

In the era of large-scale machine learning (ML) applications, one of the most significant challenges is efficiently generating vector embeddings during data ingestion into OpenSearch. The process of transforming millions or even billions of documents into high-dimensional vectors using ML models has become a critical bottleneck in building effective neural search applications. While traditional real-time APIs offer a straightforward approach to vector generation, they present substantial limitations when dealing with large-scale ingestion workflows.
Real-time vector generation approaches often incur higher costs per inference and are constrained by lower rate limits, creating significant bottlenecks during the ingestion phase. As you attempt to vectorize massive document collections, these limitations result in extended ingestion times and increased operational costs. The challenge is further compounded by the complexity of orchestrating the entire pipeline—from initial document processing to vector generation and final indexing into OpenSearch.
To address these vector generation challenges and streamline the ingestion workflow, we’re excited to introduce a powerful integration between OpenSearch Ingestion and ML Commons. This integration enables seamless batch ML inference processing in offline mode, allowing you to generate vectors for large-scale document collections. By optimizing the vector generation phase of the ingest pipeline, we’re making it easier than ever to build and scale neural search applications efficiently.
How does ML Commons integrate with OpenSearch Ingestion?
We have added a new ml_inference processor to OpenSearch Ingestion in order to integrate with ML Commons for creating offline batch inference jobs. Since OpenSearch 2.17, ML Commons has provided the Batch Predict API, which performs inference on large datasets in offline, asynchronous mode using models deployed on external model servers such as Amazon Bedrock, Amazon SageMaker, Cohere, and OpenAI. Integrating ML Commons with OpenSearch Ingestion incorporates the Batch Predict API into OpenSearch Ingestion, enabling OpenSearch Ingestion pipelines to run batch inference jobs during ingestion. The following diagram shows an OpenSearch Ingestion pipeline that orchestrates multiple components to perform this process end to end.
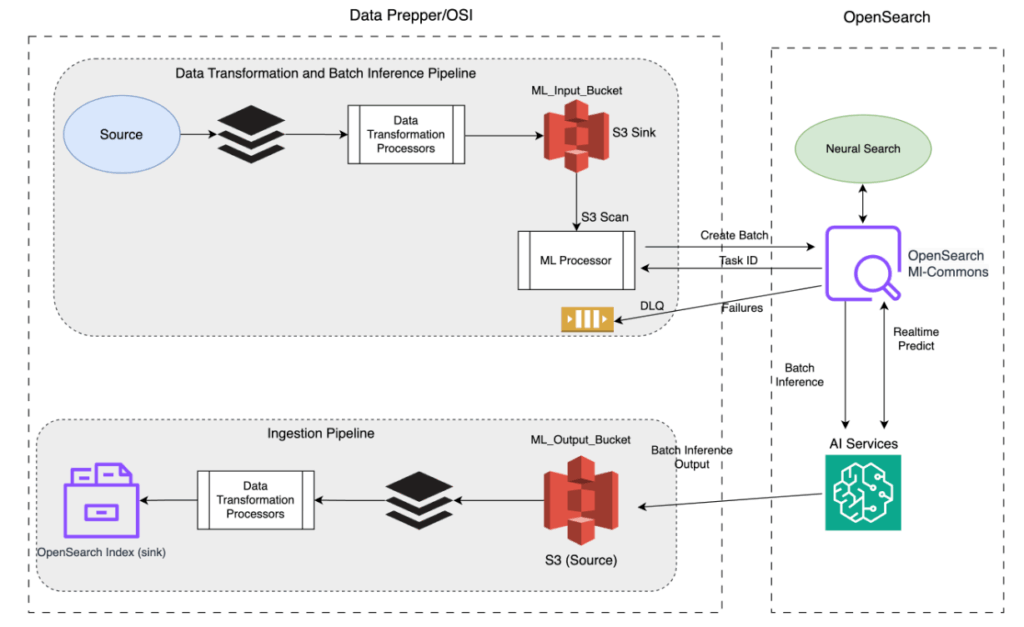
In this solution, an s3 source monitors events for any new file generated in the inference pipeline. It then sends the new file name as an input to ML Commons for batch inference. The architecture contains three subpipelines, each performing distinct tasks in the data flow:
-
Pipeline 1 (prepares and transforms data)
- Source: Data is ingested from an external source provided by you and supported by OpenSearch Data Prepper.
- Data transformation processors: The raw data is processed and transformed, preparing it in the correct format for batch inference on the remote AI server.
s3(sink): The transformed data is then stored in an Amazon Simple Storage Service (Amazon S3) bucket as the input to the AI server, acting as an intermediary storage layer.
-
Pipeline 2 (triggers ML batch inference)
- Source: The S3 scan monitors events for any new S3 file generated by Pipeline 1.
ml_inferenceprocessor: Calls the ML Commons Batch Predict API to create batch jobs.- Task ID: Each batch job is associated with a task ID for tracking and management.
- ML Commons: Hosts the model for real-time neural search, manages connectors to remote AI servers, and serves the APIs for batch inference and job management.
- AI services: Perform batch inference on the data, producing predictions or insights. ML Commons interacts with these AI services (such as Amazon SageMaker or Amazon Bedrock). The results are saved asynchronously to a separate S3 file.
-
Pipeline 3 (performs bulk ingestion)
s3(source): Stores the results of the batch jobs. S3 is the source of this pipeline.- Data transformation processors: Further process and transform the batch inference output before ingestion to ensure that the data is mapped correctly in the OpenSearch index.
- OpenSearch index (sink): Indexes the processed results into OpenSearch for storage, search, and further analysis.
How to use the ml_inference processor
The current OpenSearch Ingestion implementation features a specialized integration between the S3 scan source and ml_inference processor for batch processing. In this initial release, the S3 scan operates in metadata-only mode, efficiently collecting S3 file information without reading the actual file contents. The ml_inference processor then uses the S3 file URLs to coordinate with ML Commons for batch processing. This design optimizes the batch inference workflow by minimizing unnecessary data transfer during the scanning phase.
The ml_inference processor can be defined with the following parameters:
processor:
- ml_inference:
# The endpoint URL of your OpenSearch domain
host: "https://search-xunzh-test-offlinebatch-kitdj4jwpiencfmxpklyvwarwa.us-west-2.es.amazonaws.com“
# Type of inference operation:
# - batch_predict: for batch processing
# - predict: for real-time inference
action_type: "batch_predict"
# Remote ML model service provider (bedrock or sagemaker)
service_name: "bedrock"
# Unique identifier for the ML model
model_id: "EzNlGZcBo9m_Jklj4T0j"
# S3 path where batch inference results will be stored
output_path: "s3://xunzh-offlinebatch/bedrock-multisource/output-multisource/"
# AWS configuration settings
aws:
# AWS Region where the Lambda function is deployed
region: "us-west-2"
# IAM role ARN for Lambda function execution
sts_role_arn: "arn:aws:iam::388303208821:role/Admin"
# Conditional expression that determines when to trigger the processor
# In this case, only process when bucket matches "xunzh-offlinebatch"
ml_when: /bucket == "xunzh-offlinebatch"
Ingestion performance improvements using the ml_inference processor
The OpenSearch Ingestion ml_inference processor significantly enhances data ingestion performance for ML-enabled search. It’s ideally suited for use cases requiring ML-model-generated data, including semantic search, multimodal search, document enrichment, and query understanding. In semantic search, the processor can accelerate the creation and ingestion of large-volume, high-dimensional vectors by an order of magnitude.
The processor’s offline batch inference capability offers distinct advantages over real-time model invocation. While real-time processing requires a live model server with capacity limitations, batch inference dynamically scales compute resources on demand and processes data in parallel. For example, when the OpenSearch Ingestion pipeline receives 1 billion source data requests, it creates 100 S3 files for ML batch inference input. The ml_inference processor then initiates an Amazon SageMaker batch job using 100 ml.m4.xlarge Amazon Elastic Compute Cloud (Amazon EC2) instances, completing the vectorization of 1 billion requests in 14 hours—a task that would be virtually impossible to accomplish in real-time mode. This process is illustrated in the following diagram.
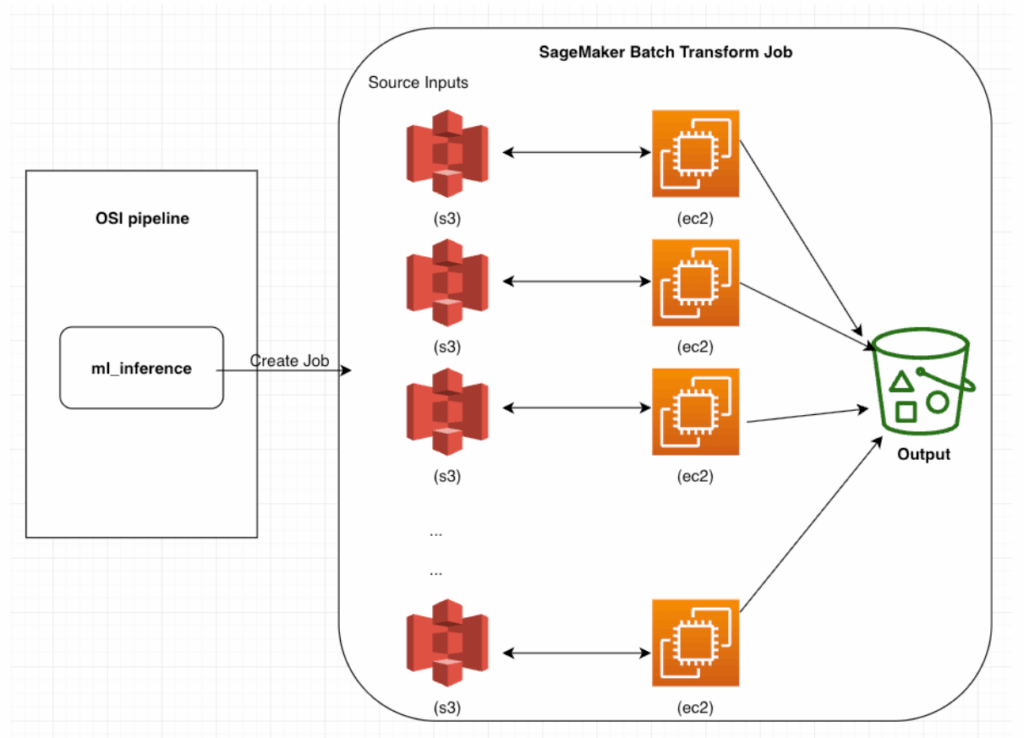
This solution offers excellent scalability by allowing linear reduction in processing time through the addition of more workers. For example, while the initial setup with 100 ml.m4.xlarge EC2 instances processed 1 billion document requests in 14 hours, doubling the worker count to 200 instances could potentially reduce the processing time to 7 hours. This linear scaling capability demonstrates the solution’s flexibility in meeting various performance requirements by simply adjusting the worker count and instance type, enabling you to optimize your processing time based on your specific needs and urgency.
Additionally, most AI servers offer a batch inference API at about 50% lower cost, enabling similar performance at half the price.
Getting started
Let’s walk through a practical example of using the OpenSearch Ingestion ml_inference processor to ingest 1 billion data requests for semantic search using a text embedding model.
Step 1: Create connectors and register models in OpenSearch
Use this blueprint to create a connector and model in Amazon SageMaker.
Create a Deep Java Library (DJL) ML model in Amazon SageMaker for batch transform:
POST https://api.sagemaker.us-east-1.amazonaws.com/CreateModel
{
"ExecutionRoleArn": "arn:aws:iam::419213735998:role/aos_ml_invoke_sagemaker",
"ModelName": "DJL-Text-Embedding-Model-imageforjsonlines",
"PrimaryContainer": {
"Environment": {
"SERVING_LOAD_MODELS" : "djl://ai.djl.huggingface.pytorch/sentence-transformers/all-MiniLM-L6-v2"
},
"Image": "763104351884.dkr.ecr.us-east-1.amazonaws.com/djl-inference:0.29.0-cpu-full"
}
}
Create a connector with batch_predict as the new action type in the actions field:
POST /_plugins/_ml/connectors/_create
{
"name": "DJL Sagemaker Connector: all-MiniLM-L6-v2",
"version": "1",
"description": "The connector to sagemaker embedding model all-MiniLM-L6-v2",
"protocol": "aws_sigv4",
"credential": {
"access_key": "xxx",
"secret_key": "xxx",
"session_token": "xxx"
},
"parameters": {
"region": "us-east-1",
"service_name": "sagemaker",
"DataProcessing": {
"InputFilter": "$.text",
"JoinSource": "Input",
"OutputFilter": "$"
},
"MaxConcurrentTransforms": 100,
"ModelName": "DJL-Text-Embedding-Model-imageforjsonlines",
"TransformInput": {
"ContentType": "application/json",
"DataSource": {
"S3DataSource": {
"S3DataType": "S3Prefix",
"S3Uri": "s3://offlinebatch/msmarcotests/"
}
},
"SplitType": "Line"
},
"TransformJobName": "djl-batch-transform-1-billion",
"TransformOutput": {
"AssembleWith": "Line",
"Accept": "application/json",
"S3OutputPath": "s3://offlinebatch/msmarcotestsoutputs/"
},
"TransformResources": {
"InstanceCount": 100,
"InstanceType": "ml.m4.xlarge"
},
"BatchStrategy": "SingleRecord"
},
"actions": [
{
"action_type": "predict",
"method": "POST",
"headers": {
"content-type": "application/json"
},
"url": "https://runtime.sagemaker.us-east-1.amazonaws.com/endpoints/OpenSearch-sagemaker-060124023703/invocations",
"request_body": "${parameters.input}",
"pre_process_function": "connector.pre_process.default.embedding",
"post_process_function": "connector.post_process.default.embedding"
},
{
"action_type": "batch_predict",
"method": "POST",
"headers": {
"content-type": "application/json"
},
"url": "https://api.sagemaker.us-east-1.amazonaws.com/CreateTransformJob",
"request_body": """{ "BatchStrategy": "${parameters.BatchStrategy}", "ModelName": "${parameters.ModelName}", "DataProcessing" : ${parameters.DataProcessing}, "MaxConcurrentTransforms": ${parameters.MaxConcurrentTransforms}, "TransformInput": ${parameters.TransformInput}, "TransformJobName" : "${parameters.TransformJobName}", "TransformOutput" : ${parameters.TransformOutput}, "TransformResources" : ${parameters.TransformResources}}"""
},
{
"action_type": "batch_predict_status",
"method": "GET",
"headers": {
"content-type": "application/json"
},
"url": "https://api.sagemaker.us-east-1.amazonaws.com/DescribeTransformJob",
"request_body": """{ "TransformJobName" : "${parameters.TransformJobName}"}"""
},
{
"action_type": "cancel_batch_predict",
"method": "POST",
"headers": {
"content-type": "application/json"
},
"url": "https://api.sagemaker.us-east-1.amazonaws.com/StopTransformJob",
"request_body": """{ "TransformJobName" : "${parameters.TransformJobName}"}"""
}
]
}
Use the returned connector ID to register the Amazon SageMaker model:
POST /_plugins/_ml/models/_register
{
"name": "SageMaker model for batch",
"function_name": "remote",
"description": "test model",
"connector_id": "a3Y8O5IBOcD45O-eoq1g"
}
Invoke the model with the batch_predict action type:
POST /_plugins/_ml/models/teHr3JABBiEvs-eod7sn/_batch_predict
{
"parameters": {
"TransformJobName": "SM-offline-batch-transform"
}
}
The response contains a task ID for the batch job:
{
"task_id": "oSWbv5EB_tT1A82ZnO8k",
"status": "CREATED"
}
To check the batch job status, use the Get Task API and provide the task ID:
GET /_plugins/_ml/tasks/oSWbv5EB_tT1A82ZnO8k
The response contains the task status:
{
"model_id": "nyWbv5EB_tT1A82ZCu-e",
"task_type": "BATCH_PREDICTION",
"function_name": "REMOTE",
"state": "RUNNING",
"input_type": "REMOTE",
"worker_node": [
"WDZnIMcbTrGtnR4Lq9jPDw"
],
"create_time": 1725496527958,
"last_update_time": 1725496527958,
"is_async": false,
"remote_job": {
"TransformResources": {
"InstanceCount": 1,
"InstanceType": "ml.c5.xlarge"
},
"ModelName": "DJL-Text-Embedding-Model-imageforjsonlines",
"TransformOutput": {
"Accept": "application/json",
"AssembleWith": "Line",
"KmsKeyId": "",
"S3OutputPath": "s3://offlinebatch/output"
},
"CreationTime": 1725496531.935,
"TransformInput": {
"CompressionType": "None",
"ContentType": "application/json",
"DataSource": {
"S3DataSource": {
"S3DataType": "S3Prefix",
"S3Uri": "s3://offlinebatch/sagemaker_djl_batch_input.json"
}
},
"SplitType": "Line"
},
"TransformJobArn": "arn:aws:sagemaker:us-east-1:802041417063:transform-job/SM-offline-batch-transform15",
"TransformJobStatus": "InProgress",
"BatchStrategy": "SingleRecord",
"TransformJobName": "SM-offline-batch-transform15",
"DataProcessing": {
"InputFilter": "$.content",
"JoinSource": "Input",
"OutputFilter": "$"
}
}
}
Step 1 (alternative): Use AWS CloudFormation
You can use AWS CloudFormation to automatically create all required Amazon SageMaker connectors and models for ML inference. This approach simplifies setup by using a preconfigured template available in the Amazon OpenSearch Service console. For more information, see Using AWS CloudFormation to set up remote inference for semantic search.
To deploy a CloudFormation stack that creates all the required Amazon SageMaker connectors and models, use the following steps:
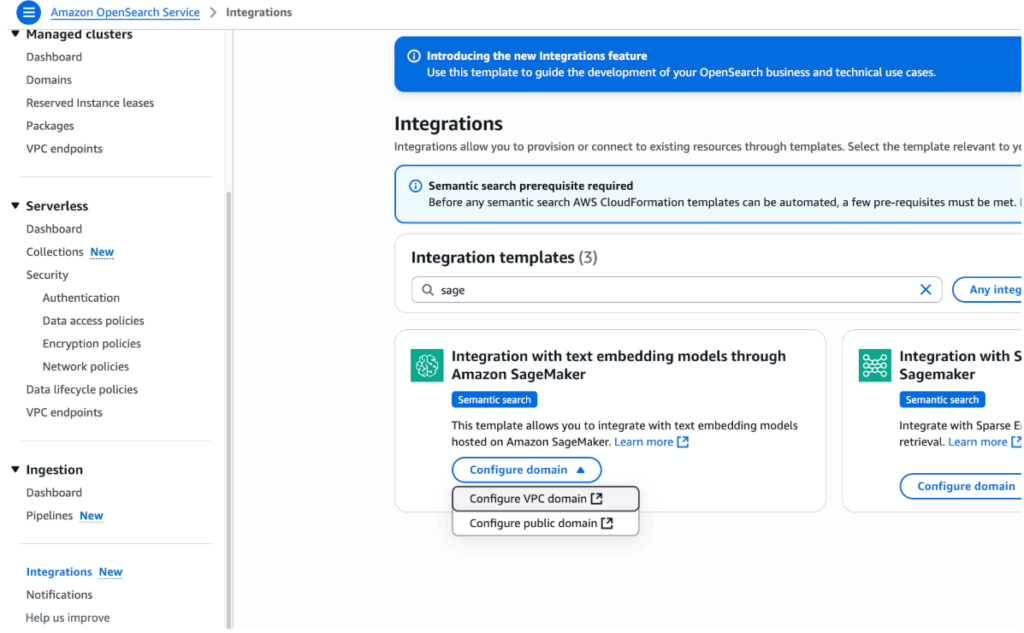
- In the OpenSearch Service console, go to Integrations and search for
SageMaker. - Select Integration with text embedding models through Amazon SageMaker.
- Choose Configure domain, then select Configure VPC domain or Configure public domain as appropriate, as shown in the following image.
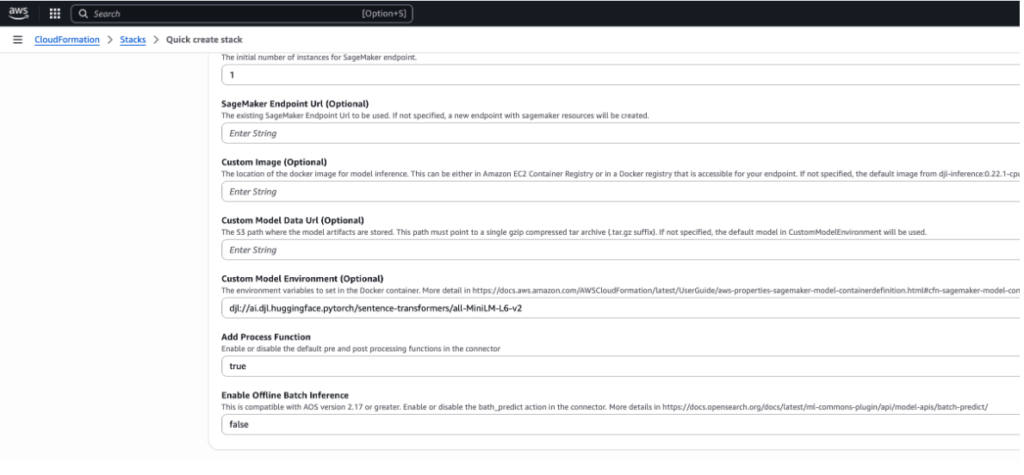
4. When starting the stack deployment, set the Enable Offline Batch Inference dropdown list to true to provision resources for offline batch processing, as shown in the following image.
5. After the CloudFormation stack is created, open the Outputs tab in the CloudFormation console to find the connector_id and model_id. You will need these values for later pipeline configuration steps.
Step 2: Create an OpenSearch Ingestion pipeline
Create your OpenSearch Ingestion pipeline using the following code in the configuration editor:
version: '2'
extension:
osis_configuration_metadata:
builder_type: visual
sagemaker-batch-job-pipeline:
source:
s3:
acknowledgments: true
delete_s3_objects_on_read: false
scan:
buckets:
- bucket:
name: xunzh-offlinebatch
data_selection: metadata_only
filter:
include_prefix:
- sagemaker/sagemaker_djl_batch_input
exclude_suffix:
- .manifest
- bucket:
name: xunzh-offlinebatch
data_selection: data_only
filter:
include_prefix:
- sagemaker/output/
scheduling:
interval: PT6M
aws:
region: us-west-2
default_bucket_owner: 388303208821
codec:
ndjson:
include_empty_objects: false
compression: none
workers: '1'
processor:
- ml_inference:
host: "https://search-xunzh-test-offlinebatch-kitdj4jwpiencfmxpklyvwarwa.us-west-2.es.amazonaws.com"
aws_sigv4: true
action_type: "batch_predict"
service_name: "sagemaker"
model_id: "9t4AbpYBQb1BoSOe8x8N"
output_path: "s3://xunzh-offlinebatch/sagemaker/output"
aws:
region: "us-west-2"
sts_role_arn: "arn:aws:iam::388303208821:role/Admin"
ml_when: /bucket == "xunzh-offlinebatch"
- copy_values:
entries:
- from_key: /content/0
to_key: chapter
- from_key: /content/1
to_key: title
- from_key: /SageMakerOutput/0
to_key: chapter_embedding
- from_key: /SageMakerOutput/1
to_key: title_embedding
- delete_entries:
with_keys:
- content
- SageMakerOutput
sink:
- opensearch:
hosts: ["https://search-xunzh-test-offlinebatch-kitdj4jwpiencfmxpklyvwarwa.us-west-2.es.amazonaws.com"]
aws:
serverless: false
region: us-west-2
routes:
- ml-ingest-route
index_type: custom
index: test-nlp-index
routes:
- ml-ingest-route: /chapter != null and /title != null
Step 3: Prepare your data for ingestion
This example uses the MS MARCO dataset, a collection of real user queries, for natural language processing tasks. The dataset is structured in JSONL format, where each line represents a request sent to the ML embedding model:
{"_id": "1185869", "text": ")what was the immediate impact of the success of the manhattan project?", "metadata": {"world war 2"}}
{"_id": "1185868", "text": "_________ justice is designed to repair the harm to victim, the community and the offender caused by the offender criminal act. question 19 options:", "metadata": {"law"}}
{"_id": "597651", "text": "what color is amber urine", "metadata": {"nothing"}}
{"_id": "403613", "text": "is autoimmune hepatitis a bile acid synthesis disorder", "metadata": {"self immune"}}
...
For this test, we constructed 1 billion input requests distributed across 100 files, each containing 10 million requests. These files are stored in S3 with the prefix s3://offlinebatch/sagemaker/sagemaker_djl_batch_input/. The OpenSearch Ingestion pipeline scans these 100 files simultaneously and initiates an Amazon SageMaker batch job with 100 workers for parallel processing, enabling efficient vectorization and ingestion of the 1 billion documents into OpenSearch Service.
In production environments, you can use an OpenSearch Ingestion pipeline to generate S3 files for batch inference input. The pipeline supports various data sources (see Sources) and operates on a schedule, continuously transforming source data into S3 files. These files are then automatically processed by AI servers through scheduled offline batch jobs, ensuring continuous data processing and ingestion.
Step 4: Monitor the batch inference jobs
You can monitor the batch inference jobs using the Amazon SageMaker console or CLI. Alternatively, you can use the Get Task API to monitor batch jobs:
GET /_plugins/_ml/tasks/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"state": "RUNNING"
}
}
]
}
},
"_source": ["model_id", "state", "task_type", "create_time", "last_update_time"]
}
The API returns a list of active batch job tasks:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 0.0,
"hits": [
{
"_index": ".plugins-ml-task",
"_id": "nyWbv5EB_tT1A82ZCu-e",
"_score": 0.0,
"_source": {
"model_id": "nyWbv5EB_tT1A82ZCu-e",
"state": "RUNNING",
"task_type": "BATCH_PREDICTION",
"create_time": 1725496527958,
"last_update_time": 1725496527958
}
},
{
"_index": ".plugins-ml-task",
"_id": "miKbv5EB_tT1A82ZCu-f",
"_score": 0.0,
"_source": {
"model_id": "miKbv5EB_tT1A82ZCu-f",
"state": "RUNNING",
"task_type": "BATCH_PREDICTION",
"create_time": 1725496528123,
"last_update_time": 1725496528123
}
},
{
"_index": ".plugins-ml-task",
"_id": "kiLbv5EB_tT1A82ZCu-g",
"_score": 0.0,
"_source": {
"model_id": "kiLbv5EB_tT1A82ZCu-g",
"state": "RUNNING",
"task_type": "BATCH_PREDICTION",
"create_time": 1725496529456,
"last_update_time": 1725496529456
}
}
]
}
}
Step 5: Run semantic search
Now you can run a semantic search against your 1 billion vectorized data points. To search raw vectors, use the knn query type, provide the vector array as input, and specify the k number of returned results:
GET /my-raw-vector-index/_search
{
"query": {
"knn": {
"my_vector": {
"vector": [0.1, 0.2, 0.3],
"k": 2
}
}
}
}
To run an AI-powered search, use the neural query type. Specify the query_text input, the model_id of the embedding model you configured in the OpenSearch Ingestion pipeline, and the k number of returned results. To exclude embeddings from search results, specify the name of the embedding field in the _source.excludes parameter:
GET /my-ai-search-index/_search
{
"_source": {
"excludes": [
"output_embedding"
]
},
"query": {
"neural": {
"output_embedding": {
"query_text": "What is AI search?",
"model_id": "mBGzipQB2gmRjlv_dOoB",
"k": 2
}
}
}
}
Conclusion
The integration of ML Commons with OpenSearch Ingestion represents a big step forward for large-scale ML data processing and ingestion. OpenSearch Ingestion’s multi-pipeline design handles data preparation, batch inference, and ingestion efficiently, supporting AI services like Amazon Bedrock and Amazon SageMaker. The system can process 1 billion requests with parallel processing and dynamic resource use while cutting batch inference costs by 50% compared to real-time processing. This makes the solution ideal for tasks like semantic search, multimodal search, and document enrichment, where fast and large-scale vector creation is critical. Overall, this integration improves ML-powered search and analytics in OpenSearch, making these operations more accessible, efficient, and cost effective.
What’s next?
Looking ahead, we plan to extend the ml_inference processor’s capabilities to support real-time model predictions. This enhancement will introduce a new operating mode for the s3 scan source. In this mode, the processor will fully read and process the contents of input files, enabling immediate vector generation through real-time inference. This dual-mode functionality will provide you with the flexibility to choose between efficient batch processing for large-scale operations and real-time processing for immediate inference needs.
For more information, see the ml_inference processor documentation. We welcome your feedback on the OpenSearch forum.

