

We’re excited to announce the release of the OpenSearch Hadoop connector 2.0. Key updates include Apache Spark 3.5 and 4 support, OpenSearch 3.x compatibility, Amazon OpenSearch Serverless support, and more.
We’ve also published new Hadoop connector documentation that describes setup, usage examples, and configuration options. This post introduces the Hadoop connector and describes the new features in version 2.0.
TL;DR: OpenSearch Hadoop connector 2.0 adds Spark 3.5 and 4 support, OpenSearch 3.x compatibility, and Amazon OpenSearch Serverless integration. The connector parallelizes reads and writes across Spark partitions and OpenSearch shards for efficient large-scale data processing.
What is the Hadoop connector?
The Hadoop connector enables reading and writing data between Apache Spark, Apache Hive, Hadoop MapReduce, and OpenSearch. Because these systems are distributed, the connector parallelizes reads and writes across compute partitions and OpenSearch shards, enabling efficient processing of large data volumes, as shown in the following image.
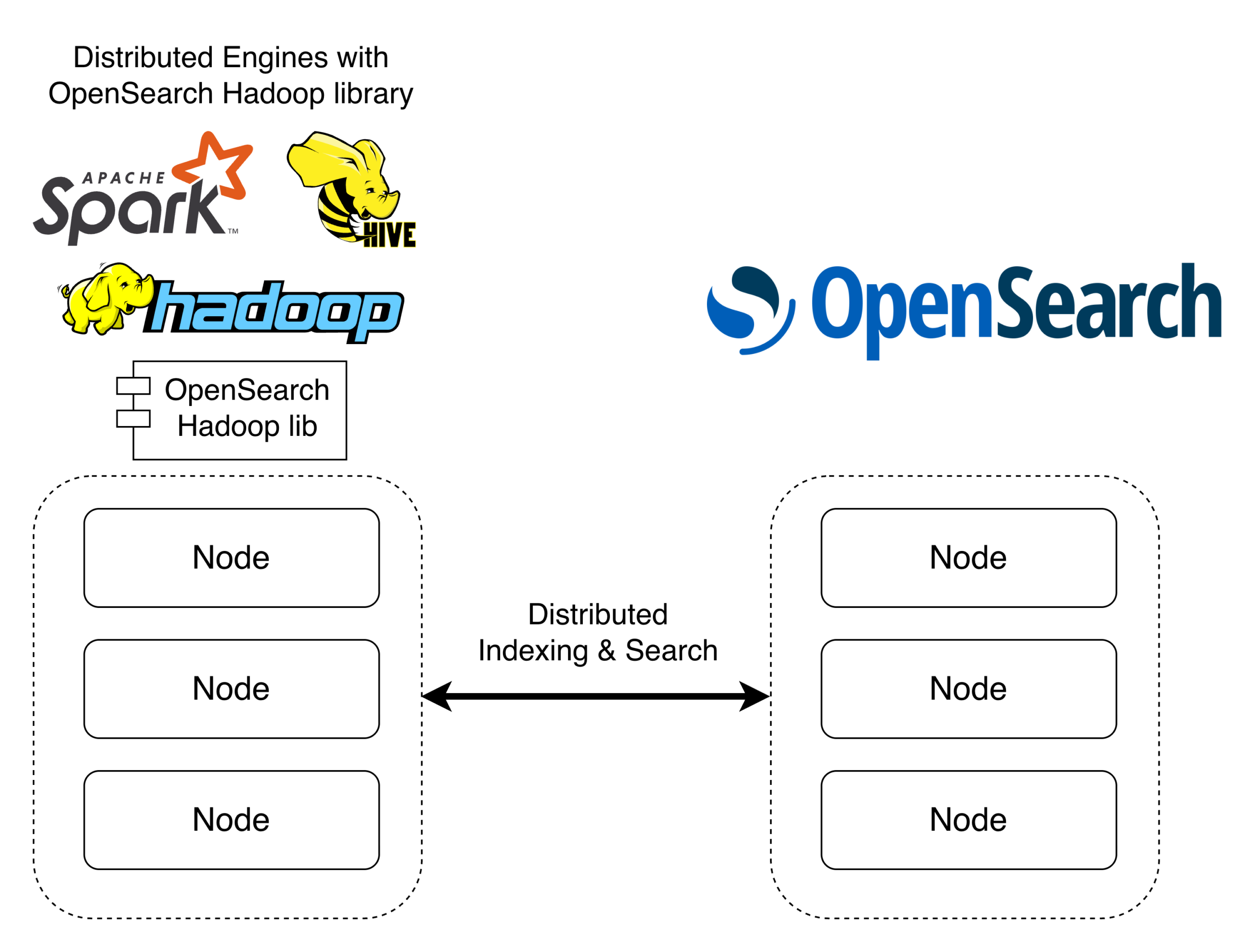
What’s new in Hadoop connector 2.0
The 2.0 release brings the following major features and improvements.
Apache Spark 3.5 and 4 support
The Hadoop connector 2.0 introduces dedicated modules for Spark 3.5 and Spark 4 alongside the existing Spark 3.4 module. Choose the artifact that matches your Spark and Scala version.
| Spark version | Scala version | Artifact |
|---|---|---|
| 3.4.x | 2.12 | org.opensearch.client:opensearch-spark-30_2.12:2.0.0 |
| 3.4.x | 2.13 | org.opensearch.client:opensearch-spark-30_2.13:2.0.0 |
| 3.5.x | 2.12 | org.opensearch.client:opensearch-spark-35_2.12:2.0.0 |
| 3.5.x | 2.13 | org.opensearch.client:opensearch-spark-35_2.13:2.0.0 |
| 4.x | 2.13 | org.opensearch.client:opensearch-spark-40_2.13:2.0.0 |
The Spark 3.5 module lets you use the connector on platforms that include Spark 3.5. The Spark 4 module brings support for the latest Spark release, including Spark 4.0 and 4.1, so you can take advantage of the newest Spark features while reading and writing data to OpenSearch.
To try the connector with Spark 4, launch a PySpark shell with the connector loaded using --packages:
pyspark --packages org.opensearch.client:opensearch-spark-40_2.13:2.0.0
Then write and read data:
# Write documents to OpenSearch df = spark.createDataFrame([("John", 30), ("Jane", 25)], ["name", "age"]) df.write.format("opensearch") \ .option("opensearch.nodes", "<opensearch host>") \ .option("opensearch.port", "<port>") \ .save("people") # Read documents from OpenSearch df = spark.read.format("opensearch") \ .option("opensearch.nodes", "<opensearch host>") \ .option("opensearch.port", "<port>") \ .load("people") df.show()
You can also push queries down to OpenSearch so that only matching documents are transferred to Spark:
filtered = spark.read \ .format("opensearch") \ .option("opensearch.nodes", "<opensearch host>") \ .option("opensearch.port", "<port>") \ .option("opensearch.query", '{"query":{"match":{"name":"John"}}}') \ .load("people") filtered.show()
For authentication options and Scala, Java, and Spark SQL examples, see the Hadoop connector documentation.
Amazon OpenSearch Serverless support
You can now use the connector with Amazon OpenSearch Serverless collections. Configure the connector with AWS Signature Version 4 authentication and the aoss service name:
df.write.format("opensearch") \ .option("opensearch.nodes", "https://<collection-id>.<region>.aoss.amazonaws.com") \ .option("opensearch.port", "443") \ .option("opensearch.nodes.wan.only", "true") \ .option("opensearch.net.ssl", "true") \ .option("opensearch.aws.sigv4.enabled", "true") \ .option("opensearch.aws.sigv4.region", "<region>") \ .option("opensearch.aws.sigv4.service.name", "aoss") \ .option("opensearch.serverless", "true") \ .save("my-collection")
OpenSearch 3.x compatibility
Because the connector communicates with OpenSearch through its REST API, it already worked with OpenSearch 3.x. This release updates the build and test infrastructure to officially support OpenSearch 3.x clusters.
Other notable changes
This release includes the following additional changes:
- The legacy Spark 2.x module has been removed.
- The AWS authentication layer has been migrated from AWS SDK v1 to v2, bringing support for newer credential providers and aligning with the AWS SDK v1 end-of-maintenance timeline.
- The minimum runtime JDK has been raised from 8 to 11, and the minimum build JDK is now 21.
- Various bug fixes have improved overall stability. For the full list of changes, see the CHANGELOG.
Getting started
Use the following resources to get started with the Hadoop connector 2.0:
- To download the Hadoop connector, see the Maven Central artifacts.
- For usage examples and configuration options, see the Hadoop connector documentation.
- To learn more about the project, see the Hadoop connector repository.
We welcome your feedback about this release. If you have questions or suggestions, please visit the community forum or open an issue on GitHub.
