

Introduction
The Amazon Elastic Compute Cloud (Amazon EC2) team recently leveraged the OpenSearch Model Context Protocol (MCP) server to revolutionize their droplet quality investigations. By connecting Amazon Q with multiple OpenSearch clusters simultaneously, they’ve transformed a previously manual, time-consuming process into an efficient, automated workflow. This blog post explores how the Amazon EC2 team implemented this solution, the technical setup involved, and the impressive results they’ve achieved.
The challenge
The EC2 team manages droplet quality across their fleet, investigating failures and impairments to maintain reliability. Their data was distributed across multiple OpenSearch clusters in various AWS Regions, each storing logs for different components. Engineers faced a multi-step process when troubleshooting:
- Search in one cluster to find initial information.
- Use those findings to query another cluster.
- Correlate data across multiple sources.
- Repeat until the root cause is identified.
This manual process required deep knowledge of data locations and search patterns. The team realized their engineers’ time would be better spent solving problems rather than hunting for and correlating data across systems.
The solution
The EC2 team implemented a solution combining:
- Amazon Q CLI as the intelligent agent for analyzing data and providing insights.
Note: While this post demonstrates the solution with Amazon Q CLI, you can also use any other agentic solution, such as Claude, OpenAI, or other AI agents that support MCP.
- OpenSearch MCP server as the connectivity layer for multiple OpenSearch clusters.
- An EC2 instance running the agent with an attached instance role for secure cluster access.
- AWS Identity and Access Management (IAM)-based authentication for secure authentication to different clusters.
The following architecture diagram illustrates how these components work together.
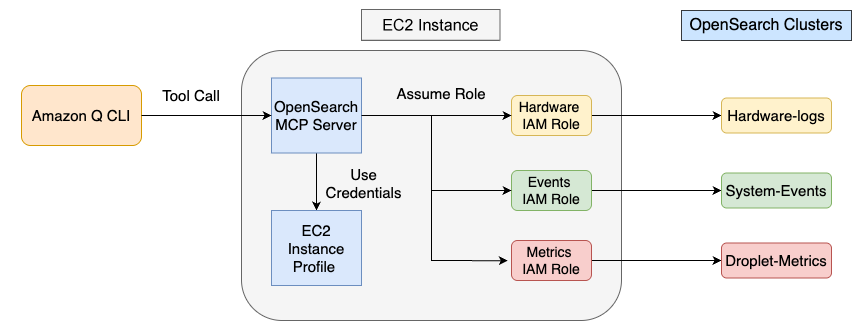
The architecture shows Amazon Q CLI connecting to an EC2 instance that runs the OpenSearch MCP server. The OpenSearch MCP server retrieves credentials from the EC2 instance profile and dynamically assumes the appropriate IAM role at runtime based on the query, providing access to the corresponding OpenSearch cluster (hardware-logs, droplet-metrics, or system-events).
The key innovation was leveraging the OpenSearch MCP server’s multi-cluster connectivity feature, which allowed the EC2 team to interact with multiple OpenSearch clusters through a single interface, avoiding tool proliferation that could overwhelm the agent.
Implementation steps
Step 1: Set up IAM authentication
The EC2 team’s infrastructure spans three OpenSearch clusters across different AWS accounts:
- hardware-logs: Stores hardware engineering data and failure events
- droplet-metrics: Contains performance metrics and system telemetry
- system-events: Stores lifecycle events and administrative actions
To securely access these distributed clusters, the team implemented an EC2-instance-based authentication solution that allows them to connect to all three clusters from a single location while maintaining proper security controls.
IAM setup steps:
-
Create the three cluster access roles (in cluster accounts): First, the EC2 team created the three IAM roles, in their respective AWS accounts, that would have access to each OpenSearch cluster. Each role needed a trust policy that would allow the EC2 instance role from the main account to assume it.
Example — Hardware logs cluster role (Account: 123456789012):
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::111111111111:role/EC2InstanceRole" }, "Action": "sts:AssumeRole" } ] }Note: The team created similar trust policies for the remaining two cluster roles in their respective accounts (234567890123 and 345678901234).
Each role also needed a permissions policy for OpenSearch access:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "es:ESHttpGet", "es:ESHttpPost", "es:ESHttpPut", "es:ESHttpDelete" ], "Resource": "arn:aws:es:REGION:ACCOUNT_ID:domain/CLUSTER_NAME/*" } ] } -
Create the EC2 instance role.
The team created an IAM role for the EC2 instance with the following trust policy:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "ec2.amazonaws.com" }, "Action": "sts:AssumeRole" } ] } -
Attach an assume role policy.
The team attached the following policy to the EC2 instance role to allow it to assume the cluster access roles across different AWS accounts:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "sts:AssumeRole", "Resource": [ "arn:aws:iam::123456789012:role/hardwareLogsClusterAccessRole", "arn:aws:iam::234567890123:role/dropletMetricsClusterAccessRole", "arn:aws:iam::345678901234:role/systemEventsClusterAccessRole" ] } ] }Note: This policy allows the EC2 instance role to assume roles in the three cluster accounts.
-
Create an instance profile: The EC2 team created an instance profile and attached it to their EC2 instance during launch.
Step 2: Configure Amazon Q CLI to use the OpenSearch MCP server
Next, the team configured Amazon Q CLI running on the EC2 instance to use the OpenSearch MCP server by editing the ~/.aws/amazonq/mcp.json file:
{
"mcpServers": {
"opensearch-mcp-server": {
"command": "uvx",
"args": [
"opensearch-mcp-server-py",
"--mode", "multi",
"--config", "/path/to/config.yml"
],
"env": {}
}
}
}
Step 3: Define OpenSearch cluster configuration
Next, they created a YAML configuration file (clusters.yml) defining all their OpenSearch clusters:
version: "1.0" description: "OpenSearch cluster configurations" clusters: # Cluster for hardware engineering data (Account: 123456789012) hardware-logs: opensearch_url: "https://<Hardware cluster URL>" iam_arn: "arn:aws:iam::123456789012:role/hardwareLogsClusterAccessRole" aws_region: "us-east-1" # Cluster for droplet metrics (Account: 234567890123) droplet-metrics: opensearch_url: "https://<Metrics cluster URL>" iam_arn: "arn:aws:iam::234567890123:role/dropletMetricsClusterAccessRole" aws_region: "us-west-2" # Cluster for system events (Account: 345678901234) system-events: opensearch_url: "https://<Events cluster URL>" iam_arn: "arn:aws:iam::345678901234:role/systemEventsClusterAccessRole" aws_region: "eu-west-1"
The authentication for each cluster was managed through the instance role attached to the EC2 instance. Since the clusters were in different AWS accounts, the OpenSearch MCP server used the following authentication flow:
- Gets credentials from the attached IAM instance role
- Assumes the provided IAM Amazon Resource Name (ARN) for each cluster across account boundaries
Note: This authentication flow works because the following trust relationships were established during infrastructure setup:
- The EC2 instance role needs permissions to assume target IAM roles (configured in Step 1).
- Each target role needs to trust the EC2 instance role (configured in Step 1).
Key benefits of this solution:
- Enhanced security: No static credentials stored on instances
- Simplified management: Centralized access control through IAM roles
- AWS best practices: Follows recommended security patterns for production environments
- Automatic credential rotation: Credentials refreshed automatically by AWS
The OpenSearch MCP server supports various other authentication methods, like basic authentication (username/password) and direct AWS credential authentication. You can explore more authentication options in the OpenSearch MCP Server User Guide
Step 4: Provide context to Amazon Q
To help Amazon Q make intelligent decisions about which clusters to query, the team provided the following context prompt to Amazon Q about the available clusters and their contents:
The following OpenSearch clusters are available:
* hardware-logs: Contains detailed hardware engineering logs including voltage readings, temperature data, and hardware failure events.
* droplet-metrics: Stores performance metrics for droplets including CPU, memory, network, and storage metrics.
* system-events: Contains system-level events, lifecycle events, and administrative actions.
When investigating droplet failures, first check system-events for any lifecycle events, then examine hardware-logs for potential hardware failures, and finally analyze droplet-metrics for performance anomalies.
This context prompt enables Amazon Q to understand the data structure and develop an intelligent investigation strategy.
The workflow in action
With this setup, the EC2 team could now ask Amazon Q to investigate droplet issues. Here’s an example interaction:
User Query: Analyze droplet failure for hardware ID ABC123 that occurred yesterday.
Amazon Q process:
- Amazon Q determines it needs to check multiple OpenSearch clusters.
- It makes tool calls to the OpenSearch MCP server, specifying which cluster to query:
{
"arguments": {
"opensearch_cluster_name": "system-events",
"index": "lifecycle-events",
"query": {
"bool": {
"must": [
{ "match": { "hardware_id": "ABC123" } },
{ "range": { "timestamp": { "gte": "now-1d", "lte": "now" } } }
]
}
}
},
"name": "SearchIndexTool"
}
- After finding relevant lifecycle events, it queries the hardware logs:
{
"arguments": {
"opensearch_cluster_name": "hardware-logs",
"index": "voltage-readings",
"query": {
"bool": {
"must": [
{ "match": { "hardware_id": "ABC123" } },
{ "range": { "timestamp": { "gte": "2025-07-09T00:00:00", "lte": "2025-07-09T18:30:00" } } }
]
}
}
},
"name": "SearchIndexTool"
}
- Finally, it analyzes performance metrics leading up to the failure:
{
"arguments": {
"opensearch_cluster_name": "droplet-metrics",
"index": "performance-metrics",
"query": {
"bool": {
"must": [
{ "match": { "hardware_id": "ABC123" } },
{ "range": { "timestamp": { "gte": "2025-07-09T17:30:00", "lte": "2025-07-09T18:30:00" } } }
]
}
}
},
"name": "SearchIndexTool"
}
Example response: Analysis of droplet failure for hardware ID ABC123:
Root Cause: Voltage irregularity detected prior to failure
- System event at 18:15:23: Emergency shutdown initiated
- Hardware logs show voltage fluctuations starting at 18:10:05
- Performance metrics indicate CPU temperature increased to 85°C at 18:09:30
Timeline:
- 18:09:30 – CPU temperature spike to 85°C
- 18:10:05 – Voltage fluctuations begin (3.1V to 2.7V)
- 18:15:23 – Emergency shutdown initiated
- 18:15:45 – Droplet failure recorded
Recommendation: Investigate power delivery system for hardware ID ABC123. Similar voltage irregularities were observed in ticket P12345678.
Results and impact
The implementation has delivered significant benefits to the EC2 team:
- Reduced investigation time: What previously required hours of manual correlation now happens in minutes.
- Improved accuracy: The systematic approach eliminates human error in data gathering.
- Knowledge democratization: Less experienced engineers can now investigate complex issues.
- Pattern recognition: Successfully classified approximately 30 previously “unknown” failures.
- Standardized analysis: A consistent format for all investigations improves team collaboration.
Conclusion
The EC2 team has developed a system that can perform this analysis by combining the OpenSearch MCP server with Amazon Q to address real-world operational challenges. Through the integration of multi-cluster connectivity features and IAM authentication, they’ve created a powerful solution designed to rapidly diagnose issues and provide resolution recommendations, which will significantly improve droplet quality across their fleet.
This approach can be adapted by other teams facing similar challenges with distributed data sources, showing the flexibility and power of the OpenSearch MCP server as a critical component in AI-assisted operations. Teams can enhance performance by implementing automated pipelines, expanding context prompts with investigation examples, and continually refining prompts to generate better recommendations.



