

Image source: Created by DALL·E 3
From observing change to measuring search quality
In the first post of this three-part series, we focused on how to measure change when switching from one search configuration to another. We did this by visually exploring the transitions of result documents from one search result to the next and objectively quantifying this change with metrics.
Change is an important indicator of risk: the more change we measure, the riskier the underlying search algorithm adjustments are. Eyeballing the concrete differences gives search practitioners a first impression of the potential qualitative impact.
However, quantifying change only tells us how different two result lists are. It tells us nothing about the quality of this change.
In this blog post, we’ll go beyond measuring change with the goal of understanding relevance and search result quality. We’ll introduce the concepts of judgments, their role in search quality quantification, and how the Search Relevance Workbench, released with OpenSearch 3.1, supports the next steps on your journey to systematic search quality improvements.
The quest: Quantifying search quality
Measuring search quality is a foundational asset for any search team—after all, you can’t improve what you can’t measure. As search practitioners, we may have an intuition about what constitutes “good” results or have ideas that could lead to them, but we need a systematic approach to prove it.
The need for a systematic approach goes beyond simply eyeballing and visually comparing results, and the Search Relevance Workbench has several features to help. We’ll continue to rely on the concepts of query sets and search configurations that we introduced in the first post:
- Query set: A query set is a collection of queries relevant to your search application’s domain.
- Search configuration: A search configuration tells the experiments within the Search Relevance Workbench how queries should be executed.
Let’s now go beyond these concepts and explore how we can measure search quality with the Search Relevance Workbench.
The Search Relevance Workbench: Metrics and judgment lists
A judgment list is a foundational asset for quantifying search quality, as it tells us what good and bad search results look like. In short, a judgment list contains triplets, each made up of a query, a document, and a rating.
For example: t towels kitchen, B08TB56XBX, 1.0
This triplet indicates that for the query “t towels kitchen,” the document with the ID “B08TB56XBX” has a rating of 1.0. To properly measure search quality, we need multiple judgments, which is why we use the term judgment lists.
Typically, judgments are categorized into two types: implicit and explicit. Implicit judgments are ratings derived from user behavior, such as which results were seen and clicked. Traditionally, explicit judgments were made by humans, but nowadays, large language models (LLMs) are increasingly taking over this role. The Search Relevance Workbench supports all types of judgments:
- It allows generating implicit judgments based on data that adheres to the User Behavior Insights (UBI) schema specification.
- It offers users the ability to leverage LLMs to generate judgments by connecting OpenSearch to an API or an internally or externally hosted model.
- For OpenSearch users who already have processes for generating judgments, the Search Relevance Workbench can also import them.
In the first blog post of this three-part series, we focused on measuring the change between a keyword search configuration and a hybrid search configuration to get an impression of how different, and potentially useful, such a switch might be.
Setting up OpenSearch with the Search Relevance Workbench
If you already followed the first part of this series and have your OpenSearch installation ready, you can skip the setup steps and proceed to the section on validating the requirements.
Setting up the environment
To follow this guide, you’ll need an OpenSearch instance with the Search Relevance Workbench. The following steps will clone the necessary repositories and start a local OpenSearch cluster, complete with all the required data and plugins. By following these instructions, you will configure an OpenSearch setup with sample e-commerce product data, which you will use to measure search result quality.
First, clone the repository that accompanies this blog post series:
```
git clone https://github.com/o19s/srw-blogs.git
```
Next, change into the repository’s directory and start the Docker containers:
```
cd srw-blogs
```
```
docker compose up -d
```Setting up OpenSearch and indexing the data
Next, clone the Search Relevance Workbench backend repository, which includes sample data and a script to quickly set everything up:
```
git clone https://github.com/opensearch-project/search-relevance.git
```
Now, navigate to the script directory and run the setup script:
```
cd search-relevance/src/test/scripts
```
```
./demo_hybrid_optimizer.sh
```In short, this script performs the following actions: it sets up an OpenSearch instance with the Search Relevance Workbench backend feature, indexes product data (including embeddings), and prepares the environment for measuring the search quality of both a keyword and a hybrid search configuration.
Creating a query set
In the first post of this series, a query set was used to understand the impact of changes between search configurations. Now, you’ll use a similar set of queries to gain the next level of insight: measuring the search quality impact of a different search configuration.
For this guide, you’ll manually create a query set using the one provided in the Github repository accompanying this series:
```
{"queryText": "laptop"}
{"queryText": "red shoes"}
{"queryText": "in-ear headphones"}
{"queryText": "portable bluetooth speakers"}
{"queryText": "stainless steel mending plates"}
{"queryText": "funny shirt birthday present"}
```You can upload this file using the drag-and-drop feature in the OpenSearch Dashboards UI for the Search Relevance Workbench. Alternatively, you can use the corresponding API. If you already created this query set while following the previous blog post, feel free to use that one.
Here is the API call to create the query set:
```
PUT _plugins/_search_relevance/query_sets
{
"name": "SRW Blog Post Query Set",
"description": "A query set for the SRW blog post with six queries",
"sampling": "manual",
"querySetQueries": [
{"queryText": "laptop"},
{"queryText": "red shoes"},
{"queryText": "in-ear headphones"},
{"queryText": "portable bluetooth speakers"},
{"queryText": "stainless steel mending plates"},
{"queryText": "funny shirt birthday present"}
]
}
```Creating search configurations
Next, you need to create two search configurations: one for keyword search and one for hybrid search. You will use the same configurations as in the first blog post. If you already have these in your installation, you can reuse them.
You can upload the search configurations one by one using the APIs.
Creating the keyword search configuration
First, let’s create a search configuration for keyword search:
```
PUT _plugins/_search_relevance/search_configurations
{
"name": "keyword",
"query": """{"query":{"multi_match":{"query":"%SearchText%","fields":["id","title","category","bullet_points","description","brand","color"]}}}""",
"index": "ecommerce"
}
```To create the hybrid search configuration, you first need to find the model_id that will be used to generate the user query embeddings. You can find this ID by searching for it:
```
POST /_plugins/_ml/models/_search
{
"query": {
"match_all": {}
},
"size": 1
}
```The response will appear similar to the following. Note the model_id in the _source field, which you’ll use in the next step:
```
{
"took": 62,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 11,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": ".plugins-ml-model",
"_id": "VI1WMZgBm3ZaLrDFy2Ij_2",
"_version": 1,
"_seq_no": 3,
"_primary_term": 1,
"_score": 1,
"_source": {
"model_version": "1",
"created_time": 1753174432098,
"chunk_number": 2,
"last_updated_time": 1753174432098,
"model_format": "TORCH_SCRIPT",
"name": "huggingface/sentence-transformers/all-MiniLM-L6-v2",
"is_hidden": false,
"model_id": "VI1WMZgBm3ZaLrDFy2Ij",
"total_chunks": 10,
"algorithm": "TEXT_EMBEDDING"
}
}
]
}
}
```Creating the hybrid search configuration
Now you can create the hybrid search configuration. Remember to replace VI1WMZgBm3ZaLrDFy2Ij with your specific model_id:
```
PUT _plugins/_search_relevance/search_configurations
{
"name":"hybrid search",
"index":"ecommerce",
"query":"{\"query\":{\"hybrid\":{\"queries\":[{\"multi_match\":{\"query\":\"%SearchText%\",\"fields\":[\"id\",\"title\",\"category\",\"bullet_points\",\"description\",\"brand\",\"color\"]}},{\"neural\":{\"title_embedding\":{\"query_text\":\"%SearchText%\",\"k\":100,\"model_id\":\"VI1WMZgBm3ZaLrDFy2Ij\"}}}]}},\"size\":10,\"_source\":[\"id\",\"title\",\"category\",\"brand\",\"image\"]}",
"searchPipeline":"normalization-pipeline"
}
```The importance of representative query sets
To systematically measure search quality, it’s crucial to use a broad and representative set of queries that reflect your entire user base. Ideally, query sets are sampled from real user queries. The Search Relevance Workbench supports this with a sampling technique called Probability-Proportional-to-Size sampling. For the purposes of this blog post, however, our set of six queries is sufficient for a clear and comprehensible example.
Validating the prerequisites
To confirm that you have everything needed to run search quality experiments, navigate to the Search Relevance Workbench UI:
- Open your web browser and go to http://localhost:5601.
- In the left navigation menu, select Search Relevance.
Note: The Search Relevance Workbench is an opt-in feature as of OpenSearch 3.1. If you haven’t already, you must enable the frontend plugin by going to Management > Dashboards Management > Advanced Settings, turning on the toggle for Experimental Search Relevance Workbench, and saving the changes.
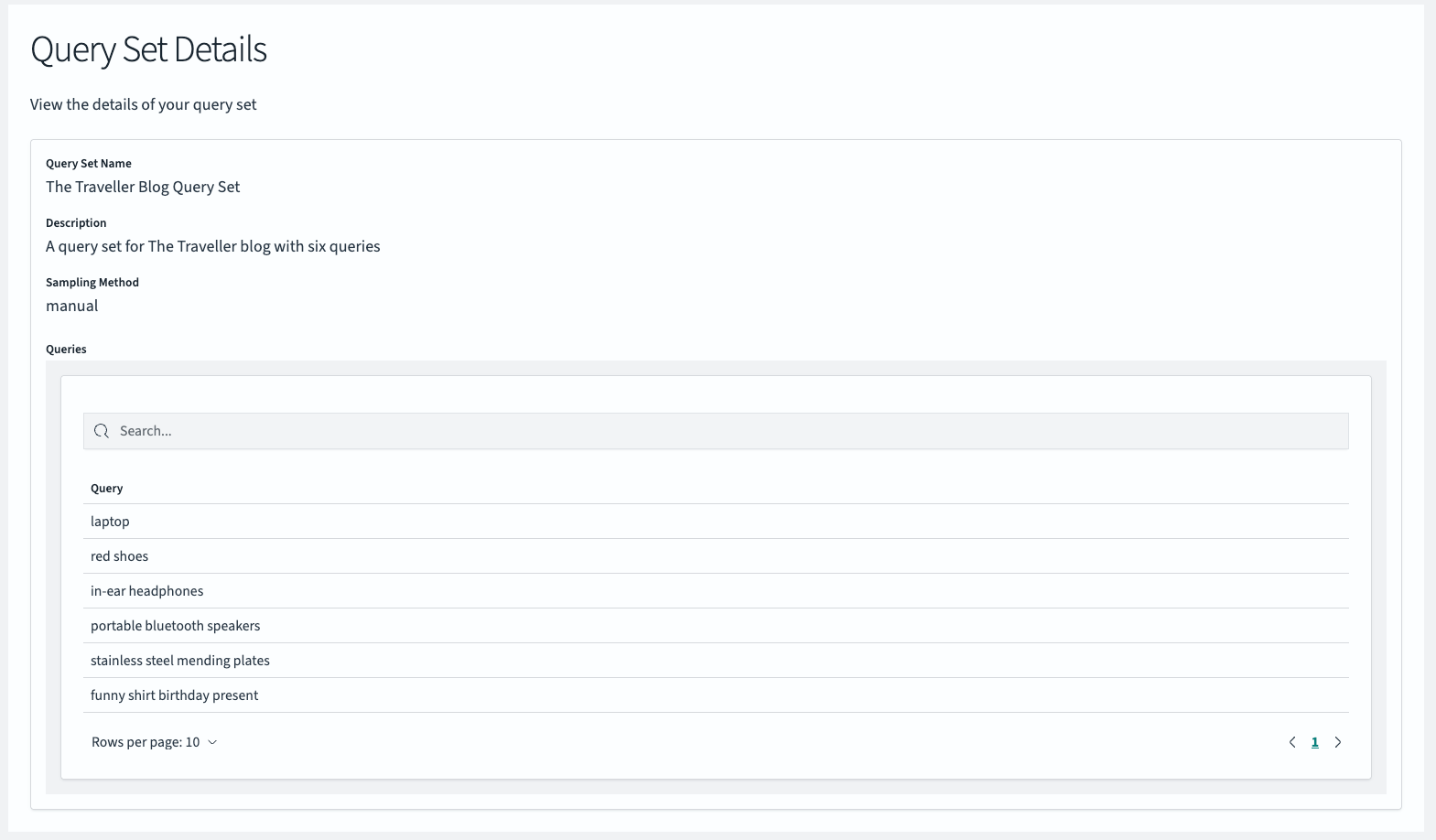
Checking the query set
Next, verify that your query set is present:
- Navigate to the Query Sets section.
- Select the query set named SRW Blog Post Query Set.
- In the detail view, you should see the six queries you created.
 Checking the search configurations
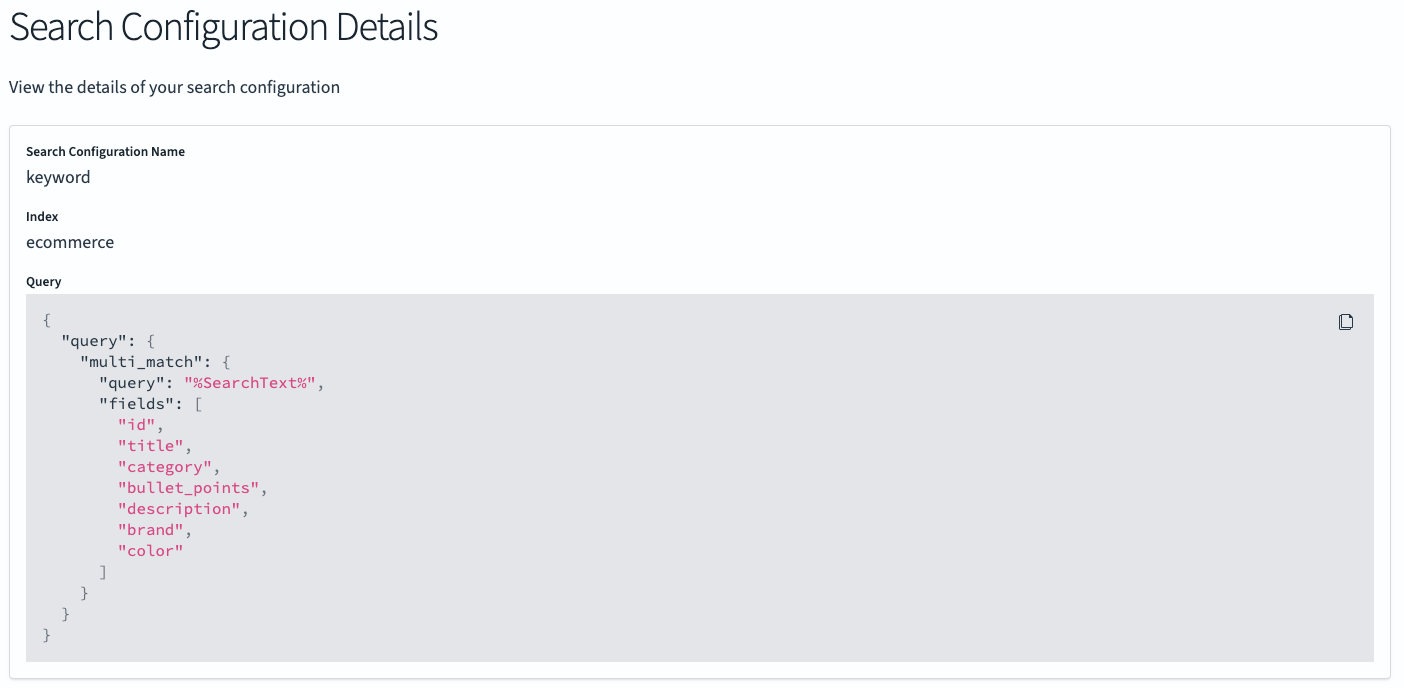
Checking the search configurations
To confirm that your search configurations are present, navigate to the Search Configurations section. You should see both the keyword and hybrid search configurations listed.
First, select the keyword configuration.
You’ll see the details for the keyword search, which should match the configuration you created earlier. The index name, ecommerce, and the multi-match query are shown.
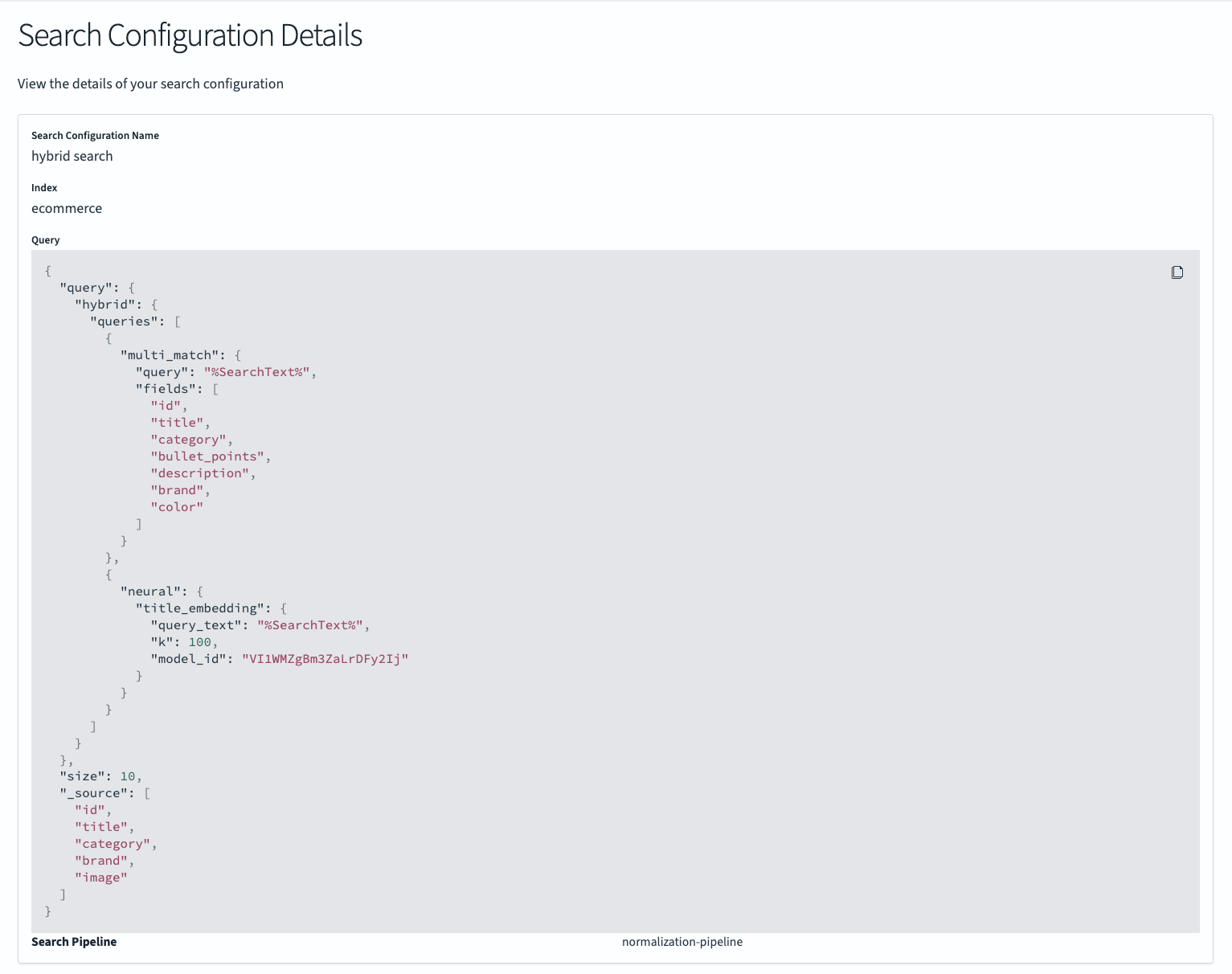
Next, select the hybrid search configuration. The query will differ from the one used in the keyword configuration in that it contains a hybrid search query.
Understanding judgment lists
With the configurations confirmed, you can now turn to the new element needed to measure search quality: judgment lists.
For this guide, you will import a judgment list that contains ratings for all the query-document pairs you’ll retrieve for your two search configurations. First, look at its structure:
```
{
"name": "SRW Blog Post Judgments",
"description": "Imported judgment list for the SRW blog post",
"type": "IMPORT_JUDGMENT",
"judgmentRatings": [
{
"query": "funny shirt birthday present",
"ratings": [
{
"docId": "B07PH417T1",
"rating": "3.000"
},
{
"docId": "B08ZM5VN5S",
"rating": "0.000"
},
…
```This JSON structure shows how judgments are organized. Each entry in judgmentRatings corresponds to a query, and within each query, there is a list of ratings for specific documents. Each rating is a triplet containing a docId and a numerical rating. This allows you to quantify the relevance of each document for a given query.
Uploading a judgment list
You’ll be importing a judgment list with the type IMPORT_JUDGMENT, which was compiled outside the Search Relevance Workbench. This allows you to focus on using the judgment list to measure search quality. The topic of creating judgment lists is extensive enough to warrant a separate blog post of its own, so we’ll share a couple of practical tips to get you started at the end of this post.
For every query, the imported list provides a series of judgments, each consisting of a docId (the unique identifier for a document in your search index) and a rating on a scale from 0 to 3. The rating tells you how relevant a document is for a given query. The higher the rating, the more relevant the document:
- 0: Not relevant at all.
- 1: Slightly relevant; contains some related information but doesn’t directly address the query.
- 2: Moderately relevant; addresses part of the query or is generally useful.
- 3: Highly relevant; directly answers the query and is very useful.
For this guide, you’ll use an explicit judgment list that was created by the LLM GPT-4o mini. The list is already formatted for import into the Search Relevance Workbench to demonstrate the process.
To upload the judgment list, run the following curl command from the root directory of the cloned repository. This command posts the judgment list to the corresponding API endpoint in the Search Relevance Workbench:
```
curl -s -X PUT "localhost:9200/_plugins/_search_relevance/judgments" \
-H "Content-type: application/json" \
--data-binary @./part2/judgments.json
```The API will respond with a unique ID for the newly uploaded judgment list:
```
{"judgment_id":"4451a0ee-5b59-44d3-97d7-af893f2b81d3"}
```Now that all the prerequisites are in place, you’ll put all the pieces together by creating and running experiments.
Calculating search metrics to measure search quality
Returning to the goal of creating a reliable “measuring stick” for search quality, you now have all the necessary components: a query set, two search configurations (one for keyword search and one for hybrid search), and a judgment list that provides you with relevance ratings for query-document pairs.
In the Search Relevance Workbench, the process of calculating search quality metrics is embedded within experiments. In our first blog post, we demonstrated a search result list comparison. Now, we’ll introduce the next experiment type: the search evaluation experiment, also known as a pointwise experiment.
A search evaluation experiment requires five parameters:
querySetId: The ID of the query set.searchConfigurationList: A list of search configuration IDs to be used for comparison.judgmentList: The ID of the judgment list to use for evaluating search accuracy.size: The number of documents to return in the results for metric calculation.type: POINTWISE_EVALUATIONis the type for evaluating a search configuration against judgments.
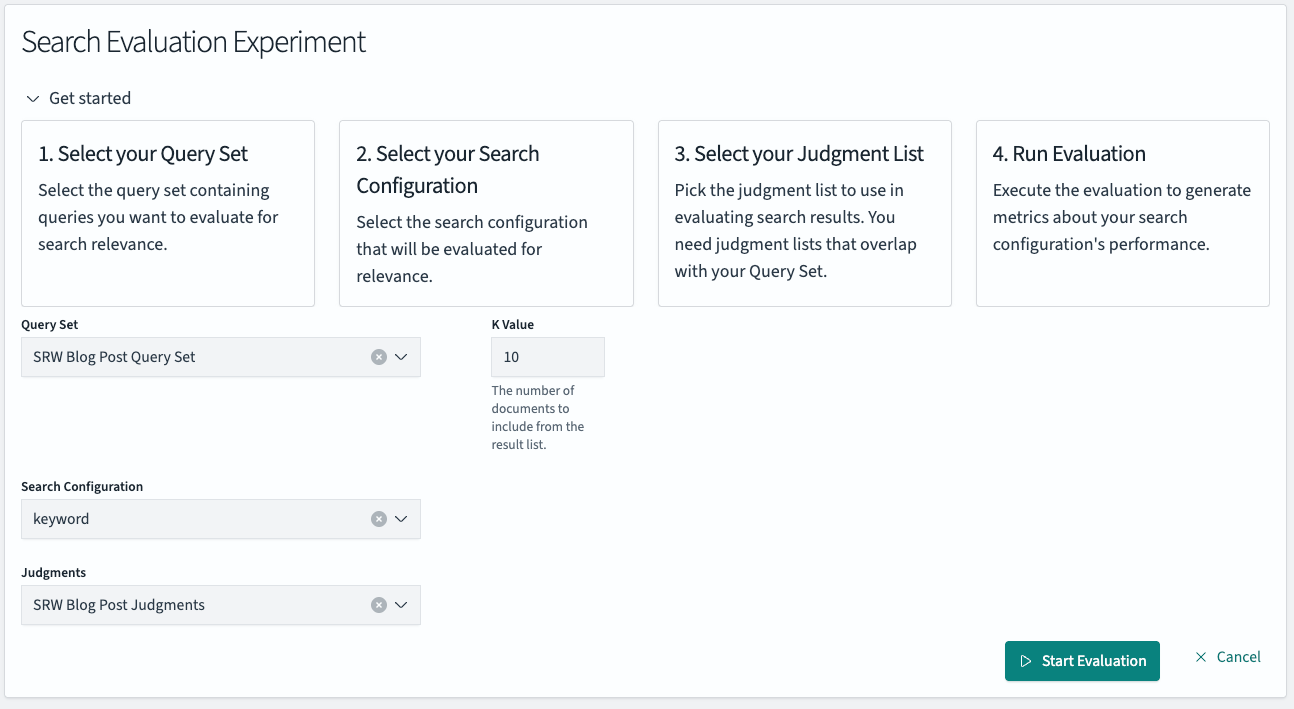
The frontend of the Search Relevance Workbench assists you in configuring this experiment. In OpenSearch Dashboards, navigate to Search Relevance > Experiments > Search Evaluation.
To measure the search quality of your two search configurations—keyword and hybrid search—and determine which performs better, you will create two separate experiments.
Both experiments will use the same query set and judgment list. The only difference will be the search configuration used in each.
Go ahead and create these two experiments, assigning one the keyword search configuration and the other the hybrid search configuration. Once configured, confirm each experiment by selecting the Start Evaluation button.
The experimentation process
During the experimentation process, the top 10 search results for each of the 6 queries in your query set are retrieved using the corresponding search configuration. This results in up to 60 query-document pairs per search configuration. For each pair, the experiment checks the judgment list for a relevance rating.
It is common and perfectly acceptable for not all query-document pairs to have a judgment. Typically, if a judgment is unavailable, search metrics will assume the document is irrelevant. There are several reasons for missing judgments:
- Explicit judgments: For judgments made by humans or LLMs, a different search configuration may return a new set of top N documents that may not have been previously rated.
- Implicit judgments: Judgments based on user behavior can only be created for query-document pairs that users have been exposed to. If a document never appeared in a user’s search results, there will be no behavioral data from which to form a judgment.
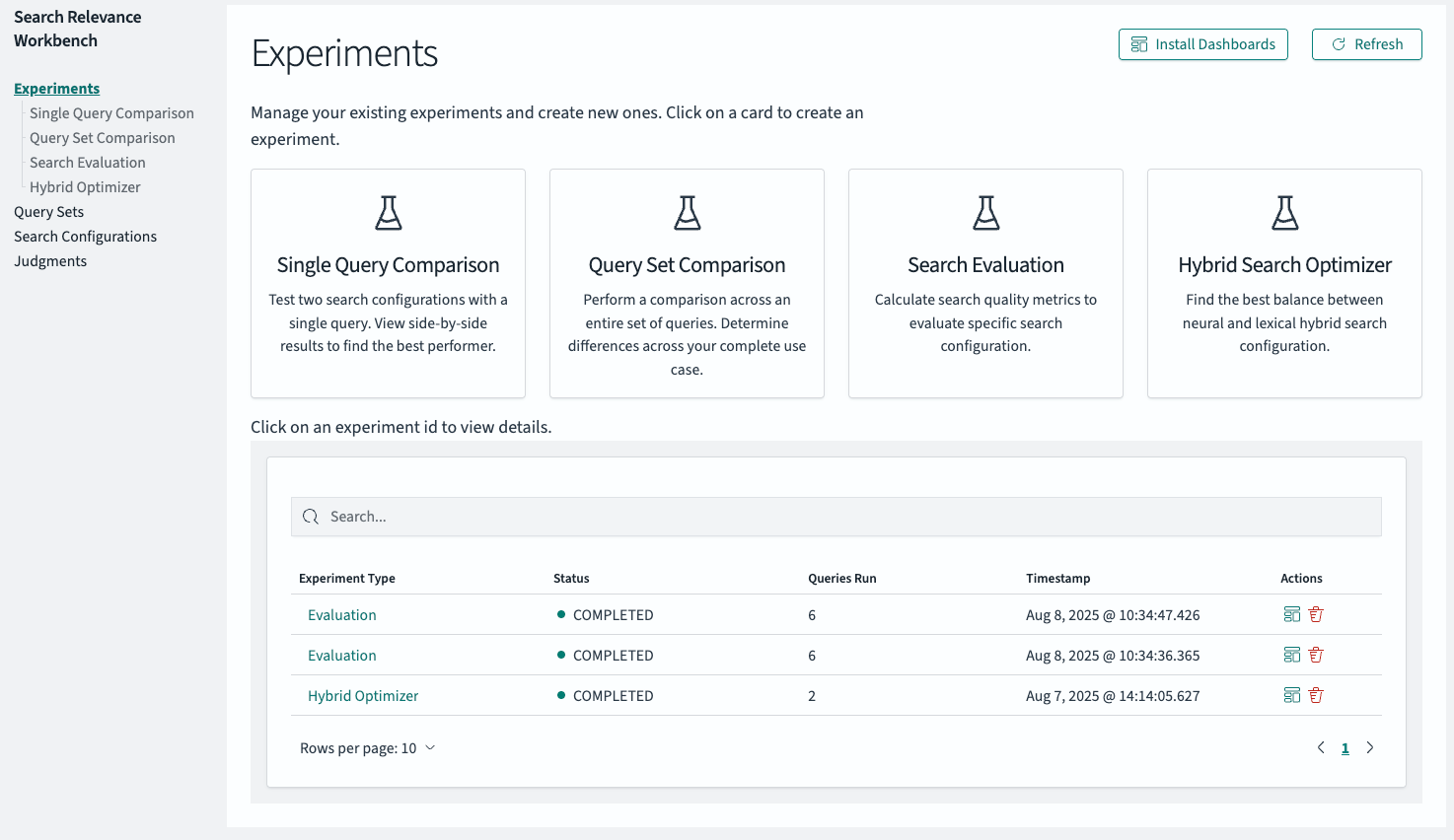 Verifying experiment completion
Verifying experiment completion
Shortly after initiating them, the two experiments should appear in the experiments overview table. You can verify their status by confirming that they are both of type Evaluation and have a status of COMPLETED.
Selecting the first one takes you to the results view.
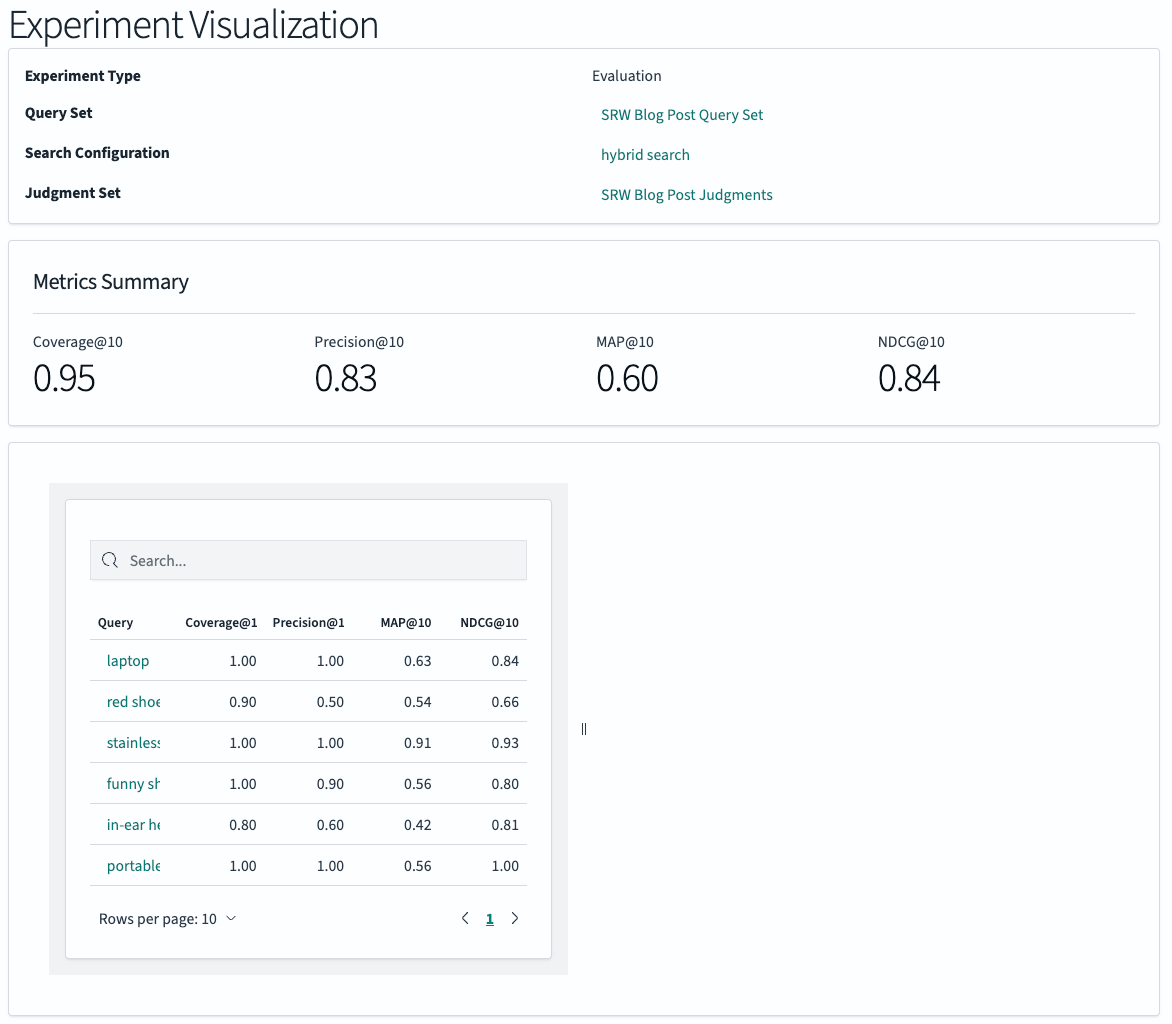
Search metrics and their meanings
The search metrics displayed are Precision, Mean Average Precision (MAP), and Normalized Discounted Cumulative Gain (NDCG). Additionally, Judgment Coverage (Coverage) is calculated to give users a sense of the reliability of the other metrics:
- Coverage: Coverage@k represents the ratio of query-document pairs in the search results that have a relevance judgment. It indicates how much of the returned data has been evaluated for relevance, providing a measure of the reliability of the calculated metrics.
- Precision: Precision@k measures the proportion of retrieved documents that are relevant. For a given rank k, Precision@k is the number of relevant documents among the top k results, divided by k.
- MAP: MAP@k is a single-figure measure of quality across different recall levels. For a single query, Average Precision (AP) is the average of the precision values calculated at the rank of each relevant document. MAP is the mean of these AP scores across all queries.
- NDCG: NDCG@k measures the usefulness, or gain, of documents based on their position in the result list. The gain is accumulated from the top of the list, with the relevance of documents at lower ranks being “discounted.” The score is normalized to between 0 and 1, where 1 represents a perfect ranking.
Interpreting aggregate search metrics
With the two experiments completed, let’s look at the results. The aggregate metrics show the search configuration using a hybrid search approach as the winner.
The following are the metrics for the keyword search configuration:
The following are the metrics for the hybrid search configuration:

Let’s interpret these numbers. The judgment coverage is equal for both search configurations (0.93), as is the precision (0.82). However, the MAP (0.60 vs. 0.55) and NDCG (0.82 vs. 0.69) scores are higher for the hybrid search.
The identical precision score of 0.82 indicates that both search configurations are equally effective at retrieving relevant documents. For this metric, a relevant document is defined as one with a non-zero judgment rating (this definition may change in future implementations).
A higher MAP score indicates that the hybrid search configuration places relevant documents in the top positions more frequently.
A higher NDCG score indicates that the retrieved results are not only closer to the ideal set of relevant documents but also to their ideal ranking, according to all the query-document judgments in the list.
Interpreting search metrics for individual queries
While aggregate metrics provide a general direction, it’s always important to look at the individual query level. Examining the metrics for individual queries can help you understand which classes of queries benefit most from the hybrid search configuration. Additionally, you can ensure that the search quality for queries that are particularly important to your application does not decrease.
In the following screenshot, the individual search metrics of the keyword search configuration (on the left) are displayed next to those of the hybrid search configuration (on the right).
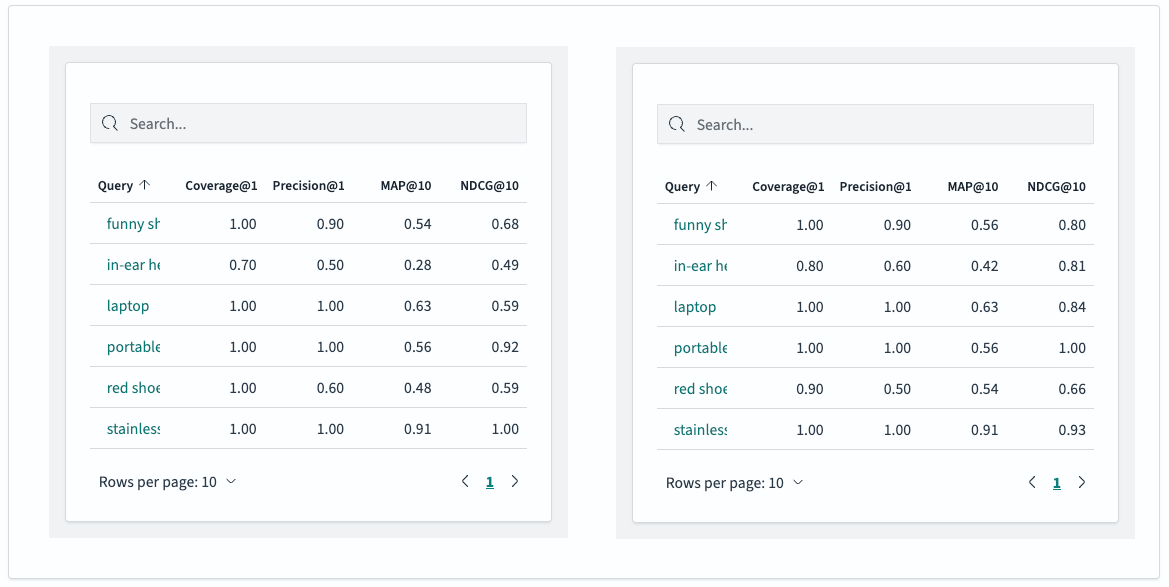
When looking at the results for the six queries, you can see that the hybrid search configuration only has two individual metrics that are lower than those for the keyword search:
- “Red shoes”: The precision for “red shoes” dropped from 0.60 to 0.50, and the judgment coverage for the top 10 results also decreased from 0.60 to 0.50. This means the hybrid search retrieved one less relevant result than the keyword search. However, the MAP and NDCG scores increased, indicating that the ordering of the results improved despite retrieving one less relevant document.
- “Stainless steel mending plates”: The NDCG for this query dropped from a perfect 1.00 to 0.93. This shows that the ordering of the retrieved results changed for the worse, but the results are still of high quality overall.
Viewing experiment results in dashboards
While a tabular format is excellent for examining metrics for individual queries—especially top-performing, low-performing, or business-critical ones—it becomes unwieldy with query sets containing dozens, hundreds, or even thousands of queries.
To support users in visually exploring experiment results more easily, the Search Relevance Workbench integrates with dashboards starting in version 3.2. You can install dashboards by selecting the corresponding button in the upper-right corner of the Experiments overview page.
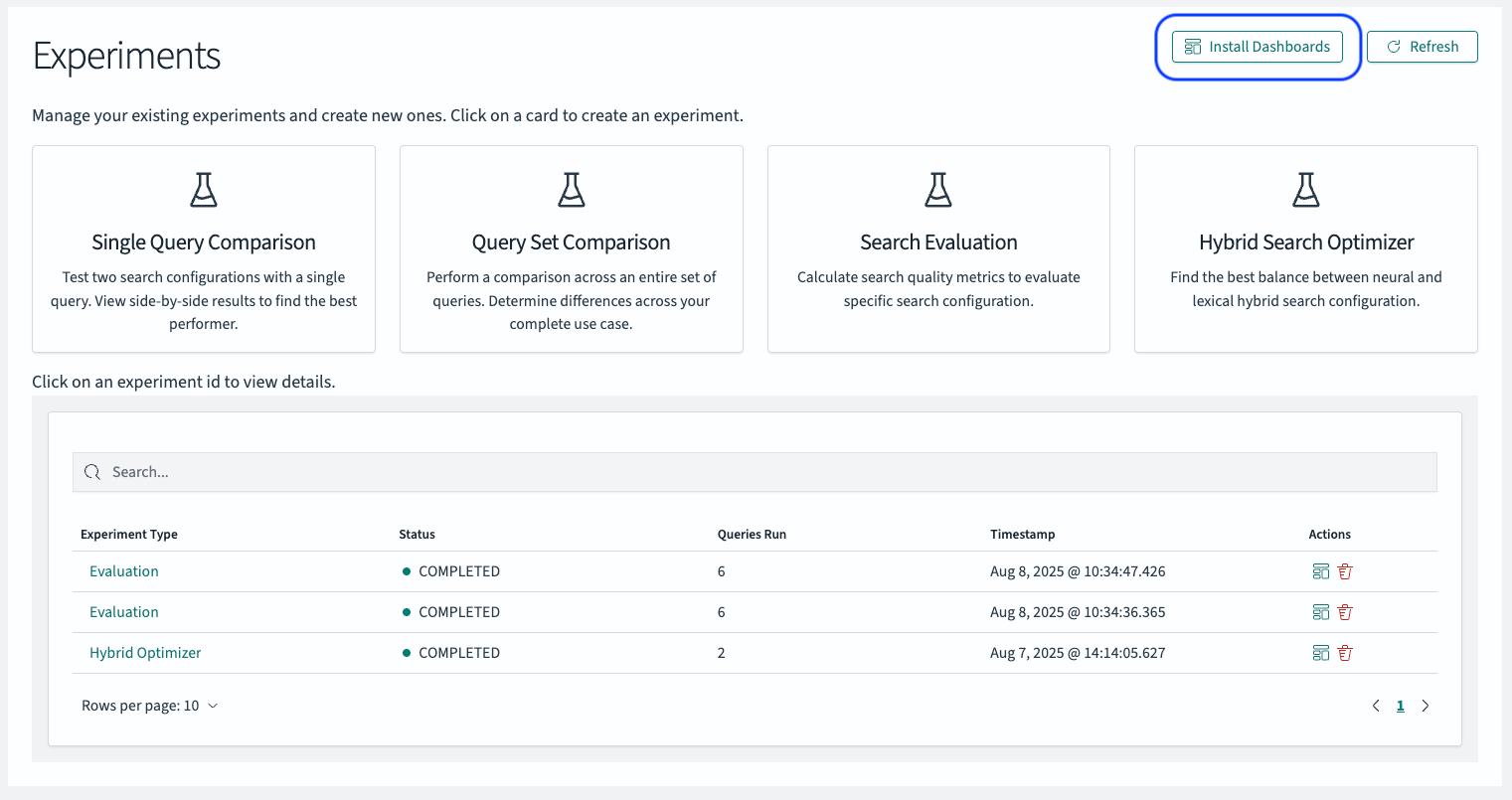 After confirming the installation in the modal that appears, the dashboards will be available for you to explore.
After confirming the installation in the modal that appears, the dashboards will be available for you to explore.
After successfully installing the dashboards, you can select the visualization icon in the experiment overview table to explore the results of the experiment you’re interested in. The icon is located in the row of the specific experiment you wish to view and is marked in blue in the screenshot.
This will open the experiment’s dashboard, providing a comprehensive overview of its details and results.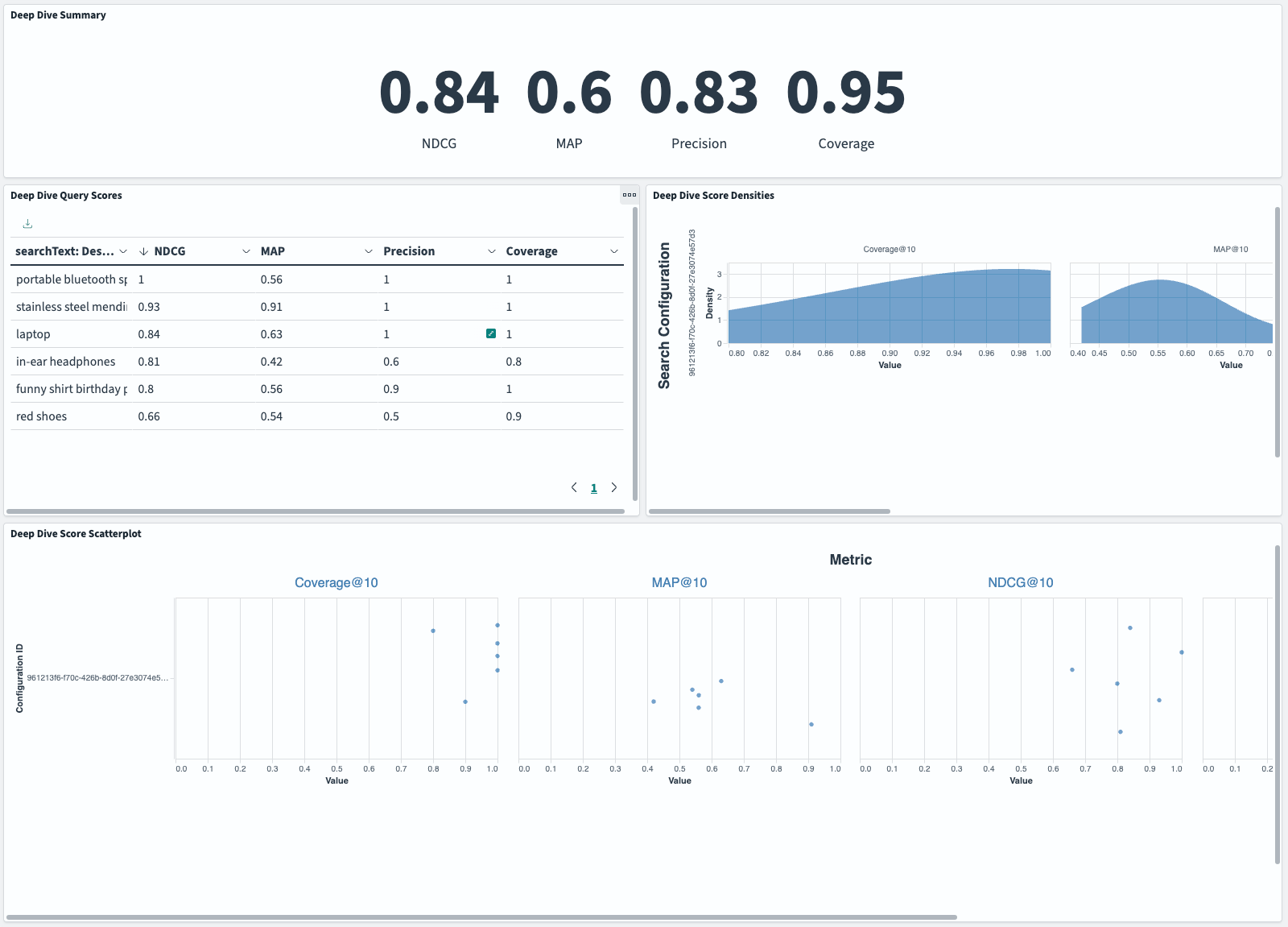
The dashboard provides four visualizations to help you analyze your experiment results:
- Deep Dive Summary: This pane shows the aggregate metrics for NDCG, MAP, Precision, and Coverage, which are identical to the numbers on the Experiment details page.
- Deep Dive Query Scores: This visualization ranks individual query performance by NDCG score (from highest to lowest), helping you quickly identify your best- and worst-performing queries.
- Deep Dive Score Densities: Use this pane to understand how metric values are distributed across your query set. The x-axis shows the metric values, while the y-axis shows their frequency, helping you determine if poor performance is widespread or concentrated.
- Deep Dive Score Scatterplot: This interactive view shows the same distribution data as the Score Densities pane, with each query represented as a separate point. Use it to investigate specific queries at performance extremes. Points are scattered vertically to prevent overlap while maintaining the same x-axis metric values.
These dashboards are extremely helpful for pinpointing outliers and understanding the distribution of search metrics resulting from an experiment.
From offline to online experiments
Returning to the experiment, the very few decreased search metrics appear acceptable, especially since all other metrics at the individual query level have increased. By analyzing search quality metrics from offline experiments on a six-query set, you can now be confident that switching from a purely keyword-based search strategy to a hybrid one has the potential to increase search result quality for your end users.
Congratulations! You have successfully performed an offline search quality evaluation to compare the performance of two search configurations.
To validate this hypothesis, the next logical step would be an online experiment, where you expose hybrid search to a segment of your user traffic. A/B testing is on the roadmap for the Search Relevance Workbench in the form of online testing with team draft interleaving. You can join the discussion on GitHub to share your thoughts on team draft interleaving support.
Building your judgment list: Practical tips
As this blog post has shown, measuring search quality requires three key components: a query set, a search configuration, and a judgment list. The most challenging of these to create is often the judgment list, so here are some practical tips to help you get started.
Explicit judgments
Whether you use humans or LLMs to create a judgment list, a high-quality list relies on following these guidelines:
- Define a clear task: Provide your judges with a clear and concise task definition. Give them as much information as possible on how to rate query-document pairs to reduce the inherent subjectivity of this activity.
- Minimize biases: Use tools or design frameworks that minimize the influence of biases. Tools for collecting human or LLM ratings, such as Quepid, can help mitigate common biases. When designing your own judgment collection process, be sure to actively counter known biases.
- Measure agreement: Use different methods to collect judgments and measure the agreement among them. It’s unlikely that two different judges will agree 100% of the time. Examining cases where judges agree and disagree can provide additional insights on how to refine your task definition for better alignment and clarity.
We encourage you to explore the LLM-assisted judgment list creation feature in the Search Relevance Workbench. Review the resulting judgments to see how well they match your intuition and expectations. LLMs as judges is an area of active research, and you can expect to see more developments in this space in the near future.
Implicit judgments
The quality of implicit judgments depends heavily on the collected behavioral data and the underlying model used to map that data to judgments. To ensure a high-quality judgment list, follow these tips:
- Collect the right information. At a minimum, you should collect the documents users viewed and the interactions that followed (for example, clicks, add-to-basket), along with their positional information. More contextual data, such as device type or login status, can help debias the judgments. Open standards like UBI can help with this.
- Understand your click model. Behavioral data often contains biases like position and presentation bias. It is crucial to understand how your chosen click model and its implementation debias the data.
- Explore implicit judgments in the Search Relevance Workbench. If you have user behavior data that adheres to the UBI standard, you can use the workbench’s implemented Clicks over Expected Clicks model to calculate implicit judgments.
General tip for all judgment lists
A best practice for all judgment lists is to test them online. Sort the results of a few queries according to the judgments in your list and observe the outcome. This is especially useful for implicit judgments, which use a continuous scale. It can also help uncover issues in explicit judgments if user feedback disagrees with your judges.
Conclusion
Using the Search Relevance Workbench, we have progressed from simple change detection to a systematic, metric-driven approach for evaluating search quality. This process—which uses query sets, judgment lists, and offline experiments—provides a robust foundation for making informed decisions about your search configurations.
In the next and final post of this three-part series, we’ll discuss how to set up complex experiments within the search relevance optimization lifecycle and how the workbench can assist you.
We encourage you to adapt this methodology for your own search platform and look forward to your feedback on the Search Relevance Workbench toolset on the OpenSearch forum.
