
Is your search feeling a bit…off?
Perfect search results—wouldn’t that be nice? In fact, in the world of search, most practitioners would probably call that a miracle. The quest for improving search result quality is ongoing. Even with AI-powered techniques like learning to rank, semantic search, and hybrid search, search professionals continuously strive for better results. In some ways, adding new techniques increases the challenges.
If you’re having trouble with your search results, you’re not alone. OpenSearch 3.1 introduces the Search Relevance Workbench, a comprehensive toolkit that helps you improve and fine-tune your search relevance through experimentation.
The Search Relevance Workbench is designed for search professionals at all levels of experience. In the first blog of this three-part blog series, we’ll explore common challenges that search practitioners face and demonstrate how this toolkit helps solve these problems while providing guidance and support. This first installment is specifically aimed at users who recognize they have problematic search queries but aren’t sure how to investigate and diagnose them.
Queries with unknown issues
The journey to improved search quality often begins with a user query that yields less-than-ideal results. However, not every member of a search or product team has access to a comprehensive suite of search relevance tools. Some users want to start their exploration visually, gathering information as an initial step.
A common goal for search practitioners is to understand problematic queries and generate ideas worth pursuing to enhance search result quality. Traditionally, this situation led search teams to build their own evaluation tools and processes, as search engines offered limited or no means to diagnose and fix queries.
These users might know the query strings (what users type into a search bar), but remain unaware what happens afterward. It’s akin to driving a car with a warning light going off, but lacking the mechanic’s tools to investigate or fix the problem.
The Search Relevance Workbench addresses this gap by providing ways to visually explore troubling queries. It offers user interfaces that allow for comparison of search results across different search configurations, empowering teams to diagnose and improve search performance effectively.
Your new toolkit: the Search Relevance Workbench
To follow along clone the accompanying repository for this blog post:
git clone https://github.com/o19s/srw-blogs.git
cd srw-blogs
docker compose up -d
Now clone the SRW backend repository that comes with sample data and a script that helps us set up things quickly.
git clone https://github.com/opensearch-project/search-relevance.git
cd search-relevance/src/test/scripts
./demo_hybrid_optimizer.sh
In short, this script sets up an OpenSearch instance with the Search Relevance Workbench backend feature enabled. It indexes product data (including embeddings) to allow us to explore a hybrid search setting.
Let’s run a keyword search to see some of the products. Go to OpenSearch Dashboards at http://localhost:5601 and to Dev Tools to execute the following multi_match query:
GET ecommerce/_search
{
"query": {
"multi_match": {
"query": "laptop",
"fields": ["id", "title", "category", "bullet_points", "description", "brand", "color"]
}
},
"_source": ["id", "title", "category", "brand"]
}
We search for laptop across multiple fields (“id”, “title”, “category”, “bullet_points”, “description”, “brand”, “color”) in the ecommerce index. However, the results we retrieve are not great: among others we see a laptop desk, a foldable bed table, a waterproof laptop case and a laptop backpack. Feels a lot like the classic accessories challenge in ecommerce: instead of seeing the products we are looking for we see a lot of accessories for these products.
As search professionals, we may be interested in seeing how a hybrid search approach changes results by combining both keyword-based and vector-based searching. To run a hybrid search query, we first need to know the model_id that we can use for the neural search component. The demo script has already handled uploading the model, ensuring it’s ready for use. To proceed, search for the model using the following request and locate the model_id in the response:
POST /_plugins/_ml/models/_search
{
"query": {
"match_all": {}
},
"size": 1
}
Response:
{
"took": 74,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 11,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": ".plugins-ml-model",
"_id": "lZBXE5gBRVO0vZIAKepk_2",
"_version": 1,
"_seq_no": 3,
"_primary_term": 1,
"_score": 1,
"_source": {
"model_version": "1",
"created_time": 1752671139796,
"chunk_number": 2,
"last_updated_time": 1752671139796,
"model_format": "TORCH_SCRIPT",
"name": "huggingface/sentence-transformers/all-MiniLM-L6-v2",
"is_hidden": false,
"model_id": "lZBXE5gBRVO0vZIAKepk",
"total_chunks": 10,
"algorithm": "TEXT_EMBEDDING"
}
}
]
}
}
We’re now ready to run a hybrid search query. Copy the model_id (in this case lZBXE5gBRVO0vZIAKepk) and customize the following request, so that your model_id is used:
GET ecommerce/_search?search_pipeline=normalization-pipeline
{
"query": {
"hybrid": {
"queries": [
{
"multi_match": {
"query": "laptop",
"fields": ["id", "title", "category", "bullet_points", "description", "brand", "color"]
}
},
{
"neural": {
"title_embedding": {
"query_text": "laptop",
"k": 100,
"model_id": "lZBXE5gBRVO0vZIAKepk"
}
}
}
]
}
},
"size": 10,
"_source": ["id", "title", "category", "brand"]
}
Note that we use the “normalization-pipeline” search pipeline, which is necessary for score normalization in a hybrid search scenario. For more information about why this pipeline is necessary refer to the documentation on normalizing and combining scores.
Scanning through the results, it appears to be an improvement: a Lenovo Chromebook in position 1, an HP laptop in position 3, among others. While some less relevant still appear, overall, the changes look promising.
However, it is difficult to assess the difference between the two result sets without opening two browser windows, placing them side-by-side, and comparing every single item one-by-one.
This is where the first Search Relevance Workbench tool comes in handy: the side-by-side comparison tool for an individual query.
Single query: ad-hoc exploration & immediate feedback
If you haven’t done so already, activate the frontend plugin by following these three steps:
- Go to Management > Dashboards Management > Advanced Settings in OpenSearch Dashboards
- Turn on the toggle for Experimental Search Relevance Workbench
- Save the change
With the frontend feature activated, users can access the single query comparison tool by navigating to “Single Query Comparison” in the Search Relevance Workbench.
This first tool allows you to specify two queries that are executed against an index. The results are then compared, allowing you to quickly grasp the differences between the two.
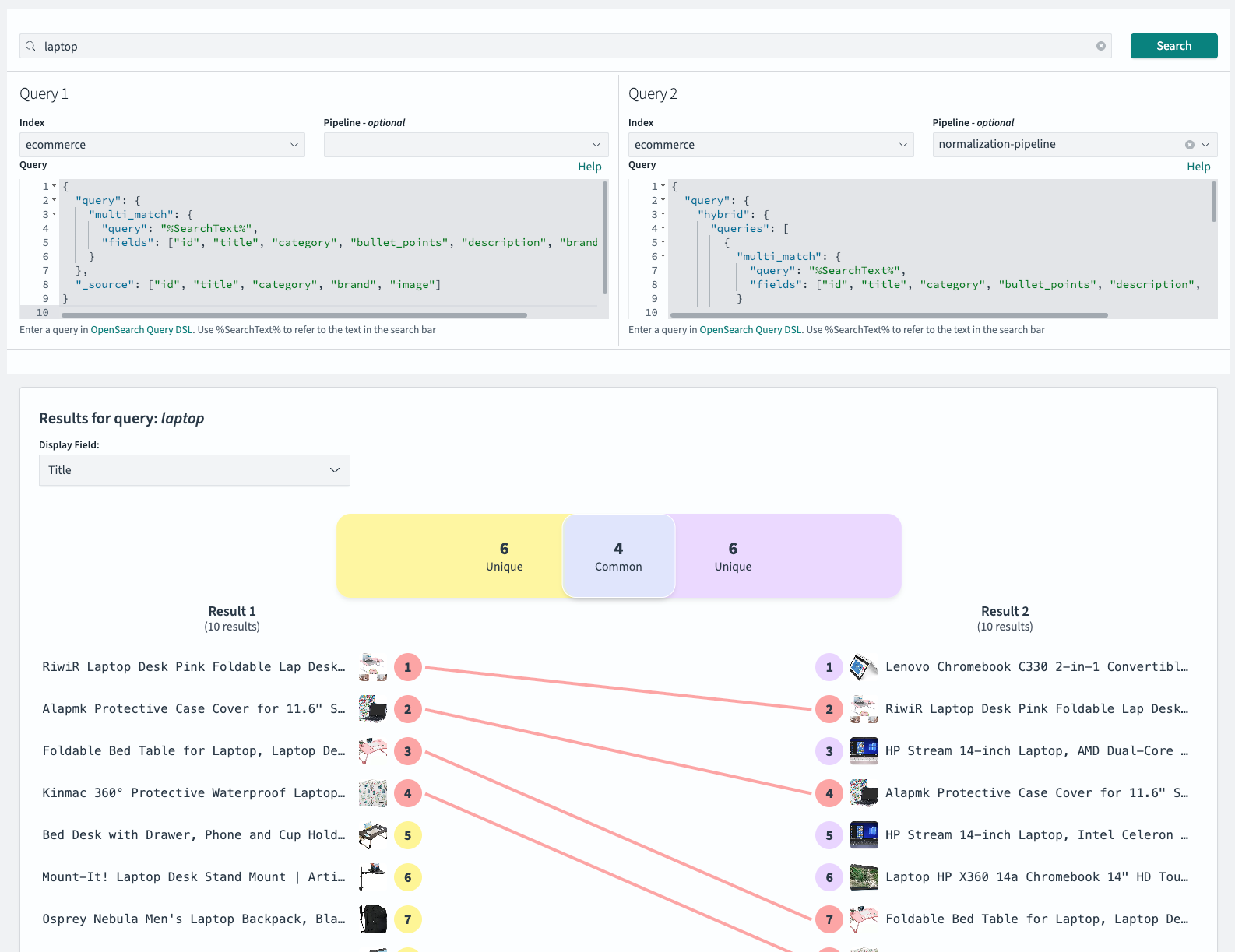
The two queries we want to compare are both targeted at the index ecommerce.
Query 1 represents a traditional keyword-based search across multiple fields, with no pipeline. The query body is similar to the keyword query we ran, but with two changes:
- An additional image field we’re returning to see product images.
- The variable ‘%SearchText%’ in place of the user query string.
{
"query": {
"multi_match": {
"query": "%SearchText%",
"fields": ["id", "title", "category", "bullet_points", "description", "brand", "color"]
}
},
"_source": ["id", "title", "category", "brand", "image"]
}
Query 2 is the hybrid search query, combining keyword matching with neural search on the title embedding. It uses the ‘normalization-pipeline’ and has a query body with changes identical to those in the keyword query. Remember to use your specific model_id in this query.
{
"query": {
"hybrid": {
"queries": [
{
"multi_match": {
"query": "%SearchText%",
"fields": ["id", "title", "category", "bullet_points", "description", "brand", "color"]
}
},
{
"neural": {
"title_embedding": {
"query_text": "%SearchText%",
"k": 100,
"model_id": "lZBXE5gBRVO0vZIAKepk"
}
}
}
]
}
},
"size": 10,
"_source": ["id", "title", "category", "brand", "image"]
}
After clicking the “Search” button, two result lists are retrieved and compared, with differences visually highlighted.
By default, the Search Relevance Workbench displays the ID of the retrieved document. To make the content easier to interpret, you can change this to a more descriptive field using the provided dropdown box—in this case, selecting “Title” is more helpful.
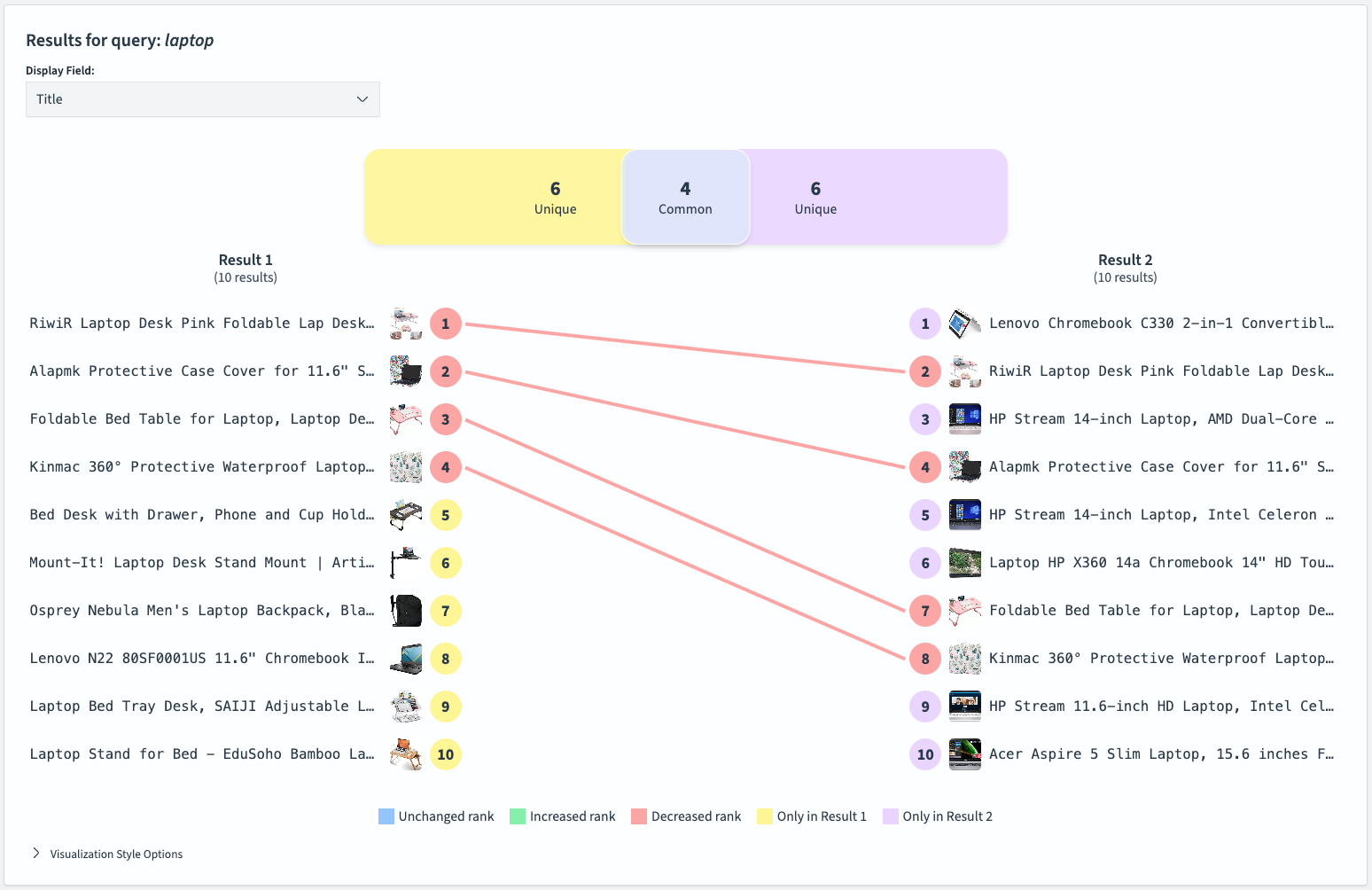
Looking at the provided details reveals there are four results that both queries return and six unique items each.
The result lists show that we have transformed a query that predominantly returned laptop accessories into one that mainly returns laptops.
What makes this tool useful for ad-hoc exploration is that it enables users to quickly see changes at-a-glance. This helps to assess the potential impact of changes on one particular query. In the case of the laptop query, it shows significant improvement: less relevant products have been removed from the results. Overall, the results for Query 2 look more convincing, and switching to hybrid search clearly makes sense from a search quality perspective.
However, a single query, while useful for ad-hoc checks, rarely provides a complete picture of how a change impacts overall search quality or reveals broader patterns across your user base. To properly evaluate changes and identify emerging patterns, it’s necessary to assess performance across a whole set of queries.
Multiple queries: broaden evaluation for emerging patterns
To evaluate multiple queries, we’ll use two key concepts from the Search Relevance Workbench: Query Sets and Search Configurations.
Query sets
A query set is a collection of queries relevant to the search application’s domain. There are different flavors of query sets, and come in different varieties. A set might contain queries of one particular type, such as known-item queries, or it might aim to represent all query types. Typically, query sets are sampled from real user queries, a process the Search Relevance Workbench supports.
For this blog post, we’ll use the manually created query set provided in the accompanying Github repository.
{"queryText": "laptop"}
{"queryText": "red shoes"}
{"queryText": "in-ear headphones"}
{"queryText": "portable bluetooth speakers"}
{"queryText": "stainless steel mending plates"}
{"queryText": "funny shirt birthday present"}
You can create a query set by dragging and dropping a text file containing these six queries into the Search Relevance Workbench’s input form.
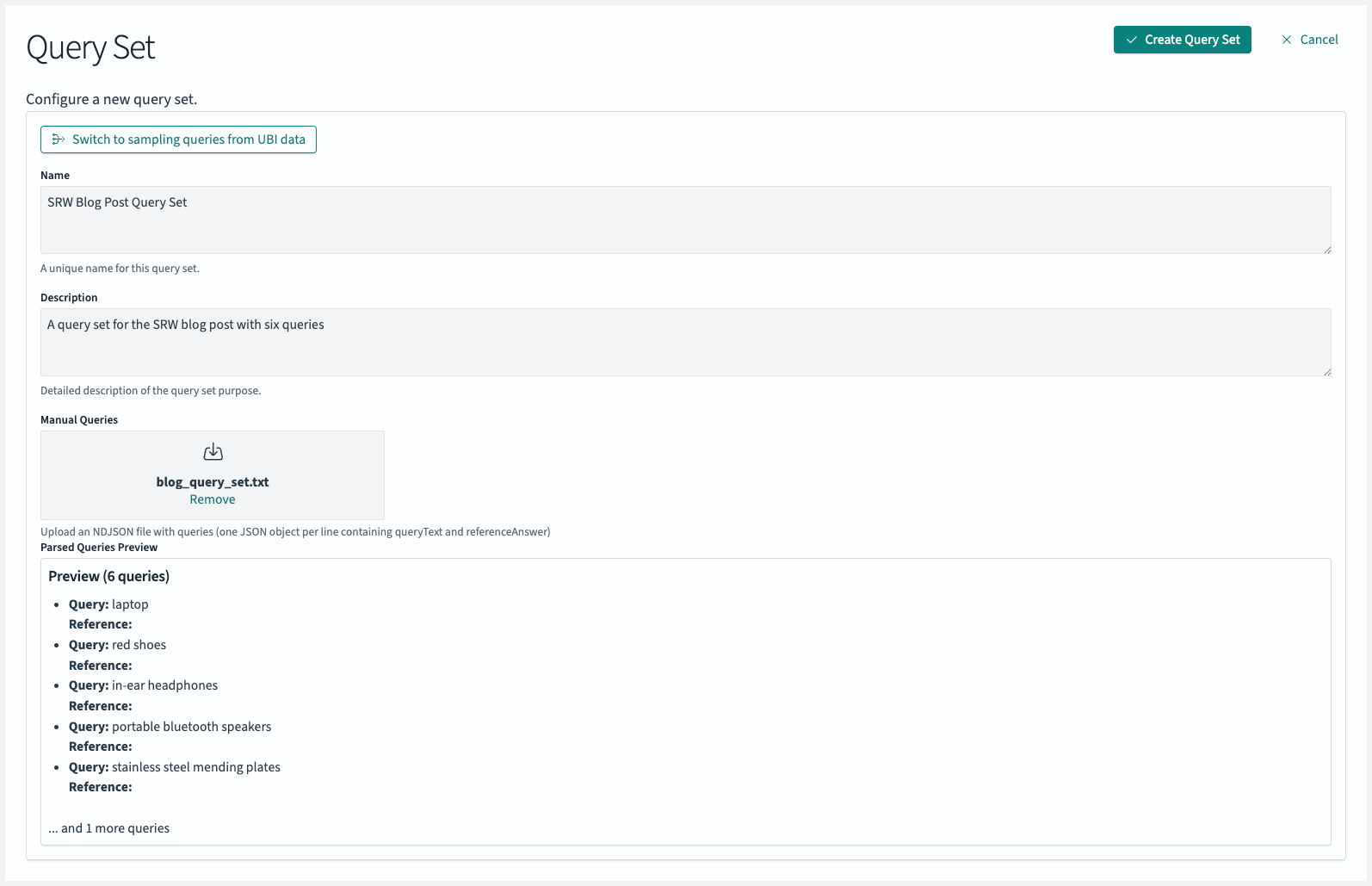
Confirming with the “Create Query Set” button stores this query set in the corresponding OpenSearch index.
Search configurations
A search configuration tells the Search Relevance Workbench how to execute queries during experiments. Each configuration consists of a query body and an optional search pipeline, similar to what the single-query side-by-side view offers.
We’ll use the same query body from our side-by-side comparison to create two search configurations for deeper exploration.
First, let’s create a search configuration for keyword search:
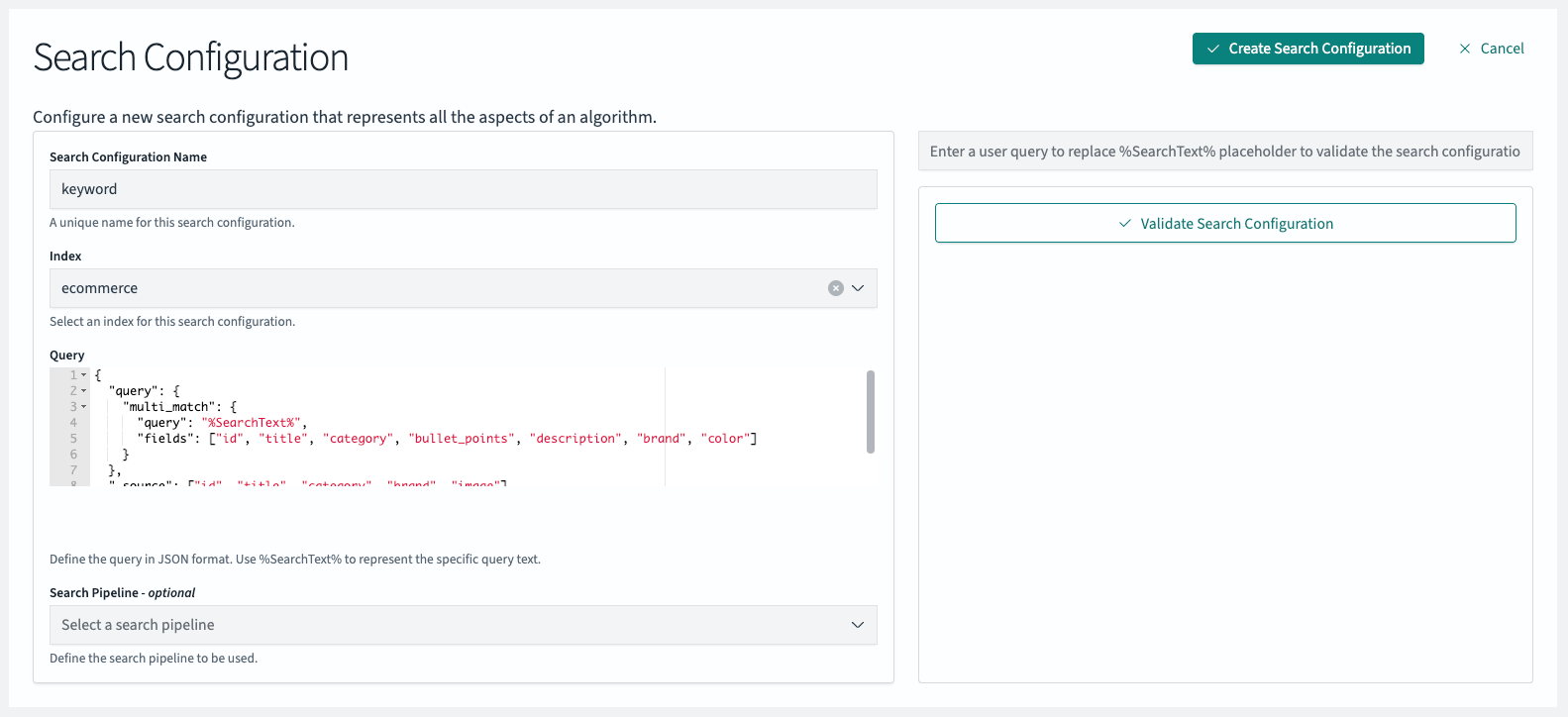
- Search Configuration Name: keyword
- Index: ecommerce
Query:
{
"query": {
"multi_match": {
"query": "%SearchText%",
"fields": ["id", "title", "category", "bullet_points", "description", "brand", "color"]
}
},
"_source": ["id", "title", "category", "brand", "image"]
}
Create a search configuration for hybrid search. Don’t forget to update the query with your model_id and set the search pipeline to normalization-pipeline:
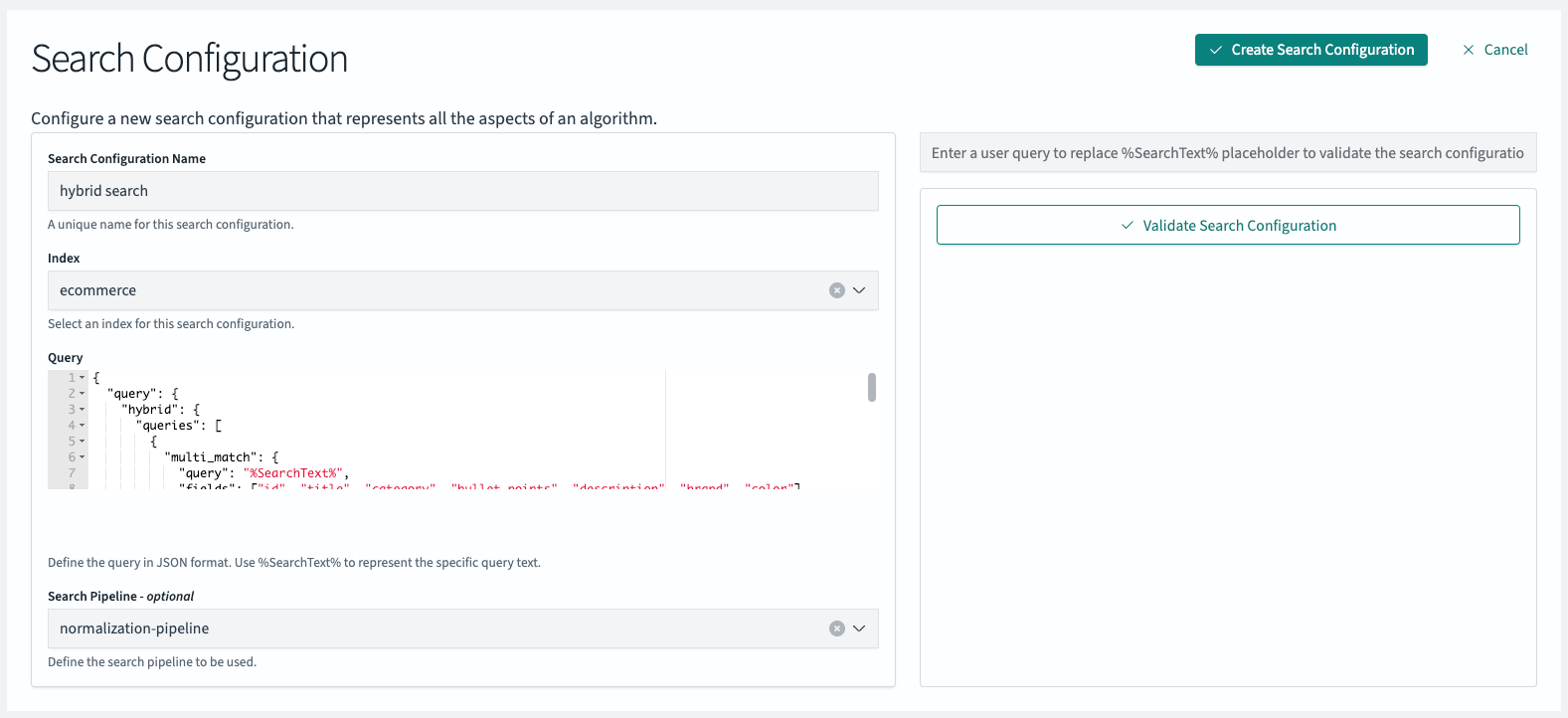
- Search Configuration Name: hybrid search
- Index: ecommerce
Query:
{
"query": {
"hybrid": {
"queries": [
{
"multi_match": {
"query": "%SearchText%",
"fields": ["id", "title", "category", "bullet_points", "description", "brand", "color"]
}
},
{
"neural": {
"title_embedding": {
"query_text": "%SearchText%",
"k": 100,
"model_id": "lZBXE5gBRVO0vZIAKepk"
}
}
}
]
}
},
"size": 10,
"_source": ["id", "title", "category", "brand", "image"]
}
Running a query set comparison experiment
Now that we have met the requirements (a query set and two search configurations), we can run a query set comparison. This will not just compare two result lists at-a-glance, but all result lists from the queries of our query set.
In the left navigation go to Query Set Comparison, choose the created query set (“SRW Blog Post Query Set”) as well as the search configurations (keyword & hybrid search) and start the evaluation:
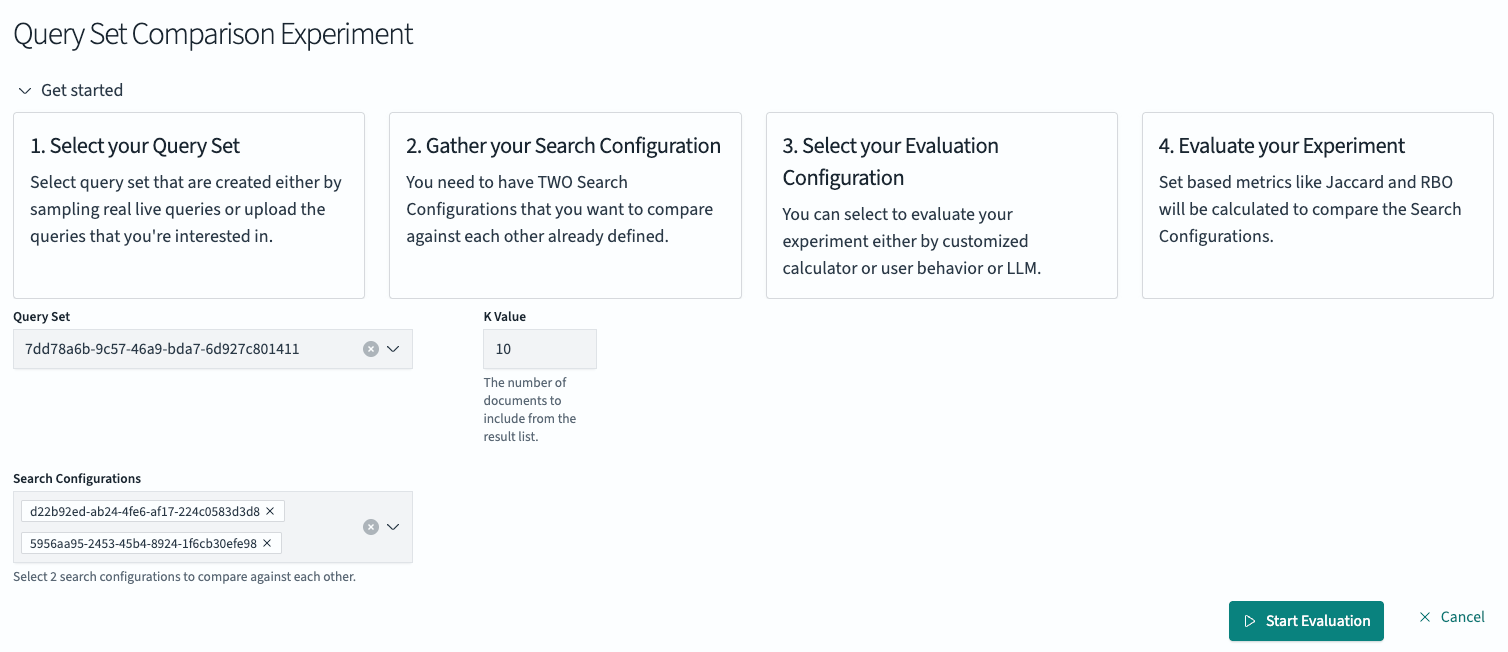
After clicking the “Start Evaluation” button, the backend executes the six queries from the query set with each search configuration. The system runs all 12 queries (six queries executed with two different configurations) and calculates the changes in the result lists. The experiments overview page displays completed experiments with ‘COMPLETED’ status.
To view the results and surface insights click on the linked experiment ID. The section after the experiment details (which query set was used and the two search configurations) shows a summary of the calculated metrics that indicate the change between the result lists produced by the two different search configurations:

All four metrics measure different aspects of change. Jaccard measures simple set overlap, while frequency-weighted similarity quantifies overlap by giving more importance to prevalent shared items. Rank-Biased Overlap (RBO) assesses agreement between ranked lists, placing higher value on matches at the top. RBO50 and RBO90 show how much a user’s attention focuses on top results. For example, RBO50 emphasizes top results more heavily, assuming users are 50 percent less likely to look at each subsequent result.
A low Jaccard similarity (like the 0.21 in the screenshot below) indicates a significant difference in the result lists, suggesting that the hybrid search configuration is bringing in many new documents. Higher RBO values, especially at lower cutoffs like RBO50, mean that the top results—where users pay most attention—are more consistent between configurations.
These aggregate metrics provide an overview of the difference between search configurations. For a closer look at individual queries, select any query to see a view similar to the individual query result comparison:
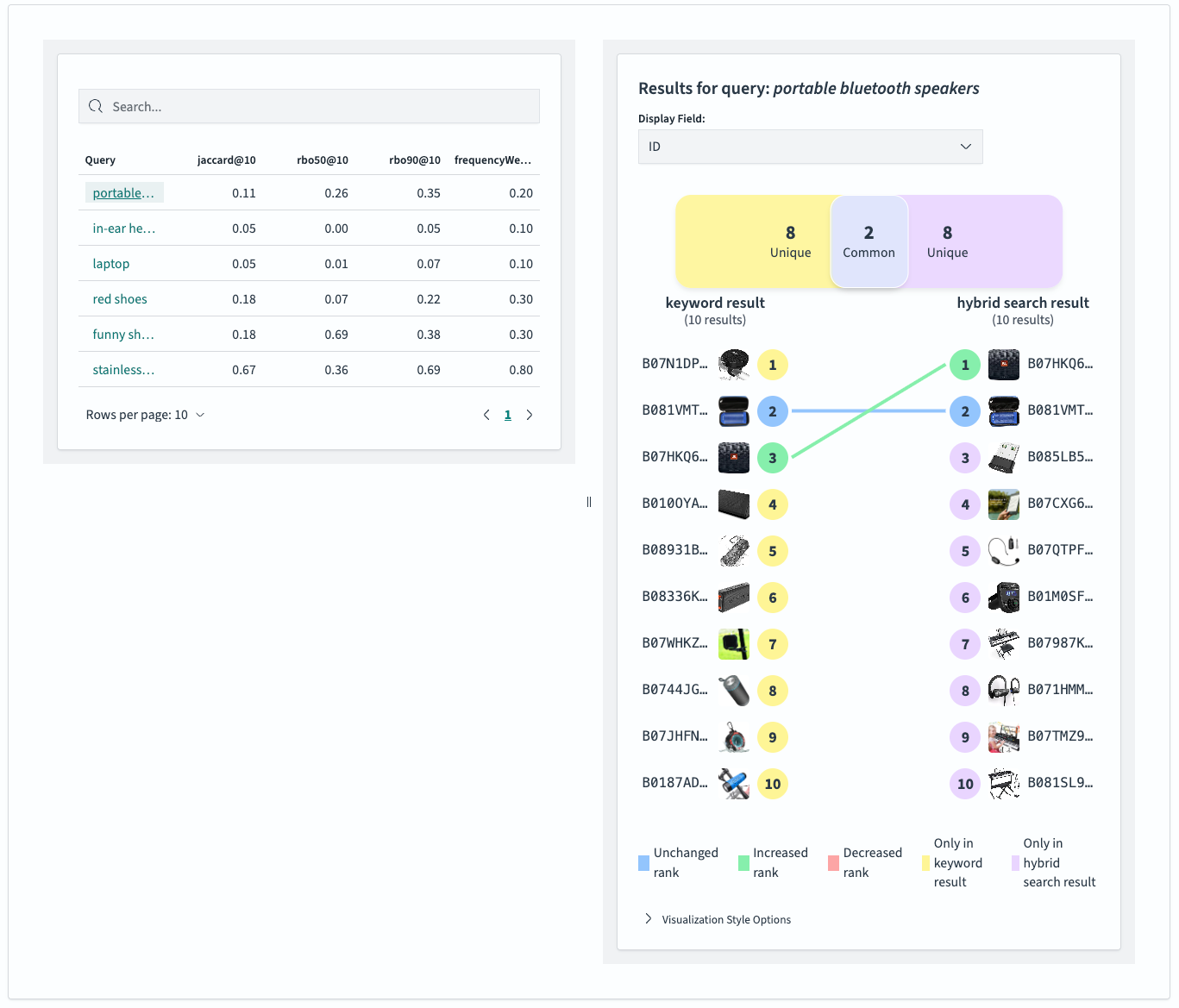
By examining the queries, we can see how different search configuration would affect and assess both its potential benefits and risks. The metrics for individual queries allow us to draw broader conclusions by revealing trends for specific query groups. In our example, it looks like queries that aim for a specific category (laptop, in-ear headphones) are subject to significant change whereas the results of very targeted queries (stainless steel mending plates) do not change as much.
In this particular case, the introduction of hybrid search brings substantial changes within the top 10 results. By reviewing all six queries, we can visually assess whether these changes improve search quality. This combination of subjective review and objective metrics provides a solid foundation for addressing search relevance challenges and making initial assessments.
Conclusion
In this first blog post of the three-part series, we’ve shown how the Search Relevance Workbench can help you quickly gain insights to improve search quality. You need just two elements to begin:
- A query set: your collection of test queries
- Two search configurations: the query patterns you want to explore
You now have the tools and knowledge to experiment with your own data. Start by selecting some problematic queries, create two search configurations, and analyze the differences! This process will quickly reveal what’s blocking your path to better search results. You can also explore how OpenSearch helps deliver more relevant search results, making it possible to connect underlying intent with the most meaningful results
In our next post, we’ll move beyond measuring changes to explore quantitative measurements of search relevance. You’ll learn how to determine not just the differences between search configurations, but which configuration performs better. Stay tuned!
