

Case study inspired by the OpenSearchCon Korea keynote by Sun Ro Lee, Cloud Engineer, LINE Plus
Challenge
LINE’s platform supports over 194 million monthly active users across Asia. That scale created an urgent need for a unified, reliable, and high-performance search and analytics backend capable of:
- Handling 10 petabytes of data, 1,280 plus clusters, and 11,000 plus nodes
- Supporting log analytics, monitoring, data pipelines, and real time search
- Eliminating operational burdens caused by running Elasticsearch on physical servers and Kubernetes
- Preparing for rapid growth in new AI agent powered services, each requiring vector search, hybrid search, and secure access to internal data
As Sun Ro Lee put it during the keynote, “We started with 100 physical servers and Kubernetes… but adoption increased rapidly and maintaining everything introduced significant operational burdens.”
Solution
LINE migrated fully to OpenSearch, adopting it as the unified backend across multiple regions and environments.
Key Innovations
- Multi AZ high availability and cross region durability
Clusters are automatically spread across availability zones, and backups are replicated across regions with zero user configuration. LINE has recorded zero data loss incidents in recent years. - High performance hot tier and low cost cold tier
Using NVMe over Fabric for high performance workloads and HDD based cold tiers for massive retention reduced cost while supporting workloads at 2,000 to 3,000 RPS and multi-terabyte indexing. - Automated searchable snapshot lifecycle
Data transitions automatically from hot indexing to long term searchable snapshots, then to deletion according to retention policy with no extra pipeline management. - Hardware tuned for OpenSearch
Three hardware generations were tested, tuned, and benchmarked. Kernel level adjustments drove major indexing throughput and latency improvements, shown in the chart.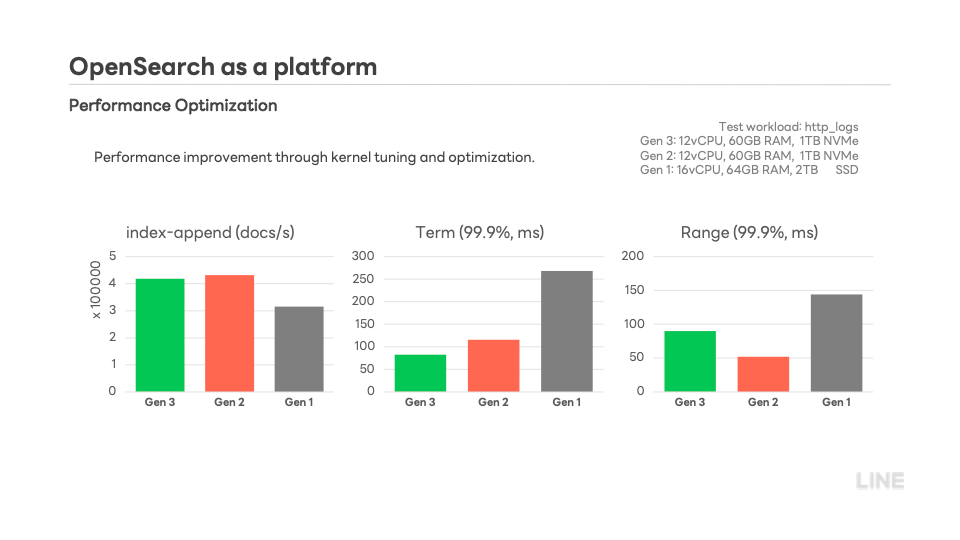
- Preparing for agentic search with OpenSearch 3.3
LINE’s forward strategy centers on supporting AI agent workloads with:
- Hybrid search and GPU acceleration
- A fully managed embedding pipeline
- Integrated model deployment
- Automated GPU node provisioning
- Unified access control and security
As Lee emphasized: “Our overall goal is to enable developers across LINE to fully leverage OpenSearch’s AI features with minimal operational overhead.”
Results
Transformation from log storage to full search platform
OpenSearch evolved into a central platform powering datachain, monitoring, and LINE’s unified log store. The footprint increased from 300 clusters in 2020 to nearly 1,300 today, driven by new regions and internal migration projects.
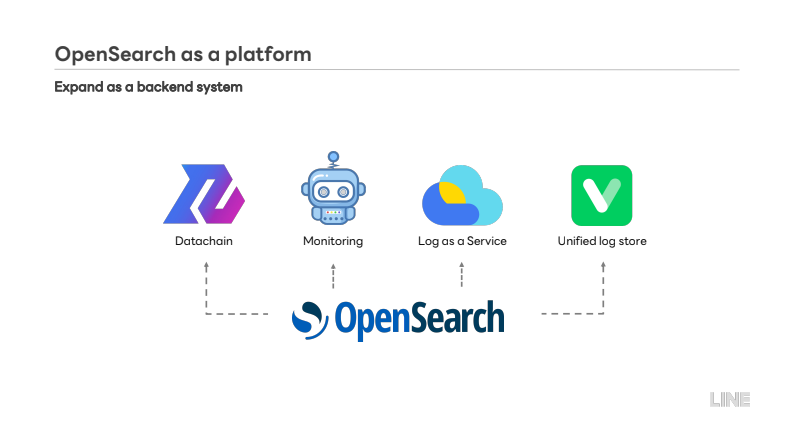
Operator efficiency
The shift from manual Kubernetes and physical server management to automated OpenSearch services significantly reduced internal maintenance load and enabled the rapid launch of more than 80 clusters within six months.
AI readiness
Teams across LINE are already spinning up new clusters to support AI agent workloads, motivated by the fast evolving OpenSearch feature set. The roadmap on pages 14–16 outlines accelerated adoption of:
- GPU accelerated vector search
- Hybrid search with reranking
- Multimodal embeddings
- Agentic search capabilities
Quote pullout
“OpenSearch has become a highly stable and reliable platform inside LINE.”
— Sun Ro Lee, Cloud Engineer, LINE Plus
High-level Executive Excerpt
LINE transformed OpenSearch from a basic log storage solution into the core search and AI backbone for its global platform. Through multi AZ architecture, automated data lifecycle, high performance storage, and a focused roadmap for AI agents, LINE now runs nearly 1,300 clusters supporting over 10 petabytes of data with zero data loss. The company is poised to deliver agentic search capabilities at scale, powered by fully managed embeddings, GPU acceleration, and unified security.
Learn More
- Watch the full keynote from Sun Ro Lee at OpenSearchCon Korea.
Visit LINE Corporation to learn about their platform and engineering initiatives: https://line.me