

Notes from experimenting with agents in knowledge-base, development, performance, and on-call workflows—and the verification loops that make them trustworthy.
Efficiency gains are a priority for every engineering team. The OpenSearch team has been experimenting with AI agents across our software development lifecycle (SDLC). The goal: let agents do the repetitive work so engineers can focus on higher-order tasks—defining vision, designing architecture, and deciding what to build. In this blog post, we’ll share what we’ve built and what we’ve learned.
TL;DR: The OpenSearch team built four AI agents that automate SDLC work, each validated by its own verification loop rather than human review alone.
- Atlas—living knowledge base, deduplicated on every update
- Ralph—parallel dev pipeline, verified against a live local stack
- Nitro—performance optimizer, A/B-tested against benchmarks
- Sentinel—on-call triage, gated by human approval before execution
From generation to trust
Across all SDLC phases, AI agents now generate code, root-cause analyses, remediation plans, performance fixes, and standard operating procedures (SOPs) faster than humans can meaningfully review them. The bottleneck is no longer generation; it’s deciding whether to trust what has been generated.
To build trust in agent output, we built four agents that work together across the SDLC: a foundational knowledge base, plus three phase-specific agents for development, performance, and on-call operations. Each agent runs inside its own automated verification loop (harness) that validates agent output before accepting it. These loops take different forms: deduplication for knowledge bases, live integration testing for development, benchmarks for performance, and human approval for operations. All four agents share one design principle: the loop encodes quality standards and the agent generates output that the loop validates.
These agents are currently internal experiments rather than open-source releases. We’re sharing what we learned while developing these agents because the underlying patterns can be generalized beyond a single system. The patterns include harness-first verification, plan-then-approve safety, ticket-to-SOP extraction, and production-data grounding. If you’re building agentic tooling for OpenSearch or any other large system, you can adapt these approaches.
The four agents and how they work together
The following diagram shows how the four agents work together across the SDLC.
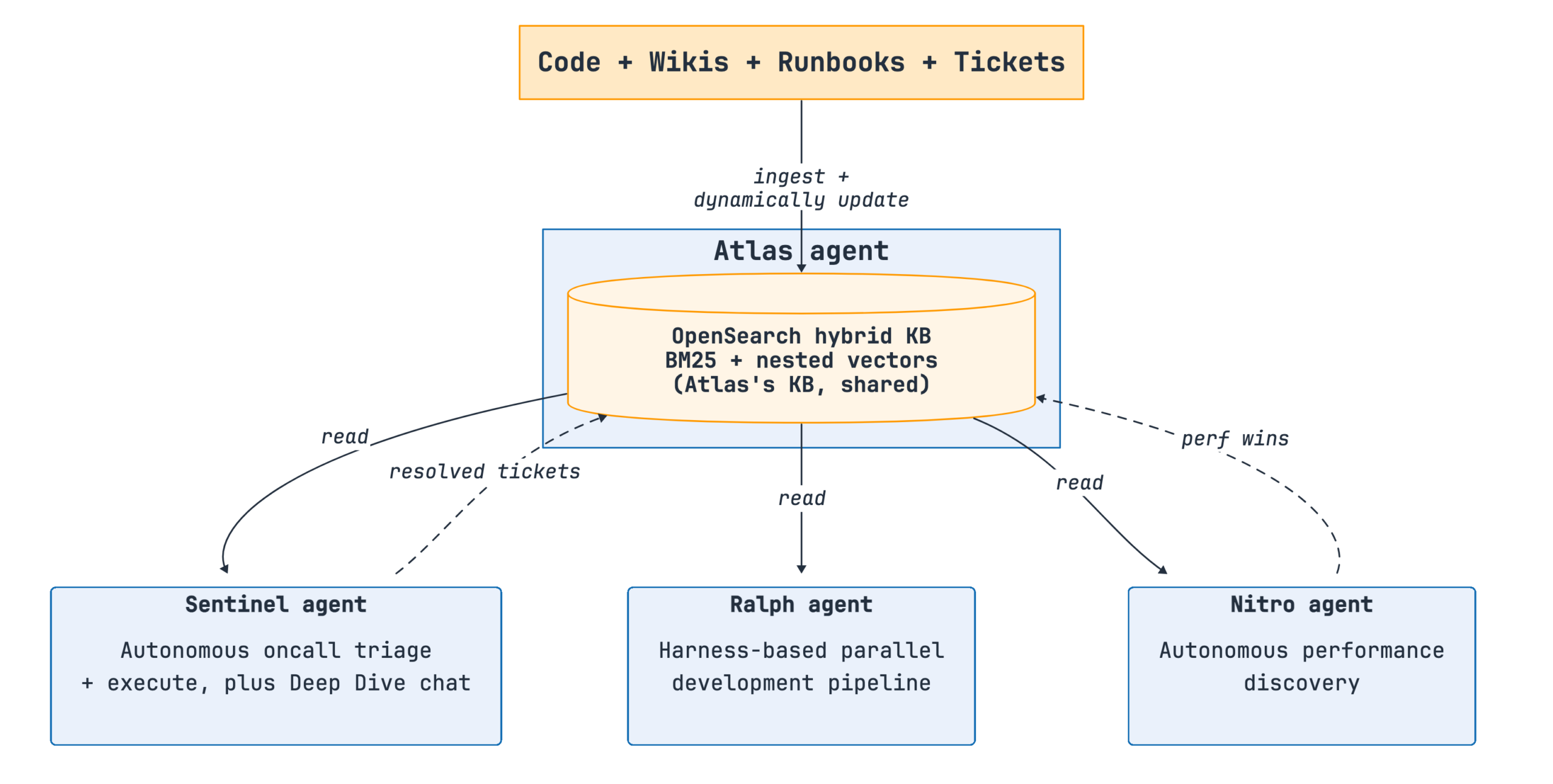
Figure 1: The four agents—Atlas, Ralph, Nitro, and Sentinel—working together across the SDLC and sharing a common knowledge base.
Each agent serves a distinct role:
- Atlas (a real-time knowledge base) – Automatically updates itself using source code, wiki articles, runbooks, and resolved tickets.
- Ralph (a test-driven parallel development pipeline) – Launches the service stack locally, decomposes a feature specification into tasks, and distributes tasks across coordinator, developer, quality assurance (QA), and validator agents that verify output against a live integration stack at each iteration.
- Nitro (an autonomous performance optimization agent) – Profiles the running system, discovers bottlenecks, and A/B-tests candidate fixes.
- Sentinel (an autonomous on-call agent) – Runs on a cron schedule, reads tickets, proposes remediation plans, and executes after human approval.
The agents run autonomously at different stages of the lifecycle and use the shared knowledge base as a consistent source of truth. Thus, Sentinel’s root cause analysis (RCA), a developer’s chat session, and a new hire’s onboarding workflow all operate from the same knowledge base.
Atlas: The living knowledge base
All agents depend on a current, grounded understanding of the system. Wiki articles and design docs drift. The code is authoritative but difficult for newcomers to approach without context. The most valuable operational data—resolved tickets—exists in unstructured comment threads that are difficult for embedding models to search effectively.
Atlas is a set of workflow skills that converts source code, wiki articles, runbooks, and resolved tickets into a structured, continuously updated shared knowledge base, built on OpenSearch. Each document—a service reference page, an SOP, a design flow—is indexed with its full text alongside nested vector embeddings of its chunks. Retrieval uses hybrid search: BM25 lexical scoring combined with dense-vector similarity. This matters for technical content. A query such as “why is the sort+term aggregation slow on geopoint” combines natural language with specific identifiers (sort+term and geopoint). Pure vector search often misses the identifiers, and pure lexical search misses the paraphrased intent. Hybrid search captures both.
Using OpenSearch as the document store and vector store also keeps Atlas’s operational footprint small. One system processes documents, nested per-chunk vectors, filters, and aggregations so retrieval can filter SOPs by service, status, age, or provenance at query time rather than during post-processing. Though Atlas’s vector store interface is modular and supports other backends, OpenSearch is our primary store and the methodology described in the following sections relies on hybrid search over text and nested vectors.
The following diagram shows the Atlas workflow architecture.
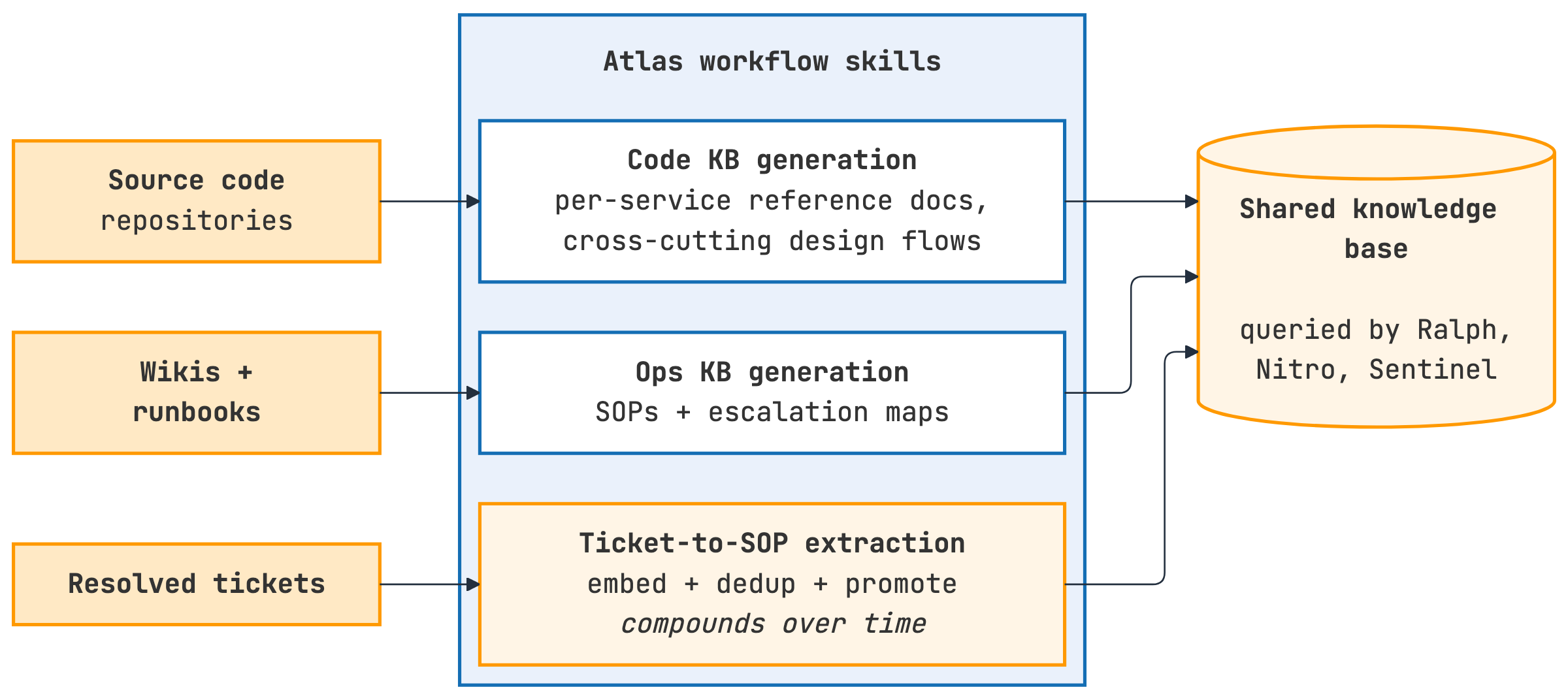
Figure 2: Atlas pipeline—source code, wiki articles, runbooks, and resolved tickets feed into the shared knowledge base through code KB, ops KB, engineering book, and ticket-to-SOP extraction components.
Atlas includes the following components:
- Code KB generation: Analyzes source code repositories to produce per-service reference documentation (API endpoints, data models, and state machines) and cross-service design flows.
- Ops KB generation: Converts wiki articles and runbooks into per-problem SOPs and escalation maps.
- Engineering book generation: Compiles per-package documentation into a browsable engineering reference.
- Ticket-to-SOP extraction: Processes resolved tickets through an incremental pipeline. The pipeline extracts SOPs, deduplicates them against existing SOPs using embedding similarity (a k-NN query against existing SOP chunks). It then indexes the results back into the same OpenSearch cluster and hybrid search interface that downstream agents query.
One representative Atlas run against an internal codebase produced:
- 967 generated files across 160 service packages.
- 819 curated wiki SOPs indexed, plus 99 auto-extracted from resolved tickets.
- A browsable engineering book with 23+ cross-cutting design flow documents across 9 service groups and 100+ packages.
Among the Atlas components, ticket-to-SOP extraction expands the corpus the fastest. Every resolved ticket is processed automatically, and only genuinely new SOPs are added. Over a few months, this produces a deeper corpus than the team could curate manually.
Ralph: Harness-based parallel development pipeline
An agent can produce more code changes per hour than an engineer can review per week. For a system built using many components—OpenSearch core and its plugins (k-NN, ML Commons, and Security), Dashboards, and any services a team builds around it—changes fail during integration, not code review. The critical factor is whether the agent’s changes work against the rest of the system. If that verification waits for a shared remote pipeline, every agent iteration takes hours.
Ralph addresses this problem by using a harness—a live local stack combined with a decomposed feature specification—that verifies agent output on every iteration. This harness-based parallel development pipeline provides a verification surface the agent tests against continuously, rather than a review gate at the end, as shown in the following image.
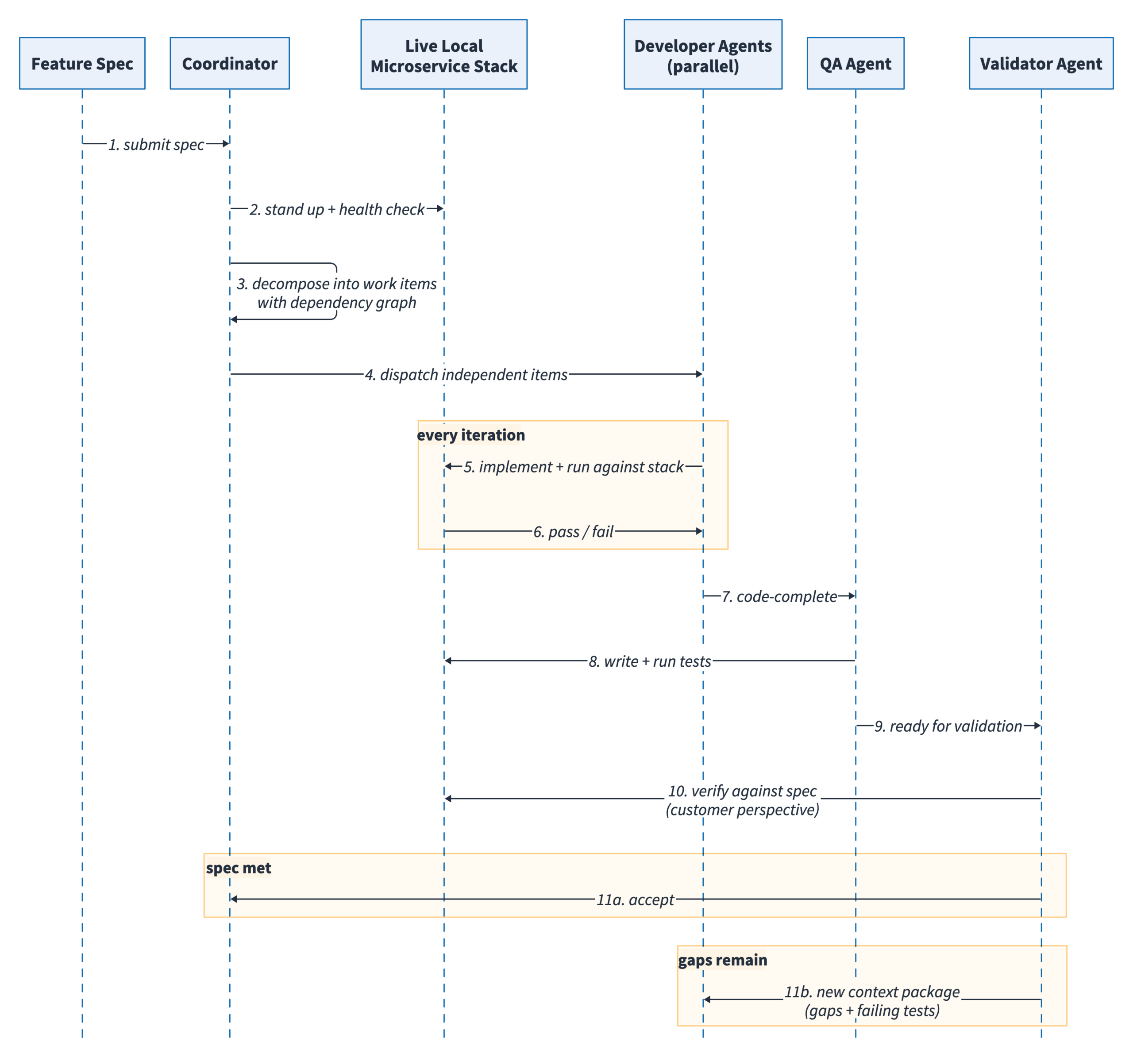
Figure 3: Ralph pipeline—the coordinator launches a live local stack and dispatches decomposed work items to parallel developer, QA, and validator agents that verify output against the running services at each iteration.
The pipeline uses four specialized agent functions:
- Coordinator: Launches all services locally, verifies that all are healthy, and keeps them running throughout the workflow. Parses the feature specification and decomposes it into independent work items, tracking dependencies so downstream items wait for upstream ones.
- Developer agents: The coordinator dispatches each work item to developer agents running in parallel. Each agent implements the assigned task against the live local stack. A dashboard displays the agent assigned to each work item, the system components being modified, and dependency resolution progress. Failed integrations on the local stack are caught and resolved immediately by the agent, preventing broken code from propagating.
- QA agent: Once a work item is code-complete, a QA agent writes tests against the specification and runs the tests. At this stage, a human is most likely to intervene and review the generated tests.
- Validator agent: Reviews every delivered work item against the original specification from a customer perspective. If the specification is not met, the validator composes a new context package—specification gaps, failing tests, and the output produced by the previous agents—and returns it for another development pass.
The harness makes the loop trustworthy. The validator can reject an item because it ran the code against the service boundary, not because it compared a prompt against a specification.
The harness loop catches integration failures in seconds instead of waiting for a remote pipeline run, which makes the rest of the pipeline (parallel developer agents, automated QA, and validator) safe to run autonomously. The pattern transfers directly to anyone developing OpenSearch plugins or services that integrate with OpenSearch: a Docker Compose-based cluster and its surrounding services provide a local stack that lets an agent iterate without waiting for continuous integration (CI).
Nitro: Autonomous performance optimization
Performance optimization—profiling, hypothesizing, patching, and benchmarking—is typically a manual process performed when an engineer has time. For OpenSearch, this means that important improvements (addressing allocation hotspots, GC pressure, and codec inefficiencies) are often delayed. Nitro automates the performance optimization workflow.
Given a system, a workload, and a sandboxed environment, Nitro:
- Provisions ephemeral worker instances, builds the target distribution, and starts the workload.
- Profiles the system by ingesting up to 165 million documents while capturing Java Flight Recorder (JFR) traces, garbage collection (GC) logs, and native memory tracking snapshots.
- Discovers bottlenecks by correlating the profile data and identifying the top allocation hotspots.
- Proposes and A/B tests candidate fixes. The agent builds each candidate fix as a separate distribution and executes all candidates on parallel worker instances alongside an unmodified baseline. The agent runs each candidate multiple times while monitoring throughput, latency, GC time, and merge time.
- Decides which candidates to accept by comparing each against the baseline on the same metrics. Candidates that cause regression are rejected; those that improve performance are accepted.
The following diagram shows the Nitro workflow.
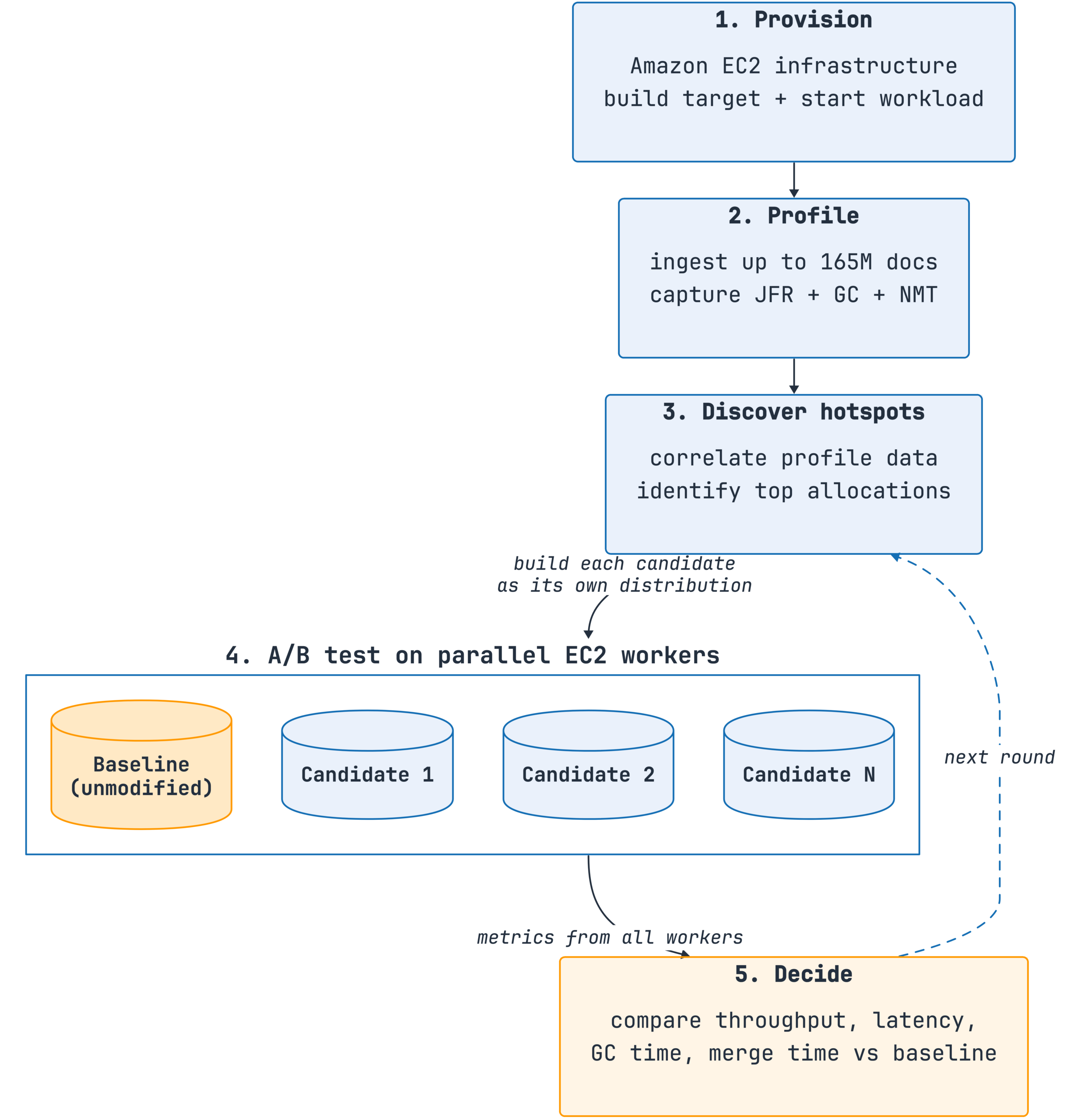
Figure 4: Nitro loop—provision, profile, discover, propose and A/B test, and decide. Candidates that regress are rejected; candidates that improve performance are accepted.
In one test run against OpenSearch 3.3.0, Nitro launched four worker instances (one baseline and three candidates) and ran three benchmark repetitions simultaneously. The agent rejected two candidates for regression and promoted one that showed a 5% improvement in sort+term query latency and a 12% reduction in garbage collection (GC) time on the OpenSearch Benchmark Geopoint workload. Across multiple rounds, the agent produced three validated fixes over approximately 6 days of elapsed time without human intervention.
Building Nitro revealed several key insights:
- Capture every failure as a rule in the instruction file: As we iterated, the instruction file grew longer—not because the agent became less capable, but because we documented failure modes to prevent recurring issues.
- Never let the agent write its own quality gates: When the agent both generates benchmarks and evaluates results, it can learn to optimize for the wrong outcomes. We freeze the evaluation criteria (statistical tests, thresholds, sample sizes) before the agent proposes changes. The team audits the verdict mechanism while the agent evolves the implementation.
- Protect the context window with disposable subagents, and keep the real state on disk: Long-running agent sessions can accumulate context drift. We use focused subagents for specific tasks, each writing results to disk, which keeps the coordinator’s context manageable.
- Build the feedback loop before the agent: The quality of the feedback loop determines the reliability of agent output, regardless of model capability.
Sentinel: Autonomous on-call triage and remediation
On-call consistently reduces engineering throughput. If you operate OpenSearch in production, a busy cluster generates dozens of tickets a week—slow queries, shard imbalance, JVM pressure, ingestion backpressure, or hot nodes. Each ticket starts with the same information gathering stage: pull cluster metrics, read the relevant runbook, scan recent changes, review logs, write the analysis. Sentinel automates the read-only portion of that loop and proposes a remediation plan for human approval; the rest of this section describes how.
Sentinel runs a three-stage pipeline on every ticket in its queue:
- Ingestion: Runs on a cron schedule, reads open tickets, and queues them by priority.
- Context enrichment: Queries the shared knowledge base for relevant SOPs and past tickets and posts them directly on the ticket, providing context for both subsequent agents and human operators.
- Root cause analysis: The agent runs a fixed set of read-only diagnostic commands (metrics, logs, and service-specific health checks), builds an evidence chain, and posts an RCA comment that includes the identified root causes, impact assessment, and recommended next steps.
The following image shows the Sentinel workflow.
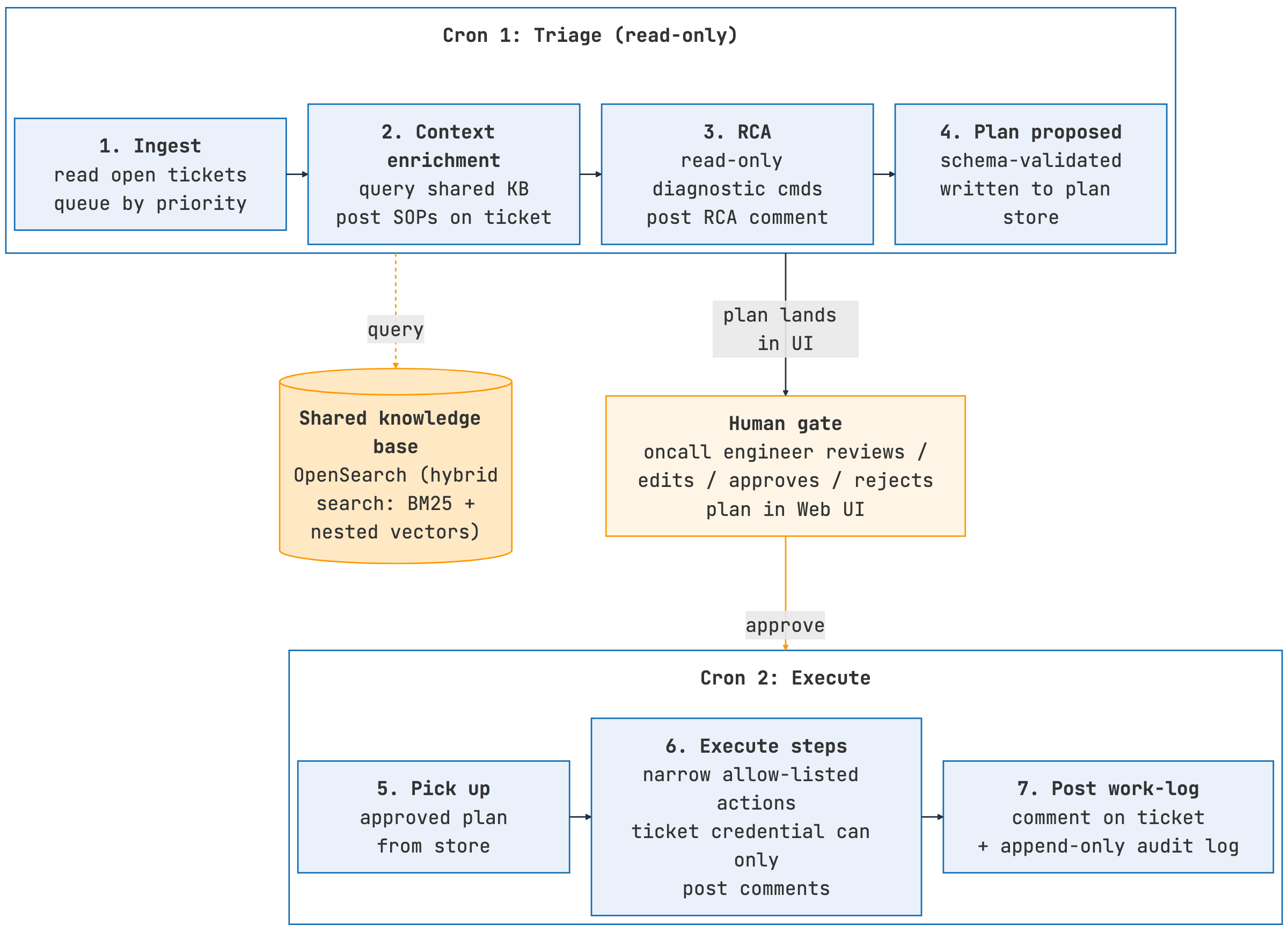
Figure 5: Sentinel pipeline—ingestion on a cron, knowledge-base context enrichment, read-only RCA, and a plan-then-approve workflow with a human approval gate before any execution.
Given the operational risks of autonomous remediation, we designed Sentinel with multiple safety layers:
- The plan-then-approve workflow: Sentinel separates triage from execution. The triage phase is read-only: the agent analyzes the ticket and proposes a remediation plan. This plan appears in a web UI where the on-call engineer can review, edit, approve, or reject it. If the engineer approves the plan, a second cron job executes the plan, posting the outcome as a work log comment. Human review always occurs between analysis and action.
- Safety model: Sentinel’s ticketing credential can only post comments—it cannot create new tickets or modify ticket status, priority, or assignment. Plans are validated against a schema before storage, and the execution agent is limited to a defined set of allowed actions. This prevents malformed or malicious steps from being executed. All interactions—approvals, prompts, retrieved context, and tool calls—are logged in an append-only audit trail for full traceability. We roll out Sentinel in stages: manual (both crons paused), triage-only (plans generated automatically but executed manually), and fully autonomous (both crons active). A queue advances only after demonstrating consistent approval with zero execution rollbacks.
- Ongoing safety improvements: Three additional gates are in development before Sentinel’s autonomous execution capabilities expand. These include a typed allow-list of remediation-action schemas (not just denied commands), a quantitative graduation criterion for each queue (consecutive approved plans with zero post-execution reverts, measured per action type), and a schema-level reversibility requirement so a step cannot reach execution unless it is idempotent or includes an explicit typed inverse. Until these safety controls are in place, execute-path remediations are restricted to a curated set reviewed by a human before the action enters the Sentinel skill.
- Deep Dive Agent: While Sentinel’s automated RCA is usually sufficient to start a human investigation, on-call engineers sometimes need to perform a deeper analysis—explore a hypothesis, inspect specific metrics, or refine the RCA before finalizing. Sentinel includes a human-in-the-loop chat companion—a workflow built using Next.js and LangGraph that performs timestamp extraction, symptom classification, metric selection, iterative analysis with tool use, and synthesized explanation. It queries the same shared knowledge base so context stays consistent between autonomous and interactive modes.
As resolved tickets flow back through Atlas’s SOP extraction pipeline, the knowledge base grows continuously, providing increasingly rich context for subsequent ticket analysis. The pattern—read-only triage on a cron, plan-then-approve, append-only audit log—is reusable for anyone running OpenSearch (or any service) at a scale where on-call volume is the bottleneck.
Common design principles across all agents
Across these four agents, several design principles proved essential to building trustworthy autonomous systems:
- Harness-first, not review-first: Trust comes from a harness the agent tests against on every iteration—a benchmark comparison for Nitro, a live local integration stack for Ralph, a scoped credential and approval gate for Sentinel. A code review catches one bug once; a harness catches that class of bug on every future iteration. When agents generate faster than humans can review, machine-verifiable validation through harnesses becomes the only scalable approach to trust.
- Production data over synthetic examples: Synthetic benchmarks and specifications produce low-value results. Nitro profiles real ingestion traffic before proposing a fix; Ralph verifies changes against the same service stack that a customer’s traffic hits; Sentinel’s RCAs are grounded in a knowledge base built from resolved production tickets, not hand-curated runbooks. Each agent relies on a production data source, and without it the agent produces generic output.
- Human oversight at decision points: Sentinel approval, Ralph’s feature specification and QA review, and Nitro’s optimization targets are all human-controlled gates. Within each loop, execution can run without human involvement. Removing humans from the inner loop is what enables these pipelines to deliver more than incremental improvements.
- Feedback loop quality determines agent effectiveness: The feedback loop encodes engineering expertise, and the LLM draws on it. A stronger model cannot compensate for a weak loop.
What we’re still learning
These four agents are early experiments, and we have some open questions that will define future work areas. If you’re building similar systems, these may be relevant to you:
- Contributing Nitro’s fixes to OpenSearch core: While Nitro can discover optimizations such as the geopoint query improvement, contributing them back into OpenSearch core remains a manual process. The harness makes finding such optimizations quick, but a human still needs to decide whether a given fix is general enough to propose to the community, write the context that reviewers need, and guide the contribution through review.
- Atlas as a use case for hybrid search on OpenSearch: Building Atlas resulted in a real production workload combining nested vectors, BM25, and filter combinations on an OpenSearch cluster. We had to iterate on chunk size, vector dimensionality, and per-query-class weighting between lexical and vector scores. Cluster sizing also behaved differently from our initial estimates. We plan to share detailed findings in a follow-up post; if you’re building a similar retrieval layer on OpenSearch, the indexing patterns should be directly applicable.
- Knowledge-base quality control matters more than we initially expected: A single incorrectly resolved ticket can become a retrievable SOP that subsequent agents and humans then trust. Currently, we deduplicate new SOPs using embedding similarity against existing entries. We’re adding SOP versioning, mandatory human review before a new SOP is promoted to the active corpus, conflict detection when two SOPs contradict each other, and provenance tags that distinguish agent-generated content from human-authored content.
- Validating Ralph’s validator: Ralph’s validator is an LLM that judges whether another LLM’s output meets a specification. To trust this arrangement, we need to measure how often the validator agrees with human reviewers, how often it incorrectly promotes failing work, and whether its error profile changes when we swap model families. We’re collecting these metrics now. Without them, the trust argument reduces to assumption rather than evidence.
- Expanding Sentinel’s execution scope: Sentinel’s autonomous execution is currently restricted to a small, human-reviewed set of actions. Before we expand it, we’re building three additional controls: a typed allow-list of remediation action schemas, a graduation threshold per queue (a specified number of consecutive approved plans with zero post-execution reverts before the queue can run autonomously), and a reversibility requirement at the schema level so that no action can execute unless it is idempotent or includes a defined rollback step.
- The patterns appear portable but we haven’t yet seen them stress-tested outside our deployment: We designed these agents around four general principles: harness-first verification, grounding in production data, separating planning from execution with a human approval gate, and placing humans at decision boundaries rather than inside execution loops. These principles are not specific to our infrastructure, but we have only tested them in our own environment.
Conclusion
Automation is effective only when it is paired with verification. Trust must be a system property—a set of invariants that the system enforces—not a human judgment that does not scale beyond a few hundred pull requests per week.
With time, agents can handle more operational work, but they cannot define the vision, design the architecture, or decide what to build. This is the engineer’s job.
If you’re running similar experiments, we’d love to hear from you. Please share your experience on the OpenSearch forum.





