

OpenSearch 3.2 has been released, with a host of features to enhance and broaden search, observability, and generative AI use cases.
This release focuses on extending new innovations introduced in the 3.x line, including:
- Expanded GPU support
- Major improvements to the approximation framework
- GA of Protobuf in OpenSearch
Many of the enhancements are focused on helping to scale workloads with more efficient indexing and query capabilities. Read on for the highlights!
Search
Search has undergone an array of changes focused on performance, scalability, and expansion of functionality.
Major improvements to the approximation framework
OpenSearch 3.2 extends the approximation framework with enhancements in two different areas.
First, search_after queries are now supported in 3.2, addressing a significant performance gap where these queries previously fell back to default Lucene traversal. The enhancement converts 'search_after' parameters into proper range query bounds–using 'search_after' as the lower bound for ASC sorts and the upper bound for DESC sorts–enabling continued use of the ApproximatePointRange query’s optimized BKD traversal instead of defaulting to Lucene. This optimization significantly enhances pagination performance for time-series and numeric workloads. In benchmark testing, the Big5 dataset shows p90 latency reductions from 185 ms to 8 ms for both ASC and DESC timestamp sorts with 'search_after'. The 'http_logs' dataset achieves similar gains, with DESC sort latency dropping from 397 ms to 7 ms. This will improve responsiveness of paginated search results, real-time dashboards, and applications requiring deep pagination through large time-series or numeric datasets.
Second, OpenSearch 3.2 expands approximate query capabilities to all numeric field types instead of only LONG field types. This enhancement includes HALF_FLOAT, FLOAT, DOUBLE, INTEGER, BYTE, SHORT and UNSIGNED_LONG fields. Benchmark testing on http_logs and nyc_taxis datasets demonstrates substantial performance improvements, with up to 80% reduction in p90 latency. This optimization is most beneficial for analytics workloads, time-series data analysis and applications requiring fast numeric filtering/sorting operations across diverse numeric field types.
Try out GRPC/Protobuf for a more performant API
In 3.2, the gRPC transport layer has reached general availability (GA), delivering high-performance support for bulk document ingestion and k-NN query capabilities. This marks a significant step forward in performance, efficiency, and extensibility for OpenSearch users. Rather than using native REST APIs, the gRPC module communicates using Protocol Buffers (Protobufs)–a compact, structured, and strongly typed binary format generated automatically from the OpenSearch API specification. This format reduces payload size and improves overall performance, particularly for high-throughput operations like bulk ingestion and primitive types of data such as vector search using k-NN queries. Additional highlights of the GA release include expanded search API functionality and encryption in transit. The gRPC transport layer opens up exciting possibilities for supporting performance-critical workloads and building efficient client integrations in the future. A special thanks to Uber, a premier member of the OpenSearch Software Foundation, for their leadership and collaboration in bringing this feature to fruition.
Improve query performance with new skip_list functionality
The skip_list parameter, introduced in OpenSearch in 3.2, is particularly beneficial for fields that are frequently used in range queries or aggregations. Using skip_list improves performance by allowing the query engine to skip over document ranges that don’t match the query criteria. See the field types documentation for more information about using this parameter.
New functionality for search using star-tree
Search using star-tree now supports aggregations with queries on the IP field as well. Also, basic metrics related to queries resolved using star-tree are now included as part of index/node/shard statistics. View options include the total number of queries resolved using star-tree, current running queries using star-tree, and the total time spent resolving queries using star-tree. See this blog post for an introduction to this functionality.
Improve resource distribution with streaming aggregation
Experimental in 3.2 and built on streaming transport, streaming aggregation functionality has been introduced. This enables segment-level partial aggregation responses to be streamed back to the coordinator node instead of returning a single response per shard. This approach improves resource distribution by making the coordinator the single point to scale. You can perform the `term` aggregation search with the stream=true query parameter for opt-in usage. This architectural change moves the memory-intensive reduce logic from data nodes to the coordinator, allowing better scalability for high-cardinality aggregations.
Evaluate quality with the search relevance workbench
The search relevance workbench is GA in version 3.2. This helps you improve and fine-tune your search relevance through experimentation by investigating and diagnosing problems with your search queries. To facilitate your investigation into the details of search evaluation and global hybrid optimizations, dashboards were created with visualizations of individual query quality. The search relevance introductory blog post can help you get started with this new tool.
Vector database and generative AI
Several performance- and scale-related improvements are introduced in OpenSearch 3.2, including extending GPU support to more vector types, vector search quality improvements, and updates to the Neural Search plugin.
Use new vector types with expanded GPU support
GPU indexing in OpenSearch now supports FP16, byte and binary vector types in addition to the previous FP32 support. These additional representations use less memory than FP32 vectors, which allows for more storage in memory and fewer GPU and CPU data transfers. The end result is more efficient and scalable use of resources and potential for a broader range of applications to be built using GPU-accelerated indexing.
Boost recall for on-disk vector search
OpenSearch 3.2 introduces two powerful techniques for boosting search quality in binary-quantized indexes. Asymmetric Distance Computation (ADC) maintains full-precision query vectors while comparing against compressed document vectors, preserving critical search information without memory overhead. Random rotation (RR) redistributes variance across vector dimensions, preventing information loss during the 32x compression process. ADC supports 1-bit quantization, while RR works with 1, 2, and 4-bit configurations. Together, these opt-in features can increase recall by up to 80% on challenging datasets like SIFT, with moderate latency trade-offs, making binary quantization viable for precision-critical applications.
Optimize semantic search for your specific data, performance, and relevance needs
In OpenSearch 3.2, the Neural Search plugin’s semantic field gains new configurability to better support advanced semantic search scenarios. Users can now fine-tune dense embedding field parameters (for example, engine, mode, compression_level, method), customize text chunking with multiple algorithms/settings, and configure sparse embedding generation with prune strategies and ratios. A new batch size option improves indexing throughput, and an embedding reuse setting reduces redundant processing when content is unchanged. These enhancements make semantic search more flexible, efficient, and adaptable, creating optimization options for your specific data, performance, and relevance needs.
Plan-execute-reflect agents are GA
Plan-execute-reflect agents, which can autonomously solve complex tasks by planning and reflecting, are now generally available in 3.2 and have been enhanced with prompts to improve performance, expose parameters to control message history, and provide users the ability to include date and time in prompts. Available with the ML Commons plugin, plan-execute-reflect agents break down intricate questions into manageable steps, select suitable tools for execution, and iteratively improve their strategies through reflection.
Transform natural language questions into OpenSearch DSL using agentic search
Agentic search, experimental in version 3.2, is a new query type proposed in OpenSearch that triggers an agent-driven workflow for query understanding, planning and execution. Instead of hand-crafting DSL, you supply a natural language question and an agent id. The agent then executes a query planning tool to produce OpenSearch DSL, run it via agentic query clause and return the search results.
Create AI agents that learn from past interactions
Experimental in OpenSearch 3.2, agentic memory enables AI agents to maintain persistent memory beyond simple conversation histories. This capability extracts and stores key facts from conversations, allowing agents to learn from past interactions and provide more personalized assistance across sessions. Developers can build AI agents that leverage semantic search to recall relevant context from previous interactions which increase the quality of future sessions.
Observability, log analytics, and security analytics
OpenSearch 3.2 brings improvements to query performance, new analysis avenues for the Trace Analytics plugin, and more.
Improve your trace analytics with new OpenTelemetry compatibility and service map controls
The Trace Analytics plugin now helps users analyze traces compliant with OpenTelemetry (OTel), from ingestion in Data Prepper 2.11 to visualizations of trace analytics in OpenSearch 3.2. Configure your OTel source with output_format: otel and send spans to OpenSearch to retain standard OTel fields and metadata, enabling smoother integration with OpenTelemetry tooling and simpler pipelines. Users can now also configure the maximum nodes and edges displayed in the service map, providing more control over visual complexity in large environments.
Improve query performance and usability with PPL Calcite updates
OpenSearch 3.2 delivers major performance and query flexibility improvements to Piped Processing Language (PPL). A new Calcite-row-expression-based script engine enables aggregation functions, filter function pushdown, span pushdown, relevance query pushdown, sort-merge-join pushdown, and IP comparison pushdown. New functions have been added for argument coercion, improved date handling, and QUERY_SIZE_LIMIT enforcement. These updates collectively boost performance, correctness, and usability for complex queries across OpenSearch data sources, as shown in the following image.
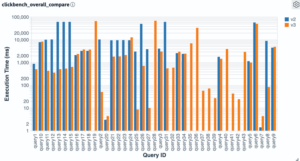
Image: PPL execution time improvements: 2.x vs. 3.x
OpenSearch Prometheus exporter
The Prometheus exporter plugin has been transitioned into the OpenSearch Project and is being released in parallel with OpenSearch 3.2. This plugin is not bundled with the core build and must be installed separately. However, its packaging and release cadence have been updated to match the OpenSearch Project’s release schedule. Existing Prometheus scraping workflows remain compatible; metrics continue to be exposed at /_prometheus/metrics. A special thanks to Aiven for their stewardship and help with the transition.
Getting started
You can find the latest version of OpenSearch on our downloads page or check out the visualization tools on OpenSearch Playground. For more information, visit the release notes, documentation release notes, and updated documentation. If you’re exploring a migration to OpenSearch from another software provider, we offer tools and documentation designed to assist this process, available here.
Feel free to visit our community forum to share your valuable feedback on this release and connect with other OpenSearch users on our Slack instance.
