

Hybrid queries combine the precision of traditional lexical search with the semantic power of vector search. In OpenSearch 3.1, we delivered significant latency reductions for hybrid queries by redesigning how scores are collected across subqueries. This improvement builds on the concurrent segment search capabilities already present in OpenSearch and introduces a low-level, efficient bulk scorer tailored for hybrid workloads.
Background: Bottleneck in hybrid scoring
Prior to OpenSearch 3.1, score collection worked as follows:
- Each query branch (for example, a
matchclause and aneuralclause) scored documents separately. - Score collection was performed in a serialized manner, even though the OpenSearch core already supported concurrent segment-level search.
- Subquery scorers introduced additional overhead because of redundant control logic and per-document operations.
The new score collection method enhances performance by using optimized parallel execution and efficient score aggregation across query branches.
Optimization: Smarter score collection and batch processing
In OpenSearch 3.1, we introduced a custom bulk scorer for hybrid queries. This scorer is designed to work with OpenSearch’s concurrent segment search, in which different segments of an index are searched in parallel by design. Our focus was on minimizing overhead within each segment’s execution.
To achieve this goal, we introduced the following key improvements:
- Single leaf collector per segment: Subquery scorers now share one leaf collector instance, eliminating redundant score collection infrastructure and improving cache locality.
- Small batch processing: The scorer processes documents in small, fixed-size windows (for example, 4,096 documents at a time), allowing strict loops with reduced memory overhead.
- Bit set merging: Document IDs across subquery scorers are tracked using efficient bit sets, which reduce memory allocations and simplify score merging.
- Low-level control flow: We replaced priority queues and dynamic collections with arrays and preallocated structures to minimize garbage collection pressure and avoid runtime branching.
The following diagram shows the high-level architecture of the hybrid query execution path before and after introducing the custom bulk scorer.
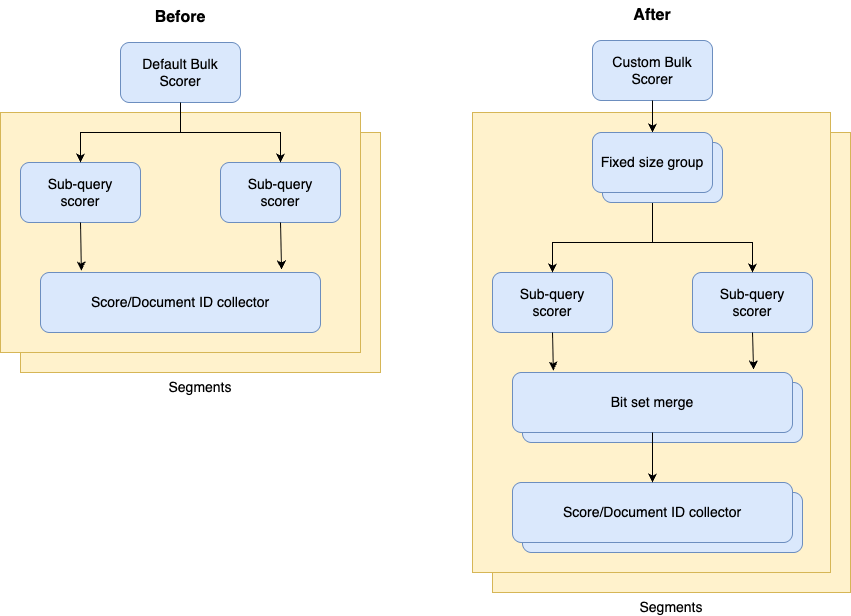
This design allows hybrid queries to use the natural parallelism of OpenSearch’s indexing structure (segments) without introducing thread-level concurrency within scorers, which often adds more overhead than benefit.
Implementation details
Our custom bulk scorer operates on the principle of coordinated iteration across multiple subquery scorers. Here’s how it works:
- Document ID discovery: For each segment, we first identify candidate document IDs that match at least one subquery.
- Batch processing: Rather than processing documents one at a time, we collect them in fixed-size batches. We chose a batch size of 2^12 = 4096, which provides an optimal balance between frequency of score collection and memory usage.
- Coordinated scoring: For each batch, we score all matching documents across all subqueries in a tightly optimized loop, maintaining better cache locality.
- Score combination: Within the same iteration, scores from different subqueries are combined according to the hybrid query’s weight settings.
This approach minimizes the overhead of document iteration while maximizing the benefits of OpenSearch’s segment-level concurrency model.
Real-world results: Up to 3.5x throughput and 80% latency reductions
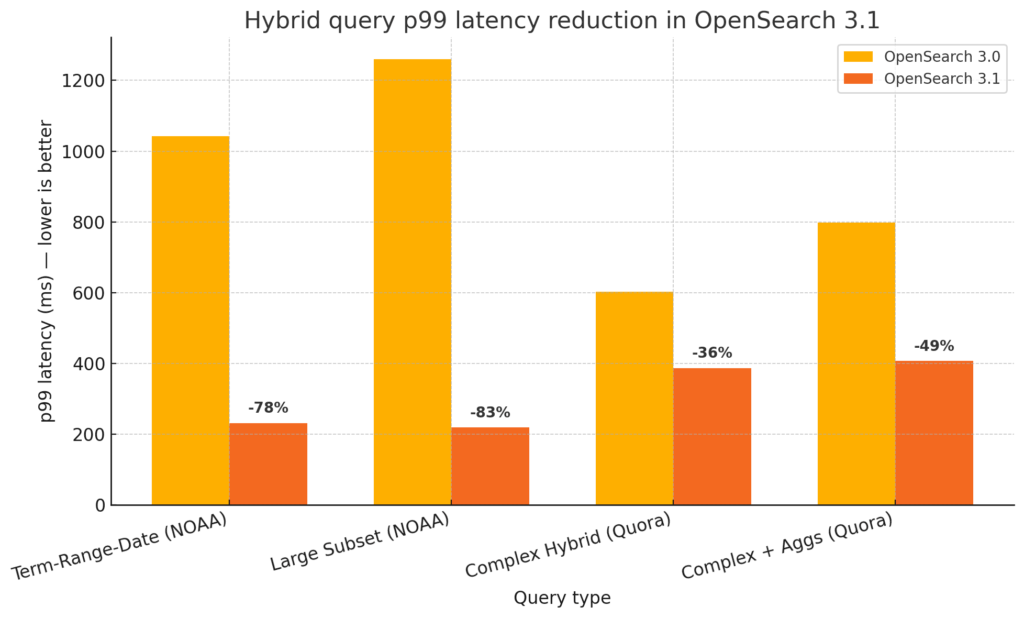
We evaluated the improved hybrid scorer against OpenSearch 3.0 using diverse workloads on multiple Amazon Elastic Compute Cloud (Amazon EC2) instance types. The following table shows improvements in response latency time percentiles.
| Dataset | Query type | Metric | OpenSearch 3.1 (ms) | OpenSearch 3.0 (ms) | Latency reduction |
|---|---|---|---|---|---|
| NOAA (text only) | 1 keyword query, 1M matches | p50 | 117 | 178 | 34% |
| p90 | 128 | 193 | 34% | ||
| p99 | 137 | 208 | 34% | ||
| 1 keyword query, 10M matches | p50 | 183 | 703 | 74% | |
| p90 | 205 | 958 | 79% | ||
| p99 | 220 | 1260 | 83% | ||
| 3 keyword queries, 15M matches | p50 | 336 | 1759 | 81% | |
| p90 | 382 | 2518 | 85% | ||
| p99 | 523 | 3243 | 84% | ||
| Quora (hybrid) | Neural + lexical | p50 | 199 | 256 | 22% |
| p90 | 240 | 332 | 28% | ||
| p99 | 286 | 414 | 31% | ||
| Neural + 2 lexical | p50 | 248 | 337 | 27% | |
| p90 | 316 | 481 | 34% | ||
| p99 | 387 | 603 | 36% | ||
| Neural + 2 lexical + aggregations | p50 | 262 | 426 | 39% | |
| p90 | 339 | 631 | 46% | ||
| p99 | 407 | 799 | 49% |
These gains were consistent under both benchmark and steady-load conditions (25 queries per second), with even greater performance improvements when concurrent segment search was enabled.
Tail latencies (p99) improved by up to 49% even on large instances, making hybrid search more reliable under high load.
The following graph presents the improvements in response times for different datasets and query types.
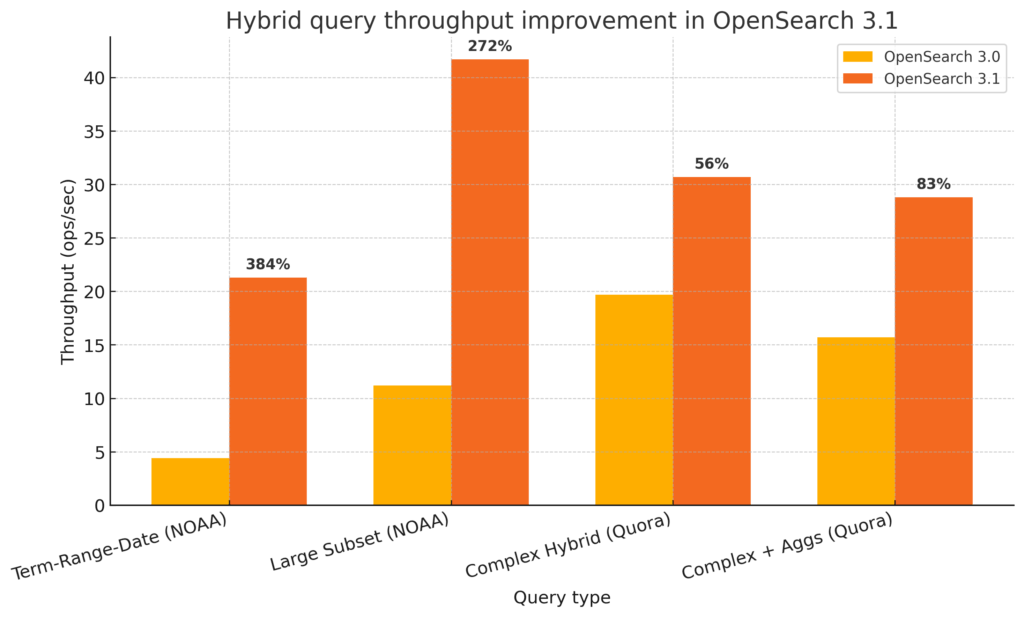
The new bulk scorer positively impacts system throughput. The following table shows improvements in search throughput depending on the type of machine used as a data node.
| Dataset | Instance type | Query complexity | Throughput gain |
|---|---|---|---|
| Combined vector and text data | R5.xlarge | Neural + 2 lexical + aggregations | 83% |
| R5.xlarge | Neural + 2 lexical | 56% | |
| C5.2xlarge | Neural + 2 lexical + aggregations | 18% | |
| R5.4xlarge | Hybrid query overall | 19–27% | |
| Only text data | C5.2xlarge | 1 keyword query, 10M matches | 115% |
| C5.2xlarge | 3 keyword queries, 15M matches | 254% | |
| R5.xlarge | 1 keyword query, 10M matches | 272% | |
| R5.xlarge | 3 keyword queries, 15M matches | 384% | |
| R5.4xlarge | 1 keyword query, 10M matches | 63% | |
| R5.4xlarge | 3 keyword queries, 15M matches | 151% |
The following graph illustrates these throughput improvements.
Scaling behavior: Better utilization and more predictable performance
The improved scorer not only speeds up individual queries but also scales more gracefully with increased hardware. On larger instances, such as R5.4xlarge, we observed the following performance improvements:
- Throughput for hybrid queries with multiple keyword-based subqueries increased by 234% in OpenSearch 3.1 compared to 3.0 when concurrent segment search was enabled.
- Hybrid and complex hybrid queries showed up to a 27% improvement in throughput.
- p99 latency was reduced by over 60% for most complex cases.
These results suggest that the custom scorer improves core efficiency rather than simply consuming more hardware.
How we ran benchmarks
We used diverse datasets and related OpenSearch Benchmark workloads to evaluate the performance of the new solution with the custom bulk scorer:
- AI search workload: Based on the Quora dataset, includes semantic and hybrid queries with both text and vector data.
- Semantic search workload: Based on the NOAA dataset, includes hybrid queries over lexical and numeric fields.
We set up the OpenSearch cluster using the OpenSearch Cluster CDK with the following parameters:
- 3 data nodes using various EC2 instance types (C5.2xlarge, R5.xlarge, R5.4xlarge) running x64 architecture.
- 3 manager nodes (c5.xlarge EC2 instances).
- All cluster nodes were deployed in a single AWS Availability Zone to minimize network latency effects.
We took several steps to ensure consistent and reliable benchmark results:
- All index segments were force-merged before running the tests to eliminate background merge operations.
- We verified that no other concurrent workloads were running on the cluster during testing.
We ingested documents into an index configured as follows:
number_of_shards: 6number_of_segments: 8 (per shard; total = 48)
Looking ahead
These improvements lay the groundwork for further innovation in hybrid search, including:
- Adaptive batch sizing based on query complexity and segment size.
- Collecting scores in parallel within an OpenSearch segment for each subquery.
If you use hybrid queries in production or are building search features that blend lexical and vector semantics, upgrading to OpenSearch 3.1 is a great way to benefit from faster response times and more efficient resource usage.
References
- GitHub issue with a high-level proposal for improving response times in hybrid queries
- RFC with the design for the custom bulk scorer
- Pull request that introduces the custom bulk scorer
- OpenSearch Benchmark semantic search workload
- OpenSearch Benchmark AI search workload
- OpenSearch Cluster CDK
- Previous blog post: Boosting hybrid query performance in OpenSearch 2.15


