
Neural sparse search combines the semantic understanding of neural models with the efficiency of sparse vector representations. This technique has proven effective for semantic retrieval while maintaining the advantages of traditional lexical search, offering better explanation and presentation of results through text matching. As these sparse embeddings have gained popularity, the increased index sizes have introduced scalability challenges.
Traditional search methods suffer from increasing query latency as collections grow. This degradation in query throughput can significantly impact the user experience. In OpenSearch 2.15, we took an important first step toward addressing this challenge by introducing the two-phase search processor. By dynamically pruning tokens with negligible weights, this approach reduces the computational load while preserving search relevance.
With this same goal of efficiency and high-quality retrieval, we recently introduced sparse approximate nearest neighbor (ANN) search based on the SEISMIC (Spilled Clustering of Inverted Lists with Summaries for Maximum Inner Product Search) approximate retrieval algorithm for sparse vectors. This algorithm fundamentally changes what’s possible in large-scale search. Today, we’re excited to announce that the SEISMIC algorithm is now available in OpenSearch 3.3. This algorithm achieves faster query latency than traditional BM25 while preserving the semantic understanding of neural sparse models, representing a fundamental shift in the search performance landscape.
The SEISMIC algorithm
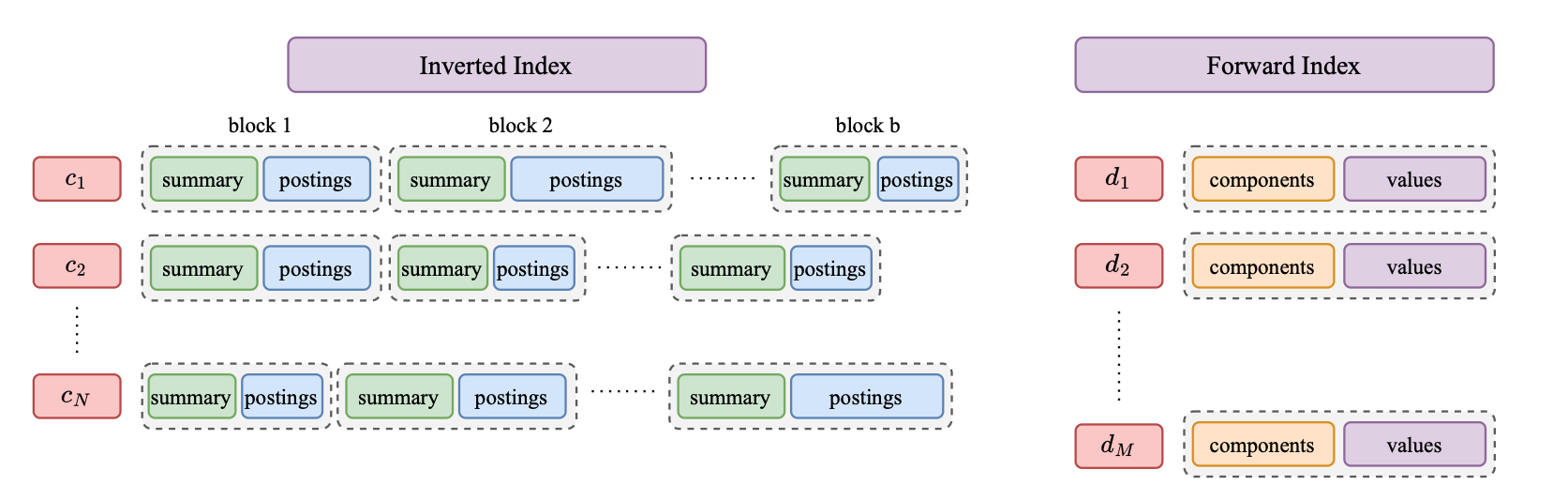
A SEISMIC index consists of two components: an inverted index and a forward index. The forward index maps each document ID to its sparse embedding, where each embedding component represents a token ID and its corresponding weight. The inverted index, on the other hand, applies multiple pruning techniques to optimize efficiency and reduce storage:
- Clustered posting list: For each term in the inverted index, the SEISMIC algorithm sorts documents by token weights, retains only the top documents, and applies clustering in order to group similar documents.
- Sparse vector summarization: Each cluster maintains a summary vector containing only the highest-weighted tokens, enabling efficient pruning during query time.
- Query-time pruning: During query execution, the SEISMIC algorithm employs token-level and cluster-level pruning to dramatically reduce the number of documents that need scoring.
The data organization in the forward and inverted indexes is presented in the following image.
 Try it out
Try it out
To try SEISMIC-based ANN sparse search, follow these steps.
Step 1: Create an index
Create a sparse index by setting index.sparse to true and define a sparse_vector field in the index mapping:
PUT sparse-vector-index { "settings": { "index": { "sparse": true } }, "mappings": { "properties": { "sparse_embedding": { "type": "sparse_vector", "method": { "name": "seismic", "parameters": { "approximate_threshold": 1 } } } } } }
Step 2: Ingest data into the index
Ingest three documents containing sparse_vector fields into your index:
PUT sparse-vector-index/_doc/1 { "sparse_embedding": { "1000": 0.1 } }
PUT sparse-vector-index/_doc/2 { "sparse_embedding": { "2000": 0.2 } }
PUT sparse-vector-index/_doc/3 { "sparse_embedding": { "3000": 0.3 } }
Step 3: Search the index
You can query the sparse index by providing either raw vectors or natural language using a neural sparse query.
Query using a raw vector
To query using a raw vector, provide the query_tokens parameter:
GET sparse-vector-index/_search { "query": { "neural_sparse": { "sparse_embedding": { "query_tokens": { "1000": 5.5 }, "method_parameters": { "heap_factor": 1.0, "top_n": 10, "k": 10 } } } } }
Query using natural language
To query using natural language, provide the query_text and model_id parameters:
GET sparse-vector-index/_search { "query": { "neural_sparse": { "sparse_embedding": { "query_text": "<input text>", "model_id": "<model ID>", "method_parameters": { "k": 10, "top_n": 10, "heap_factor": 1.0 } } } } }
Benchmark experiments: Comparing SEISMIC and traditional approaches
We conducted a billion-scale benchmark to compare the performance of the SEISMIC algorithm and traditional search methods, including BM25, neural sparse search, and two-phase search.
Experimental setup
- Corpus set: C4 dataset from Dolma. After preprocessing, the dataset is chunked into 1,285,526,507 (approximately, 1.29 billion) documents.
- Query set: MS MARCO v1 dev set with 6,980 queries.
- Sparse embedding models: We used the doc-only mode with two models:
- Corpus encoding:
amazon/neural-sparse/opensearch-neural-sparse-encoding-doc-v3-gte - Query encoding:
amazon/neural-sparse/opensearch-neural-sparse-tokenizer-v1
- Corpus encoding:
- OpenSearch cluster: An OpenSearch cluster running version 3.3
- Cluster manager nodes: 3 m7g.4x large instances
- Data nodes: 15 r7g.12x large instances
Benchmarking results
For our billion-scale benchmark, we evenly split the dataset into 10 partitions. After each partition was ingested, we ran a force merge to build a new SEISMIC segment. This approach resulted in 10 SEISMIC segments per data node, with each segment containing approximately 8.5 million documents.
Following the Big ANN benchmark, we focused on the query performance when recall @ 10 reaches 90%. We considered two experimental setups: single-threaded and multithreaded. For the single-threaded setup, metrics were collected using a Python script. Latency was measured using the took time returned by OpenSearch queries. For the multithreaded setup, throughput metrics were measured using opensearch-benchmark with four threads in total. The benchmarking results are presented in the following table.
Table I: Comparison between neural sparse, BM25, and SEISMIC queries
| Metrics | Neural sparse | Neural sparse two phase | BM25 | SEISMIC | |
|---|---|---|---|---|---|
| Recall @ 10 (%) | 100 | 90.483 | N/A | 90.209 | |
| Single-threaded | Average latency (ms) | 125.12 | 45.62 | 41.52 | 11.77 |
| P50 latency (ms) | 109 | 34 | 28 | 11 | |
| P90 latency (ms) | 226 | 100 | 90 | 16 | |
| P99 latency (ms) | 397.21 | 200.21 | 200.21 | 27 | |
| P99.9 latency (ms) | 551.15 | 296.53 | 346.06 | 50.02 | |
| Multithreaded | Mean throughput (op/s) | 26.35 | 82.05 | 85.86 | 158.7 |
Given 90% recall, the SEISMIC algorithm achieved an average query time of merely 11.77 ms—nearly 4x faster than BM25 (41.52 ms) and over 10x faster than standard neural sparse search (125.12 ms). In a multithreaded setup, SEISMIC demonstrated a significant throughput advantage—handling 158.7 operations per second, nearly double BM25’s throughput (85.86 op/s)—while maintaining comparable recall to the two-phase approach.
In total, the force merge time was 2 hours, 58 minutes, and 30 seconds. On average, memory consumption was approximately 53 GB per data node for storing SEISMIC data.
Best practices
Based on our benchmarking results, here are some best practices for working with the SEISMIC algorithm:
- Recommended segment size: Set the approximate threshold to 5M documents and force merge segments to between 5M and 10M documents for best performance.
- Memory planning: Plan for approximately 1 GB of memory per 1M documents when selecting appropriate instance types and sizing the cluster.
These results demonstrate that the SEISMIC algorithm delivers unprecedented performance for billion-scale search applications, outperforming even traditional BM25 while maintaining the semantic understanding of neural sparse models.
Conclusion
In OpenSearch 3.3, we’re introducing an approximate retrieval algorithm for sparse vectors. This algorithm delivers faster query times than BM25 while maintaining the semantic understanding of neural sparse models. For billion-scale search applications, it removes key scalability barriers by dramatically reducing query latency, allowing you to achieve better performance with fewer nodes.
The capability to search across billions of documents with latency of less than 12 ms changes what’s possible in information retrieval. We’re excited to see you use this technology to build the next generation of semantic search applications. As always, we’d love to hear your feedback—join the conversation and share your experiences on the OpenSearch forum.
Further reading
- The SEISMIC paper
- Improving document retrieval with sparse semantic encoders
- Introducing the neural sparse two-phase algorithm




