

Have you ever built a contact center AI agent only to realize it treats every call like the first one? Most contact center systems lose conversational context the moment a call ends. The life events, preferences, and concerns that emerge naturally in conversation—the information that would make your agent genuinely helpful—don’t persist to the next interaction.
In this post, we’ll show how OpenSearch agentic memory provides your contact center AI agent with persistent, personalized memory across calls by employing semantic search for targeted retrieval and three memory strategies—semantic (facts), user preference (preferences), and summary (session context)—working simultaneously. We’ll use a wealth management contact center agent as a running example throughout this post. Wealth management is a natural fit because the customer conversations are inherently unstructured and evolving: clients discuss retirement plans, life changes, and risk preferences across multiple calls over months or years. No single call tells the full story, and the context that your agent needs changes as the client’s life evolves. This makes it an ideal scenario to demonstrate all three memory strategies working together.
TL;DR
OpenSearch agentic memory lets contact center AI agents remember customers across every call.
- Extracts facts, preferences, and summaries automatically
- Retrieves only relevant context per turn via semantic search
- Customers stop repeating themselves
- Works with any agent framework on OpenSearch 3.6.0+
What is memory for an AI agent?
Large language models (LLMs) are stateless: every conversation starts without prior knowledge. If your AI agent needs to remember any information across your interactions, the memory must be built externally. An effective memory system must provide three capabilities: store relevant information automatically as conversations happen, retrieve the correct memories at the appropriate time, and evolve them as new information arrives. For a deeper look at how these capabilities work internally, see the OpenSearch as an agentic memory solution blog post.
Why OpenSearch for agentic memory
For many use cases, vector similarity alone is enough to get started. But as a contact center scales, queries that retrieve information may need to combine semantic relevance, keyword precision, and temporal filtering (such as searching for “conversations about retirement planning” with keyword “portfolio rebalancing” during “the last 90 days”). OpenSearch supports all three capabilities through native hybrid search so you don’t have to combine multiple systems.
OpenSearch also delegates both short-term and long-term memory construction from the agent to the data store. Short-term memory (session context and running summaries) and long-term memory (extracted facts and user preferences) are both managed on the server side through agentic memory processing strategies. Rather than building extraction, embedding, and memory management logic into your agent code, you send a conversation and let OpenSearch manage these operations. Your agent stays focused on the conversation, and you can improve extraction quality or swap embedding models without modifying agent code.
Agentic memory provides the following capabilities in the API:
- Memory containers — Per-customer isolation through namespaces within a single container.
- Three processing strategies —
SEMANTIC(facts),USER_PREFERENCE(preferences), andSUMMARY(session context) run simultaneously. - Automatic fact extraction — Automatic extraction of structured facts, preferences, and summaries when you add a conversation specifying
infer: true. - Semantic search — Natural language queries that retrieve relevant memories.
To configure agentic memory in OpenSearch from scratch, see the OpenSearch agentic memory blog post.
Building the contact center agent
This section describes the components and implementation approach for integrating agentic memory into a contact center AI agent.
Prerequisites
To follow along with the examples in this post, you need the following components:
- OpenSearch 3.6.0 or later — The semantic and hybrid search APIs for agentic memory used in this post require OpenSearch 3.6.0. You can run OpenSearch locally using Docker.
- A registered LLM for fact extraction. LLMs are usually registered using a remote connector to a hosted API (for example, Amazon Bedrock, OpenAI, or Cohere).
- A registered text embedding model for semantic search. We recommend using an externally hosted model, such as Amazon Titan Embeddings, OpenAI, or Cohere Embed, so embedding capacity scales independently of your OpenSearch cluster. You can also use a pretrained local model (for example,
all-MiniLM-L12-v2) for quick experimentation.
Each customer call follows the lifecycle shown in the following image.

Figure 1: Call Lifecycle—three phases of a session: greet, converse, and remember.
The lifecycle consists of three phases:
- Greet: The agent retrieves the customer’s name and relevant context from memory.
- Converse: The agent searches for specific memories on demand as the conversation requires them.
- Remember: When the call ends, the agent stores the entire conversation in agentic memory.
Using agentic memory
Agentic memory persists information between sessions. During a call, the conversation context is managed by the agent framework itself (the LLM context window and session state). After each call, agentic memory stores important information. During subsequent calls, the agent retrieves specific memories on demand rather than loading all historical context initially.
Storing conversations in memory
When the agent sends a conversation specifying infer: true:
- OpenSearch stores the raw conversation in working memory as an unprocessed transcript.
- The LLM extracts structured knowledge and stores it in long-term memory. This structured knowledge includes facts, preferences, and summaries, each containing an embedding for semantic search.
When infer is false (the default), OpenSearch completes only Step 1: it stores the raw conversation in working memory but does not extract structured knowledge.
At query time, the agent reads from long-term memory using semantic search, querying for specific information needed in the conversation (for example, “retirement plans” or “risk tolerance”). Working memory serves as a raw conversation log—useful for auditing, debugging, or extracting knowledge if you change your LLM or strategies later—but is not queried by the agent during conversations.
User isolation within a memory container
All users share the same physical storage (working and long-term indexes) within a memory container. Isolation is logical, not physical: each memory is tagged with a namespace (in our case, customer_id set to the caller’s phone number). When the agent searches for memories, it filters them by namespace so each client only sees their own history, as shown in the following diagram.
Memory Container
├── working index (shared by all users)
│ ├── messages: [raw conversation turns]
│ ├── namespace: {customer_id: "+1-555-0123"} ← per-user filter
│ └── infer: true/false
│
└── long-term index (shared by all users)
├── memory: "Client prefers conservative investments" ← extracted knowledge
├── memory_embedding: [...] ← for semantic search
├── strategy_type: SEMANTIC | USER_PREFERENCE | SUMMARY
└── namespace: {customer_id: "+1-555-0123"} ← per-user filter
To demonstrate this end-to-end process, we integrated agentic memory into a voice-based AI agent for a wealth management contact center. The agent handled phone calls using a speech-to-speech LLM but lacked the ability to remember clients across calls.
With agentic memory added, the agent:
- Remembers every client across calls using three memory strategies (
SEMANTIC,USER_PREFERENCE, andSUMMARY) simultaneously. - Retrieves only relevant memories using semantic and hybrid search.
- Builds a richer picture of each client over time, without any custom memory infrastructure.
The following examples compare the customer experience without memory and with agentic memory.
Without memory: Every call starts without prior knowledge
Call 1 — Retirement planning: A client calls to discuss retiring in five years. The client explains portfolio details, risk concerns, and timeline. The agent has a productive conversation. Agent: “A five-year timeline gives us good room to rebalance gradually. Shall I prepare some options for you and your wife to review together?”
Call 2 — The client calls back about a life change: Client: “I’ve been thinking about what we discussed. Also, my wife and I are thinking about moving to a smaller house.” Agent: “I’d be happy to help. Could you tell me a bit about your current financial situation and goals?”
The agent has no idea what “what we discussed” refers to. The client has to explain the retirement plan, portfolio composition, and risk preferences from scratch.
Call 3 — The client mentions a new goal: Client: “My daughter just had a baby. I want to set up an education fund for my grandchild.” Agent: “That’s wonderful! I can help with education fund options. What’s your current financial situation and risk tolerance?”
The agent cannot link the education fund to the retirement plan or the home sale because it doesn’t know about either one.
With agentic memory: Context persists
Call 1 — Retirement planning: A client calls to discuss retiring in five years. The client has a sizable portfolio and wants to make more conservative investments. The AI agent discusses options, and the conversation (including the client’s risk concerns and timeline) is automatically extracted and stored in memory.
Call 2 — Life change: The same client calls a month later. Client: “I’ve been thinking about what we discussed. Also, my wife and I are thinking about moving to a smaller house.” Agent: “Welcome back! Last time we talked about shifting your portfolio toward more conservative investments ahead of your retirement in five years. Selling your current home could free up significant capital—would you like me to model how the proceeds might accelerate your rebalancing timeline? I can prepare options for you and your wife to review together, the way you prefer.”
Call 3—New goal: Client: “My daughter just had a baby. I want to set up an education fund for my grandchild.” Agent: “Congratulations! Given your retirement plan and the potential home sale we discussed, you have some flexibility. A conservative education fund that complements your overall plan would make sense—and it wouldn’t require changing your rebalancing strategy. Shall I put together a few options for you and your wife to review?”
The client mentions an “education fund,” and the agent interprets it in the context of their broader financial life.
Without memory, every interaction starts from scratch. Clients repeat themselves, agents lack context, and opportunities to deepen the relationship are lost. A client may mention selling their house, but without awareness of their retirement plan, the agent cannot establish the relationship. A grandchild may be born, but without the full financial picture, the agent can only offer generic advice instead of tailored guidance.
With memory, the agent continues from where the previous conversation ended. Clients feel understood. Agents spend more time advising and less time gathering context. And when a life event creates a new financial need, the agent recognizes it—because it remembers the full picture.
The difference isn’t just efficiency. It’s the difference between a service that processes transactions and one that builds relationships.
Architecture overview
The architecture is intentionally component-agnostic. You can swap in any preferred components—the memory layer remains the same whether the agent is voice-based, chat-based, or API-driven. In our implementation, we used a contact center with a speech-to-speech LLM, but the OpenSearch components (Agentic Memory, along with the supporting LLM and embedding models) are consistent across all agent types, as shown in the following image.
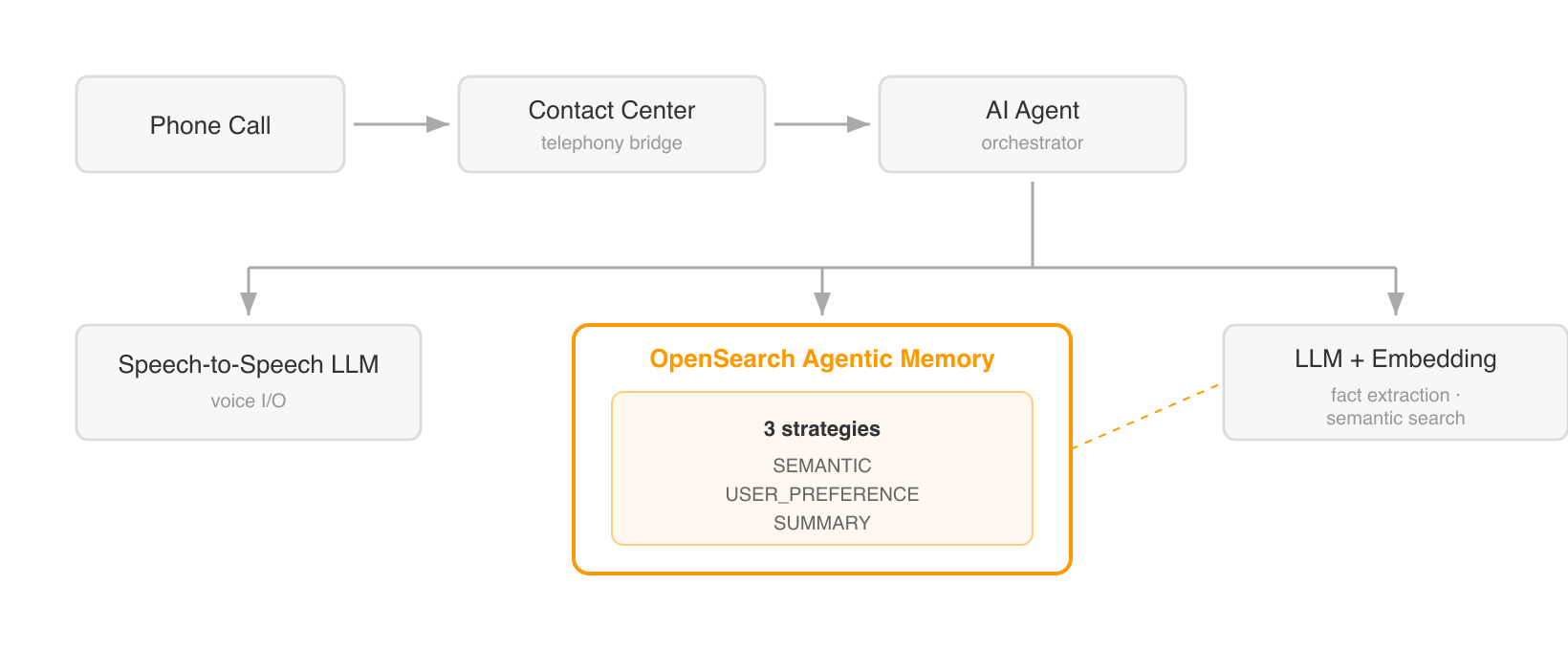
Figure 2: Architecture overview—AI Agent orchestrates S2S LLM, OpenSearch agentic memory, and the LLM + Embedding model used by memory.
The architecture includes the following components:
- Contact center — Receives calls and bridges telephony to the AI agent. Cloud-based or on-premises—the memory layer works the same.
- AI agent — Orchestrates the conversation. Searches memory on demand during the call, writes memory when the call ends, applies business logic, constructs prompts.
- Speech-to-speech LLM — The agent’s voice interface. Handles speech input and output.
- OpenSearch agentic memory — The persistent memory layer. This is the focus of this post.
- LLM + embedding model — Powers fact extraction (through inference) and semantic search within agentic memory.
Deep dive: Three memory strategies working together
OpenSearch agentic memory supports three memory strategies that run simultaneously in a single memory container. Each captures a different dimension of the conversation:
- SEMANTIC—Captures facts and life events: retirement targets, portfolio composition, and family changes.
- USER_PREFERENCE—Captures how the client wants to be served: risk tolerance, communication style, and decision-making preferences.
- SUMMARY—Captures condensed session context: what was discussed, what was decided, and what is pending.
You configure all three memory strategies when creating a memory container. Each client’s memories are isolated by namespace—you don’t need a separate container for each client. Here’s an example container with all three strategies:
POST /_plugins/_ml/memory_containers/_create
{
"name": "wealth-advisor",
"configuration": {
"embedding_model_type": "TEXT_EMBEDDING",
"embedding_model_id": "your-embedding-model-id",
"embedding_dimension": 1024,
"llm_id": "your-llm-model-id",
"strategies": [
{ "type": "SEMANTIC", "namespace": ["customer_id"] },
{ "type": "USER_PREFERENCE", "namespace": ["customer_id"] },
{ "type": "SUMMARY", "namespace": ["customer_id"] }
]
}
}
For the full container creation API and configuration options, see the agentic memory documentation.
Customizing extraction for a strategy
Each strategy accepts an optional system_prompt in its configuration, letting you steer what gets extracted. For a wealth management agent, you might narrow SEMANTIC to focus on financial facts (retirement timelines, portfolio composition, life events that affect planning) and ignore off-topic chitchat. USER_PREFERENCE can be tuned to capture decision-making style (e.g., spousal involvement, risk tolerance) rather than surface preferences like “prefers email.” These custom prompts trade generality for precision, which pays off when your domain has a clear vocabulary.
How they work together: The wealth management flow
The following examples demonstrate how the three memory strategies work together across multiple customer calls.
Call 1 — Retirement planning:
The client calls to discuss retirement. When the call ends, the agent sends the entire conversation to agentic memory:
POST /_plugins/_ml/memory_containers/<container_id>/memories
{
"messages": [
{
"role": "user",
"content": [{ "text": "I'm thinking about retiring in about five years. My portfolio is mostly in equities and I'm getting nervous about volatility. I'd like to start shifting to something more conservative.", "type": "text" }]
},
{
"role": "assistant",
"content": [{ "text": "That makes sense given your timeline. We could gradually rebalance toward a mix of bonds and dividend-paying stocks. Would you like me to prepare some options for you and your wife to review together?", "type": "text" }]
},
{
"role": "user",
"content": [{ "text": "Yes, please. She'll want to see the numbers before we decide anything.", "type": "text" }]
}
],
"payload_type": "conversational",
"infer": true,
"namespace": { "customer_id": "+1-555-0123" },
"tags": { "topic": "retirement_planning" }
}
When infer is true, the LLM automatically extracts facts (SEMANTIC: retirement in 5 years, equity-heavy portfolio), detects preferences (USER_PREFERENCE: conservative, spouse involved in decisions), and generates a session summary (SUMMARY). The extracted knowledge is stored in long-term memory, where it becomes searchable using semantic search. Without infer: true (the default is false), messages are stored as raw data only, which is useful for logging but is not searchable by meaning. By sending the full conversation at once rather than in individual turns, the LLM has the complete context in order to extract richer, more coherent facts and preferences.
Why save at call end, not per-turn?
The LLM produces better extractions when it sees the full conversation at once. It can connect “retiring in five years” from one turn with “my wife wants to see the numbers” from another turn in order to infer a joint decision-making preference. Per-turn saving would extract these as isolated facts—“client plans to retire” and “client’s wife wants to see numbers”—missing the relationship between them. These fragmented facts add noise at retrieval time without capturing the insight that matters.
Call 2 — Life change:
The same client calls a month later. The contact flow searches for the client’s name and generates a personalized greeting: “Welcome back!” The name search uses the same semantic search API, where k specifies the maximum number of results to return:
POST /_plugins/_ml/memory_containers/<container_id>/memories/long-term/_semantic_search
{
"query": "customer name",
"k": 3,
"namespace": { "customer_id": "+1-555-0123" }
}
Then the conversation begins. When the client mentions “what we discussed,” the agent prompts the LLM to formulate a retrieval query based on the current conversation turn. The LLM might produce something like “retirement planning portfolio rebalancing”—a specific, targeted query rather than a predefined one:
POST /_plugins/_ml/memory_containers/<container_id>/memories/long-term/_semantic_search
{
"query": "retirement planning portfolio rebalancing",
// ^ generated by the LLM from the live conversation; different turns produce different queries
"k": 10,
"namespace": { "customer_id": "+1-555-0123" }
}
The agent finds the retirement timeline, risk preference, and that the spouse is involved, so it can immediately connect the move to the existing plan: “Selling your current home could free up significant capital—would you like me to model how the proceeds might accelerate your rebalancing timeline?”
Call 3 — New goal:
The client mentions an education fund for a grandchild. Given this new topic, the agent asks the LLM to generate a retrieval query that will provide the client’s broader financial context. The LLM might produce a search query like “financial situation retirement savings”—shaped by the current conversation, not a fixed template:
POST /_plugins/_ml/memory_containers/<container_id>/memories/long-term/_semantic_search
{
"query": "financial situation retirement savings",
// ^ generated by the LLM based on what the client just said
"k": 10,
"namespace": { "customer_id": "+1-555-0123" }
}
With the complete context retrieved, the agent responds:
“Congratulations! Given your retirement in about five years and the potential home sale, we have some flexibility. A conservative education fund that complements your overall plan would make sense. Shall I prepare options for you and your wife to review?”
The agent remembered the retirement timeline, the home sale discussion, the conservative preference, and that the spouse wants to be involved—all from previous calls.
Semantic and hybrid search: Finding what matters
Before semantic search was introduced in OpenSearch, retrieving memories required manually constructing k-nearest neighbors (k-NN) queries with pregenerated embeddings. The semantic search and hybrid search APIs dramatically simplify memory retrieval.
Semantic search
Using semantic search, you can send a natural language query and receive semantically relevant memories. OpenSearch handles embedding generation and vector search automatically:
POST /_plugins/_ml/memory_containers/<container_id>/memories/long-term/_semantic_search
{
"query": "client risk tolerance and investment preferences",
"k": 5,
"namespace": { "customer_id": "+1-555-0123" },
"min_score": 0.6
}
This query returns memories about the client’s conservative stance and preference for gradual changes—even if those exact words never appeared in the stored conversations. A typical response appears as follows:
{
"hits": {
"hits": [
{
"_source": {
"memory": "Client prefers conservative investments and wants to shift away from equities",
"strategy_type": "USER_PREFERENCE",
"namespace": { "customer_id": "+1-555-0123" }
}
},
{
"_source": {
"memory": "Client plans to retire in five years with a gradual rebalancing strategy",
"strategy_type": "SEMANTIC",
"namespace": { "customer_id": "+1-555-0123" }
}
}
]
}
}
Each result includes the extracted memory text, the strategy_type that produced it, and the namespace it belongs to. Your agent reads the memory field and injects the relevant facts into its prompt.
In our implementation, the agent uses semantic search on demand during the conversation. When a client asks “what was my retirement target?”, the agent searches for memories using the query query="retirement savings target" and retrieves only the relevant results. When the conversation turns to investment preferences, the agent searches for memories using the query query="investment risk tolerance". This keeps each retrieval focused and avoids loading irrelevant context into the LLM prompt.
Why on-demand search instead of loading all memories initially
A simpler approach is to load all of a client’s memories at the start of each call and inject them into the LLM prompt. This works initially, but as memories accumulate across sessions, two issues emerge: the prompt becomes overloaded with irrelevant context, and a fixed query cannot anticipate what the conversation will require.
On-demand search solves both problems—the agent retrieves only what is relevant to the current turn, and the query is shaped by the actual conversation.
How strategies function at search time
The three memory strategies (SEMANTIC, USER_PREFERENCE, SUMMARY) define different extraction pipelines at write time. However, at search time, semantic search queries all strategies in a single index. There is no strategy-level filter; results are ranked purely by embedding similarity.
This produces a useful emergent behavior: the query naturally surfaces memories from the most relevant strategy. Testing with real conversation data demonstrates the following patterns:
- “what are my preferences” → top results: risk tolerance, communication style, decision-making preferences. Dominant strategy:
USER_PREFERENCE. - “summarize our past conversations” → top results: session summaries, conversation flow notes. Dominant strategy:
SUMMARY. - “retirement age and savings” → top results: age, retirement date, savings amounts. Dominant strategy:
SEMANTIC, with someUSER_PREFERENCE.
This is not a designed routing mechanism—it emerges from how each strategy shapes the extracted text and its resulting embedding. USER_PREFERENCE memories contain preference-oriented language, SUMMARY memories contain summary-oriented language, and semantic search matches accordingly.
The practical implication is that you do not need strategy-aware retrieval logic. A single semantic search query returns the appropriate mix of results.
To make this concrete in the wealth management example: when a call opens with a broad cue like “what we discussed,” semantic search tends to surface SUMMARY memories (the session-level view of the prior retirement planning discussion) alongside SEMANTIC facts, because the query reflects a session-level intent. More specific follow-up queries, such as “retirement planning portfolio rebalancing,” rely more heavily on SEMANTIC facts, while questions about how the client prefers to be served draw from USER_PREFERENCE.
The benefit of running all three strategies at write time is that you don’t need to predict which perspective a future conversation will require. Whatever query the LLM generates, the appropriate representation of memory is already available.
Hybrid search
For queries that benefit from both keyword precision and semantic understanding, agentic memory also provides a _hybrid_search endpoint that combines BM25 keyword matching and neural search. In our implementation, semantic search was sufficient. However, hybrid search is available when you need exact keyword matching alongside semantic relevance:
POST /_plugins/_ml/memory_containers/<container_id>/memories/long-term/_hybrid_search
{
"query": "retirement timeline five years portfolio rebalancing",
"k": 10,
"namespace": { "customer_id": "+1-555-0123" }
}
This query finds the exact timeline mentioned (keyword match) and the related financial planning context (semantic match).
Note: The _hybrid_search endpoint is newer than _semantic_search. For the full API specification, see the hybrid search API reference. The Hybrid Search API returns results ranked by a combination of BM25 keyword scores and embedding similarity scores.
Best practices for agentic memory
The following tips are based on building and testing this system:
- Design your namespace early: Choose a namespace key that is available at the start of every session without requiring user input. We used the caller’s phone number because it is provided automatically by the telephony system. For a chat agent, an authenticated user ID works well. The key requirement is that it remains stable across sessions and is available before the conversation begins.
- Choose a capable LLM for fact extraction: The
USER_PREFERENCEstrategy produces structured JSON with categories and context annotations, which requires a model that reliably generates well-formed JSON. We observed the best results with a capable model such as Anthropic Claude Sonnet, although smaller models may also work depending on extraction complexity. Test each strategy with the selected LLM and monitor long-term memory counts by thestrategy_typefield to ensure all strategies produce output. - Design queries to be specific: With on-demand retrieval, search quality depends on the query. A query such as “customer information” returns a broad mix of facts, whereas a query like “retirement timeline” or “investment risk tolerance” returns more targeted results. The agent constructs queries from the conversation context, so prompts should encourage specificity.
- Select an appropriate embedding model: Agentic memory supports both pretrained local models and remote connectors for embeddings. For production, a remote model (for example, Amazon Titan Embeddings, OpenAI, or Cohere Embed) allows embedding capacity to scale independently of the OpenSearch cluster and enables model upgrades without redeployment. Local pretrained models (for example,
all-MiniLM-L12-v2) are useful for experimentation, but verify semantic search quality before production use. - Add graceful fallback handling: Wrapping memory operations in error handling ensures the agent remains responsive if OpenSearch is temporarily unavailable. In this case, the agent falls back to a stateless conversation until memory access is restored.
- Combine semantic search with recency when needed: For queries where recent information is critical (for example, “current portfolio allocation”), combine semantic results with the most recent N memories by
created_timeto avoid missing recent updates. - Tune recall parameters for your use case: The value of
kdirectly affects retrieval. For targeted queries, a moderatek(5–10) is typically sufficient. Query specificity has a greater impact thank—a well-targeted query withk=5often outperforms a generic query withk=50. Monitor retrieval quality in production and adjust as memory volume grows.
Conclusion
Contact center AI agents that forget customers after every call aren’t just inefficient—they miss an opportunity. The information that makes an advisor effective—life events, preferences, and conversation history—already emerges in natural conversation. The challenge is capturing that information systematically and retrieving that information when needed.
OpenSearch Agentic Memory turns this approach into a set of API calls. Three strategies run in parallel to extract facts, learn preferences, and summarize session context—all from the same conversation, enabled by a single infer: true flag. Semantic search allows the agent to retrieve only the memories relevant to the current moment in the conversation, rather than loading everything the agent has stored.
We built this system for wealth management, where client relationships span years and context accumulates with each interaction. The same pattern applies wherever an agent’s value depends on memory: insurance claims, healthcare follow-ups, technical support escalations, or any domain where customers expect continuity.
Get started
Ready to add persistent memory to your AI agent? Try OpenSearch agentic memory and explore the agentic memory documentation. We’d love to hear about your experience—share your questions, use cases, and feedback on the OpenSearch forum.




