the SPI, we submitted a change to JsonValueParser.java that addressed the issue. This led to a 50x speedup of the JSON parsing by getting rid of the SPI lookups, not even taking into account the blocking operations…huge win!
You can download the interactive flame graph that was used to diagnose this issue here.
As a common practice, we then run micro-benchmarks to validate changes, and JMH comes in handy for this. It summarizes key metrics, performs warmup, repeats measurements, and comes with nanosecond resolution!
Here is the JMH output backing this change.
Before
Benchmark Mode Cnt Score Error Units
JMHFieldBench.jsonBench avgt 5 71.790 ± 2.125 us/op
After
Benchmark Mode Cnt Score Error Units
JMHFieldBench.jsonBench avgt 5 1.418 ± 0.024 us/op
Benchmark code
package org.apache.james.backends.opensearch;
import java.io.IOException;
import java.util.concurrent.TimeUnit;
import org.apache.james.backends.opensearch.json.jackson.JacksonJsonpParser;
import org.junit.Test;
import org.openjdk.jmh.annotations.Benchmark;
import org.openjdk.jmh.annotations.Mode;
import org.openjdk.jmh.infra.Blackhole;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import org.openjdk.jmh.runner.options.TimeValue;
import com.fasterxml.jackson.core.JsonParser;
import com.fasterxml.jackson.databind.ObjectMapper;
public class JMHFieldBench {
public static final ObjectMapper OBJECT_MAPPER = new ObjectMapper();
@Test
public void launchBenchmark() throws Exception {
Options opt = new OptionsBuilder()
.include(this.getClass().getName() + ".*")
.mode (Mode.AverageTime)
.timeUnit(TimeUnit.MICROSECONDS)
.warmupTime(TimeValue.seconds(5))
.warmupIterations(3)
.measurementTime(TimeValue.seconds(2))
.measurementIterations(5)
.threads(1)
.forks(1)
.shouldFailOnError(true)
.shouldDoGC(true)
.build();
new Runner(opt).run();
}
@Benchmark
public void jsonBench(Blackhole bh) throws IOException {
final JsonParser parser = OBJECT_MAPPER.createParser("[\"a\",\"b\"]");
try {
bh.consume(new JacksonJsonpParser(parser).getArrayStream());
} catch (Exception e) {
// do nothing
} finally {
parser.close();
}
}
}
The bench was applied before/after the backport of this PR on top of Apache James CF apache/james-project@d5af3a5.
Collaborating with the OpenSearch community
I believe open-source projects are more than just code—they’re communities of people who share a common goal of making technology more accessible and efficient. By collaborating with the OpenSearch community, we contributed to this goal by getting rid of SPI lookups and improving JSON parsing performance in an application that is probably running on countless servers. Working together, we made OpenSearch faster and more efficient. It’s rewarding to make a positive impact on both technology and the community of people who use it. This case study shows how collaboration and community involvement can make open-source technology better for everyone.