
Vector search is the backbone of modern applications like semantic search, recommendation systems, and generative AI retrieval, enabling machines to find similar items by comparing their positions in a high-dimensional space. However, existing vector search engines often face limitations. For example, Faiss, a powerful approximate nearest neighbors (ANN) library, requires the entire index to fit in memory, constraining scalability. Lucene’s vector search, while more memory efficient, does not match Faiss in performance.
To address these tradeoffs, we’ve developed a hybrid approach called Lucene-on-Faiss that combines the best of both worlds. By enabling Lucene’s search engine to directly use Faiss’s high-performance HNSW graph indexes, we’ve unlocked a 2X boost in search throughput while overcoming Faiss’s memory limitations. In this post, we’ll dive into how this integration works and the impressive performance results it delivers for OpenSearch’s vector search use cases.
Toward the best vector database: A hybrid approach
OpenSearch aims to be the leading vector database that doesn’t just meet expectations but redefines them. To achieve this goal, we combined the strongest aspects of the most industry-tested libraries in the space: Faiss and Lucene. Before diving into our hybrid design, let’s walk through how the Faiss and Lucene engines work.
How Faiss works
Developed by Facebook AI Research, Faiss is a high-performance library written in C++ for similarity search that uses SIMD instructions to efficiently compute distances between vectors. It offers powerful features like product quantization (PQ), FP16 support, and GPU-based indexing, making it ideal for large-scale, high-throughput applications.
However, Faiss requires loading the entire index into memory: the engine allocates a contiguous off-heap memory block equal to the size of the vector data. For example, a 10 GB flat index requires 10 GB of physical memory. As a result, Faiss cannot operate in memory-constrained environments. For example, in a system with 16 GB of RAM, it is impossible to store a Faiss index larger than 16 GB, making scalability challenging without significant hardware investment.
How Lucene works
Lucene is a highly optimized search engine library written in Java that has recently added native support for vector search, enabling similarity search alongside traditional keyword and filter queries. Unlike Faiss, Lucene allows partial loading of vector data and supports score-based retrieval. This design makes Lucene more flexible and resource efficient, particularly in memory-constrained environments. A key factor behind this efficiency is Lucene’s Directory abstraction, which controls how data is read from and written to the underlying storage. Users can choose different Directory implementations based on their performance and resource requirements.
For example, NIOFSDirectory reads bytes directly from the file system on every request, trading off higher latency for lower memory usage. In contrast, MMapDirectory, the default in OpenSearch, uses operating system memory mapping to access files, reducing I/O overhead but increasing memory consumption. This configurability allows users to tailor Lucene’s vector search to their hardware constraints and enables operation in low-memory environments—difficult to achieve with Faiss’s all-in-memory approach.
Additionally, Lucene’s implementation of the HNSW graph algorithm includes optimizations beyond those in Faiss. These include early termination in concurrent searches: minimum eligible scores are shared between threads to speed up convergence, and visiting more vectors during filtering improves recall.
However, Lucene lacks support for multiple SIMD optimizations (for example, bulk XOR operations or support for FP16 and BFP16 formats) in its distance calculations. These are the areas in which Faiss shines.
In a hybrid approach, we can employ Faiss’s SIMD-powered distance computations while continuing to use Lucene’s efficient HNSW algorithm for search.
Lucene-on-Faiss: Combining Lucene and Faiss
Faiss is great at fast vector search thanks to its use of SIMD for distance calculations. Lucene, meanwhile, shines when it comes to early termination in concurrent searches and loading only the parts of the index it needs.
In a hybrid approach, we decided to plug Faiss’s index into Lucene’s HNSW algorithm so we could use Lucene’s partial loading and early termination features while letting Faiss handle the distance computations using its optimized code. This integration allowed us to operate vector search under memory constraints, even with the Faiss index, while also benefiting from Lucene’s concurrent HNSW optimizations.
As the first step, we successfully ran Lucene’s HNSW algorithm on an index built using Faiss, as shown in the following image.
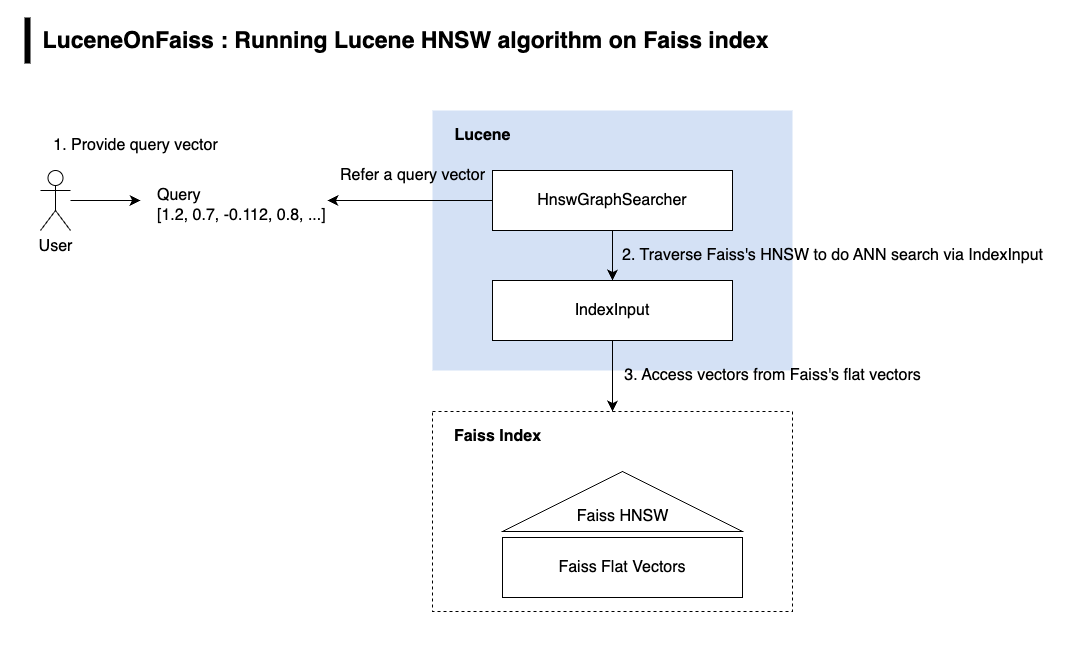
The remaining pieces of the integration are still in progress and will be completed soon.
From the user’s perspective, this hybrid setup is completely transparent. You can enable or disable it using an index setting, and OpenSearch handles the rest behind the scenes. To enable this feature, use the following request and set index.knn.memory_optimized_search to true (default is false):
PUT /my_index { "settings" : { "index.knn": true, "index.knn.memory_optimized_search" : true }, "mappings": { <Index fields> } }
In OpenSearch version 3.1, enabling the on-disk mode with 1x compression also activates this hybrid approach at the field level. In future releases we will make this approach the default for all compression levels with the on-disk mode:
PUT /my_index { "mappings": { "properties": { "my_field": { <Other info> "mode": "on_disk", "compression_level": "1x" } } } }
Lucene-on-Faiss is supported for all HNSW configurations including 1x, 2x, 4x, 16x, and 32x compressions. The current release does not support training-based techniques such as IVF or PQ.
Performance results
Vector search performance can vary significantly depending on memory availability and index configuration. The following sections highlight how OpenSearch performs with Faiss and Lucene under different setups.
Running a 30 GB Faiss index on a t2.large instance
With the new configuration, there’s no need to load the entire index into memory, making it possible to run a vector search using the Faiss engine even in memory-constrained environments. For example, the Faiss index for the Cohere-10m dataset is around 30 GB. Previously, when attempting to run it on a t2.large instance with only 8 GB of memory, the OpenSearch process was terminated due to insufficient memory.
With the new setting enabled, OpenSearch runs successfully under tight memory constraints. Since not all required vectors are kept in memory, some must be read from disk, which results in slower performance compared to an all-in-memory configuration.
Search QPS comparison
How does query-per-second (QPS) performance change when all bytes are loaded into memory in the same environment?
Faiss C++ continues to demonstrate superior performance for FP32 and FP16 because of its use of bulk SIMD for fast distance computation, whereas Java incurs an overhead of converting FP16 to FP32. For both FP32 and FP16, we observed a slight improvement in recall, likely because Faiss uses a fixed number of visits to explore the HNSW graph, while Lucene continues exploration until no relevant candidates remain.
In quantization scenarios (8x, 16x, and 32x), Lucene-on-Faiss achieves better performance, with only a mild recall drop (up to 4.5%) because of Lucene’s early termination logic, which we plan to improve in future releases. As the value of k increases, the QPS gap widens. At 32x quantization with k = 100, Lucene-on-Faiss nearly doubles QPS. This demonstrates that Lucene-on-Faiss is not only valuable in memory-constrained environments but also shows strong potential at higher quantization levels.
Benchmarking results
The following tables compare the Faiss C++ and Lucene-on-Faiss approaches across different index types, showing maximum QPS, P99 latency, recall, and the relative QPS improvement and recall changes for Lucene-on-Faiss.
We used the following testing environment:
- Dataset: Cohere-10M
- Metric: Cosine similarity
- FP32: 3 nodes of r6g.4xlarge, 6 shards
- FP16: 3 nodes of r6g.2xlarge, 6 shards
- 8x, 16x, and 32x quantization: 3 nodes of r7gd.2xlarge, 6 shards
A couple of notes about the table metrics:
-
A negative QPS change of -9.56% indicates a 9.56% performance drop for Lucene-on-Faiss, whereas a positive 51.52% change reflects a 51.52% improvement.
-
In the Recall change column, a positive value (for example, 0.14%) indicates an improvement in recall, while a negative value (for example, -4.52%) indicates a degradation.
k=30
| Index type | Faiss C++ max QPS | Faiss C++ P99 latency (ms) | Faiss C++ recall (%) | Lucene-on-Faiss max QPS | Lucene-on-Faiss P99 latency (ms) | Lucene-on-Faiss recall (%) | QPS change (%) | Recall change (%) |
|---|---|---|---|---|---|---|---|---|
| FP32 | 5419.7308 | 5 | 85.01 | 4901.7447 | 5.6 | 85.13 | -9.56% | 0.14% |
| FP16 | 3157.6034 | 4.9 | 85.11 | 1881.0994 | 6.2 | 85.37 | -40.43% | 0.31% |
| 8x quantization | 404.0391 | 8.7 | 85.29 | 714.5516 | 9.1 | 82.94 | 76.85% | -2.76% |
| 16x quantization | 395.7132 | 8.7 | 85.39 | 732.4748 | 7.2 | 82.42 | 85.10% | -3.48% |
| 32x quantization | 539.9027 | 7.6 | 83.18 | 818.05 | 6.8 | 79.42 | 51.52% | -4.52% |
k=100
| Index type | Faiss C++ max QPS | Faiss C++ P99 latency (ms) | Faiss C++ recall (%) | Lucene-on-Faiss max QPS | Lucene-on-Faiss P99 latency (ms) | Lucene-on-Faiss recall (%) | QPS change (%) | Recall change (%) |
|---|---|---|---|---|---|---|---|---|
| FP32 | 3242.3189 | 5.8 | 92.42 | 2667.47 | 6.8 | 92.78 | -17.73% | 0.39% |
| FP16 | 1908.3005 | 7 | 90.74 | 982.71 | 8.5 | 92.26 | -48.50% | 1.68% |
| 8x quantization | 174.8153 | 13.3 | 87.86 | 411.7968 | 8.4 | 87.17 | 135.56% | -0.79% |
| 16x quantization | 169.87 | 13 | 87.9 | 431.6184 | 8.9 | 86.96 | 154.09% | -1.07% |
| 32x quantization | 227.95 | 13.3 | 87.4 | 472.4701 | 7.9 | 85.9 | 107.27% | -1.72% |
What’s next?
There is still significant untapped potential in the current setup. Currently, SIMD is used internally for FP32 vectors but not for FP16 or binary vectors. In upcoming versions, we plan to enable Faiss’s SIMD optimizations for all vector types. For example, FP16 vectors currently need to be converted to FP32, but with SIMD, distances can be computed directly in Java, improving speed. Other data types will also benefit from SIMD integration, further boosting performance.
Additionally, we are exploring explicit off-heap vector loading to further enhance performance. Overall, there are many opportunities to make vector search faster and more efficient, and we will continue incorporating these improvements into OpenSearch.
Interested in how the feature is progressing or want to get involved? Follow the development of the feature and join the conversation in this GitHub issue.

