

OpenSearch 3.3 is available for download, with a number of new features designed to help your search, observability, and AI-powered applications. This release delivers an array of upgrades across use cases, including a significant expansion of the observability toolkit and new functionality to make agentic AI integrations simpler and more powerful.
Observability
With this release, OpenSearch delivers its most capable, comprehensive, and user-friendly observability offering yet. Dramatic enhancements to query functionality and visualization tools can help you build more robust and efficient observability pipelines and discover more from your logs, metrics, and trace data.
Explore a new Discover observability experience
This release brings a preview version of a completely redesigned OpenSearch Dashboards interface. Expected to become the default view with the 3.4 release, the new interface brings log analytics, distributed tracing, and intelligent visualizations into a single user experience. Users gain the ability to analyze and correlate observability data in an application that features auto-visualizations, context-aware log and trace analysis, and AI-powered query construction. This release also expands the available chart types, offering more visualization options for your data. To activate the new Dashboards experience, refer to the directions provided here.
Automate chart selection in OpenSearch Dashboards
The new Discover experience also delivers columnar query results and recommends the most appropriate visualization. For example, one metric with a date column defaults to a line chart for time series analysis, while two categorical columns with high cardinality automatically triggers a heatmap. Each rule provides alternative chart types ranked by priority, giving you flexibility to switch visualizations.
Additional customization options include axis labels and ranges, thresholds for data alerts, configuring titles and tooltips, adjusting color schemes, and modifying visual styles. 12 preset rules cover common data patterns, from simple metric displays to complex multi-dimensional scatter plots. The architecture lets you use custom rules and chart types with just a few lines of code. The following is an observability visualization showing the volume of log data for each service in the stack over a user-defined time period.
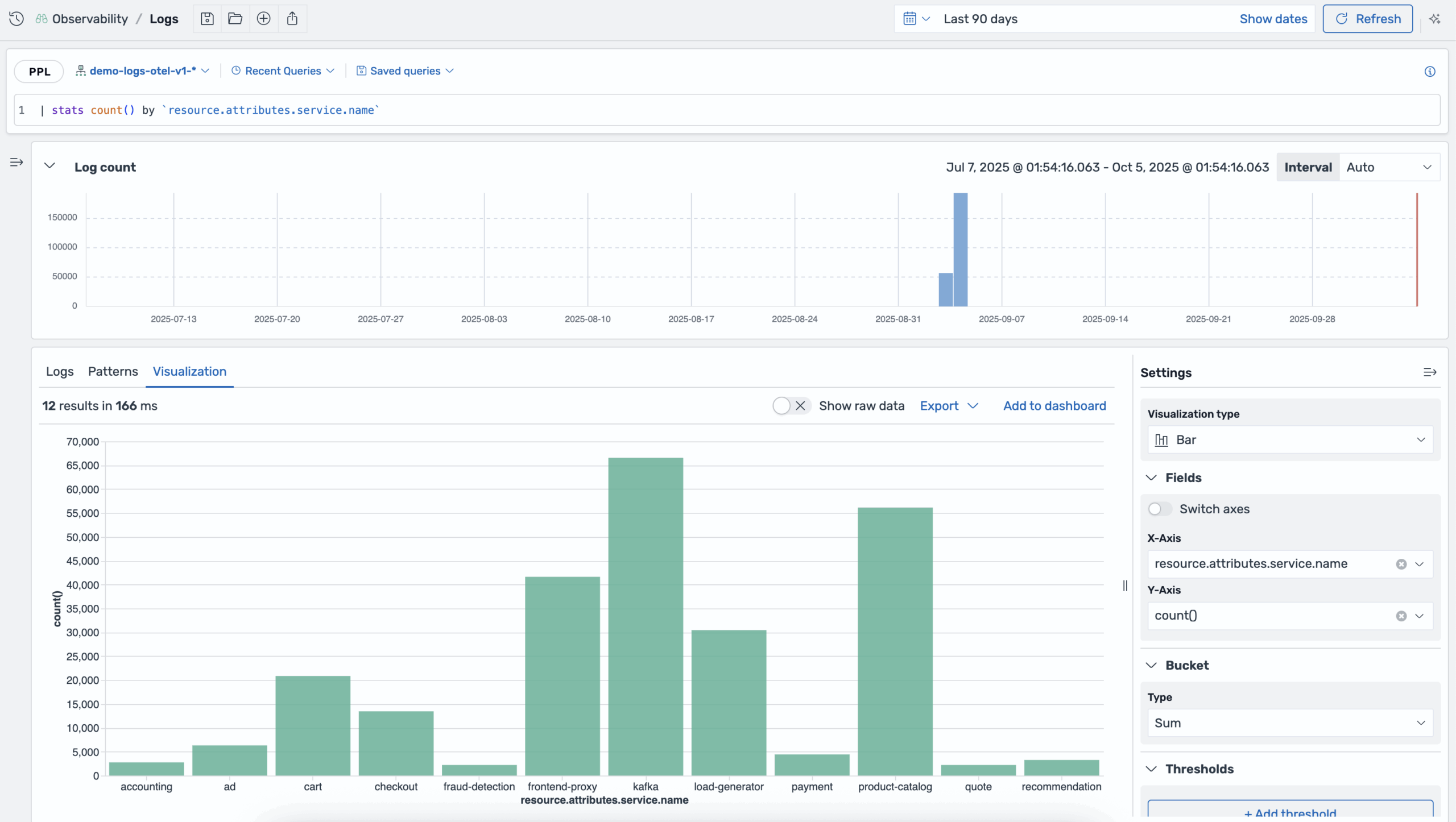
Query trace data with Discover Traces
Built on the Discover interface and new in 3.3, Discover Traces provides a central interface for querying and exploring traces across large distributed systems. Traces includes a click-to-filter interface, allowing construction of complex Piped Processing Language (PPL) queries without having to write them. When a trace requires deeper investigation, a new trace details page reveals individual trace journeys, displaying complete metadata, attributes, and execution context for that specific operation. To activate this functionality, refer to the step-by-step guide here.
Explore interactive node-based visualizations with React Flow
This release adds the React Flow library to OpenSearch Dashboards core as an experimental feature, providing a standardized framework for interactive node-based visualizations. This integration eliminates version conflicts that occurred when individual plugins bundled copies of the library, providing a consistent user experience. The library is currently being used with the Discover Traces feature to render service maps that visualize trace spans and service dependencies. Unlike traditional charting libraries, React Flow specializes in workflow and network diagrams, offering drag-and-drop interactions, custom node components, and efficient rendering of thousands of nodes while maintaining accessibility compliance. To activate this functionality, refer to the step-by-step guide here. The following is an example of an interactive node-based visualization.
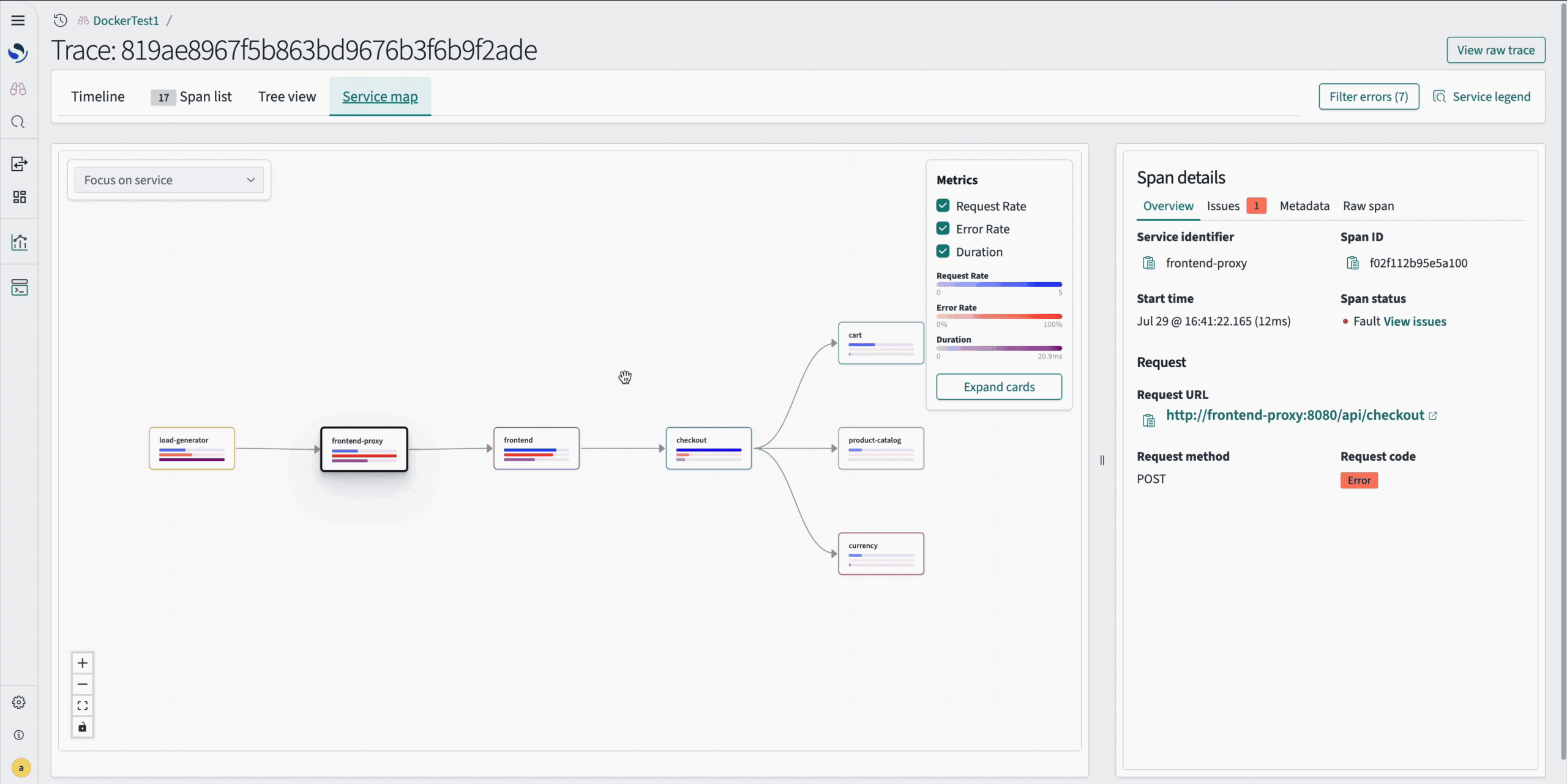 Use powerful new PPL functions with Apache Calcite compatibility
Use powerful new PPL functions with Apache Calcite compatibility
Apache Calcite has become the default query engine for PPL in OpenSearch 3.3, introducing better portability for a wide range of data management systems. Calcite’s mature framework provides new optimization capabilities, improvements to query processing efficiency, and an extensive library of new PPL commands.
Evaluate and benchmark PPL query performance
OpenSearch 3.3 introduces comprehensive benchmarking infrastructure to validate PPL’s performance capabilities. The ClickBench and Big5 datasets support standardized performance testing across a range of analytical scenarios. Automated nightly benchmark runs provide continuous performance monitoring, and public dashboards offer transparency into PPL query performance. Visit the benchmarks page to learn more.
Process unstructured log data at query time
This release adds text processing capabilities to PPL, with new commands for filtering, extracting, and parsing unstructured text directly without requiring data preprocessing. The regex command provides pattern-based filtering to isolate relevant log entries, while rex extracts structured fields from raw text using regular expressions. The spath command extracts fields from JSON data, enabling access to nested objects and arrays. Together, these commands allow you to immediately analyze unstructured data. Additionally, wildcard support in the fields, table, and rename commands allows bulk operations on similarly named fields.
Analyze time-series data and distributions with simple commands
OpenSearch 3.3 introduces new timechart and bin commands. The timechart command aggregates data over time intervals with flexible span controls, and the bin command automatically groups numeric data into ranges or buckets. Temporal pattern analysis and data distribution modeling are more accessible within PPL queries, allowing users to identify trends and outliers directly through query operations.
Perform sophisticated statistical analysis with new functions
OpenSearch 3.3 expands PPL’s analytical power with new statistical functions for deeper data analysis:
- The
earliestandlatestfunctions retrieve timestamp-based values, finding the earliest or latest occurrence of values within a dataset. - New multi-value statistical functions
listandvaluescollect multiple values into structured arrays during aggregation operations, withlistpreserving duplicates whilevaluesreturns unique values. These functions preserve relationships between grouped data points, enabling advanced analysis workflows that require maintaining collections of related values. - The
maxandminaggregate functions now support non-numeric data types for broader comparison operations.
Deploy new evaluation functions for complex data transformations
OpenSearch 3.3 introduces new evaluation functions for data transformation purposes:
- The enhanced
coalescefunction handles null values across mixed data types, providing flexible fallback logic for data cleaning operations. - The
mvjoinfunction combines multi-value fields into single strings using specified delimiters, enabling array manipulation within queries. - The
sum,avg,max, andminmathematical functions enable row-level calculations and comparisons across multiple values or fields. regex_matchis used for pattern matching operations andstrftimefor timestamp formatting. These functions enable complex data transformations directly within PPL expressions without requiring external processing steps.
Combine and reshape datasets within single queries
This release enhances PPL’s data manipulation capabilities with new commands for flexible data combination and field operations. The append command combines results from multiple queries into a unified dataset, enabling you to merge data from different sources or time ranges within a single operation, while the join command allows you to take actions like joining authentication and application logs to investigate security incidents . These capabilities enable comprehensive data analysis workflows within single PPL queries.
Uncover insights with experimental AI-powered Discover tools
This release brings experimental AI capabilities to OpenSearch Dashboards that can transform how users interact with their data through intelligent context awareness, conversational interfaces, and agent integration. Three new AI features are available to explore: the Context Provider plugin for automatic context capture, the OSD-Agents package with a reference AI agent, and an enhanced Chat UI that creates an intelligent assistant experience on the Discover page. When you interact with the chat interface, it automatically understands your current page context—selected traces, filtered logs, time ranges—and can execute actions like updating queries and creating visualizations based on conversational requests. The system ships with a reference React-based LangGraph agent and supports integration with specialized agents like HolmesGPT for advanced root cause analysis. To learn how to enable these tools for HolmesGPT, refer to this setup guide.
Vector search and generative AI
OpenSearch 3.3 brings to production an array of vector search enhancements to support more sophisticated and performant generative AI applications.
Retrieve optimized search results with agentic search
OpenSearch 3.3 brings the general availability of agentic search, allowing you to interact with your data though natural language inputs. Agentic search leverages intelligent agents to automatically select the right tools and generate optimized queries based on user intent. This agentic search functionality maintains context across queries to support multi-turn conversations and gives users the option to use custom search templates, where agents intelligently select and populate the most appropriate template based on query context. You can also expand your search beyond your OpenSearch cluster with seamless connectivity to external Model Context Protocol (MCP) servers. With agentic search, users can achieve precise search results without the need to construct complex query domain-specific language (DSL) queries.
Build context-aware interactions with persistent agentic memory
Introduced as experimental in OpenSearch 3.2, this release includes production-ready agentic memory, a persistent memory system that enables AI agents to learn, remember, and reason across conversations and interactions. This feature provides comprehensive memory management through multiple strategies, including semantic fact extraction, user preference learning, and conversation summarization, allowing agents to maintain context and build knowledge over time and enabling sophisticated memory operations, such as consolidation, retrieval, and history tracking. By providing agents with persistent, searchable memory, this feature transforms static AI interactions into dynamic, context-aware experiences that improve over time, enabling more personalized and intelligent responses while maintaining control over memory organization and retention policies.
Accelerate neural sparse search up to 100x
OpenSearch 3.3 incorporates Seismic, a groundbreaking sparse retrieval algorithm that promises to revolutionize neural sparse search performance. Seismic delivers exceptional search latency improvements—up to 100x faster than traditional methods—while maintaining over 90% recall accuracy. Unlike approaches that can slow dramatically with scale, Seismic improves scalability as collections grow from millions to billions of documents and can outperform traditional BM25 queries for large-scale deployments. The algorithm intelligently balances precision and speed through multi-level pruning techniques, delivering search latencies under 15 ms for a 50-million document collection to enable higher query throughput with fewer resources, support larger sparse vector corpora, and allow real-time applications that were previously unattainable with sparse embeddings.
Build flexible data transformation pipelines with processor chains
OpenSearch 3.3 introduces processor chains, a powerful new feature that enables flexible data transformation pipelines within artificial intelligence and machine learning (AI/ML) workflows. Processor chains allow you to sequentially transform data by chaining together multiple processors so that each processor’s output becomes the next processor’s input. This capability is particularly valuable for cleaning model responses, extracting structured data from large language model (LLM) outputs, and preparing inputs for model inference. With support for 10 processor types, including JSONPath filtering, regex operations, conditional logic, and array iteration, you can transform data formats, extract specific information, and standardize outputs without external tools. Processor chains can be configured on both model inputs and outputs during prediction calls, as well as on agent tool outputs, for seamless integration into your AI/ML pipelines and cleaner, more actionable results from search and ML applications.
Streamline MCP server access with streamable HTTP transport
OpenSearch 3.3 upgrades the ML Commons MCP server from Server-Sent Events (SSE) to the Streamable HTTP transport protocol. The MCP server exposes OpenSearch tools for agent discovery and invocation, with built-in authorization handling that ensures responses vary based on user permissions through OpenSearch’s role-based access control (RBAC). This release also introduces MCP Connector support for Streamable HTTP clients, enabling ML Commons agents to connect to external MCP servers and utilize their tools with simplified connection management and automatic authorization handling.
Improve semantic highlighting performance with batch inference support
OpenSearch 3.3 introduces batch processing for remote semantic highlighting models, improving performance by reducing ML inference calls. Previously, semantic highlighting made one inference call per search result. With batch processing, all results are sent in a single batched call, reducing overhead and improving GPU utilization. Benchmarks show performance improvements ranging from 2x to 14x depending on workload characteristics, with the best results for queries returning many short documents. Enable batch processing by adding batch_inference: true to your search queries. The feature is backward compatible and supports remote models deployed on Amazon SageMaker or external endpoints.
Enhance vector search precision with late interaction scores
OpenSearch 3.3 introduces the lateInteractionScore function, a rescoring feature that enhances single-vector search with multi-vector precision. This function implements ColBERT’s late interaction mechanism, allowing you to perform initial retrieval with traditional single vectors, then rescore results using token-level matching between query and document embeddings. This function enhances multimodal applications, enabling text queries to rescore against image patches or visual features while preserving semantic granularity. Each query token finds its optimal match among document vectors, providing interpretable cross-modal retrieval and fine-grained alignment between modalities. This two-stage approach combines the efficiency of single-vector search with the precision of multi-vector rescoring.
Achieve real-time data processing with remote model inference streaming
OpenSearch 3.3 introduces experimental streaming support for both model prediction and agent execution, offering a significant advancement in how users interact with AI models and agents. This streaming feature introduces real-time data streaming capabilities through SSE, delivering data in chunks as it becomes available. This streaming approach is particularly beneficial for LLM interactions with lengthy responses, allowing users to see partial results immediately rather than waiting for the complete response.
Search
This release also delivers a number of new features to improve search results and advance performance and scalability.
Enhance search results with Maximal Marginal Relevance
OpenSearch 3.3 introduces native Maximal Marginal Relevance (MMR) support, offering search results that blend relevance and diversity. MMR intelligently balances between retrieving the most relevant information and reducing redundancy, ensuring users see a broader range of answers without impacting quality. This is particularly valuable for semantic search, recommendation systems, and knowledge bases, where repeated or overly similar results can limit discovery. With native integration, MMR works within OpenSearch queries and pipelines, requiring no external tools or configurations. By automatically promoting variety in search results while maintaining relevance, this feature helps deliver richer, more meaningful search results and improved user experiences.
Accelerate multi-terms aggregations with star-tree support
OpenSearch 3.3 now supports multi-terms aggregations to be resolved via star-tree. Multi-terms aggregations are among the slowest-running aggregations, particularly when applied to large datasets. Now, star-tree can help speed up multi-terms aggregations for large datasets, and users can now also see query failures, with newly introduced failure statistics included as part of index/node/shard-level statistics.
Enhance hybrid query performance with new tools
OpenSearch 3.3 delivers performance optimizations when executing hybrid search queries with the implementation of QueryCollectorContextSpec. This function directly injects QueryCollectorContext in the search process, which removes some boilerplate code for more efficient search execution. Benchmarks show performance improvement of up to 20% for hybrid search with lexical subqueries, with up to 5% improvement for searches with lexical and semantic subqueries.
Explore high-performance data streaming with Apache Arrow Flight
This release includes a new, experimental streaming-capable transport layer that unlocks new paths for high-performance data streaming within clusters. Built on the Apache Arrow Flight RPC protocol, this opt-in feature enables server-side streaming for node-to-node communication, allowing transport actions to stream multiple responses over a single connection—ideal for large result sets, real-time data feeds, and progressive query results. The implementation includes a new StreamTransportService API with intuitive sendResponseBatch() and completeStream() methods, enabling plugins to add custom streaming transport actions as demonstrated in the stream-transport-example plugin, along with full security integration with TLS encryption. Currently available for internal cluster communication only (no REST client support yet), developers can try it by installing the arrow-flight-rpc plugin and enabling the opensearch.experimental.feature.transport.stream.enabled flag. Explore the documentation covering architecture, security setup, and metrics monitoring.
Gain efficiency for high-cardinality aggregations with new streaming functionality
New experimental streaming aggregations shift the processing model for high-cardinality aggregations by streaming partial results per Lucene segment rather than building complete state per shard. This moves workload from data nodes to coordinators, making coordinators the scalable point for high-cardinality scenarios where data node resources are constrained. Supporting terms aggregations (keyword and numeric fields) with metric sub-aggregations (max, min, doc_count, cardinality), the implementation uses precomputed segment-level ordinals instead of expensive global ordinals, eliminating costly TopN priority queue operations and achieving significant memory and CPU reduction on data nodes. You can enable this functionality by installing the arrow-flight-rpc plugin, setting opensearch.experimental.feature.transport.stream.enabled=true, and the cluster setting stream.search.enabled=true. This functionality was recently previewed in a presentation at OpenSearchCon North America.
Cost, performance, and scalability
This release includes updates that help you improve the cost, performance, and scalability of your OpenSearch clusters.
Explore high-performance data transport with expanded gRPC support
OpenSearch 3.3 expands Search API support for gRPC transport across the most popular query types in OpenSearch. Term-level queries now have access to Range, Terms set, Exists, and IDs as well as Wildcard and Regexp operations. Full-text searches can take advantage of Match Phrase and Multi-Match query types while geographic searches benefit from GeoBoundingBox and GeoDistance support. Boolean, script, and nested queries round out expanded Search API support this release, bringing gRPC transport search capabilities one step closer to the REST API. You can find OpenSearch protobufs Python libraries published to PyPI, enabling convenient onboarding of your Python applications to gRPC, with OpenSearch Benchmark support also included in this release.
Optimize the FieldDataCache removal flow
Field data cache clearing is both asynchronous and more efficient in OpenSearch 3.3. This operation now consumes time proportional to the number of keys rather than to the number of keys multiplied by the number of fields. This prevents node drop issues caused by slow cache cleanup on domains using more fields than is recommended. A similar change also improves the efficiency of clearing the request cache, particularly when the disk cache is used. Relatedly, this release changes the default settings for the field data cache size to allow normal cache eviction to occur when the cache is filled rather than undesirable and confusing circuit-breaking behavior on subsequent requests.
Stability, availability, and resiliency
OpenSearch 3.3 also delivers functionality that helps you maintain the stability, availability, and resiliency of your OpenSearch deployments.
Monitor and analyze queries by workload group
OpenSearch 3.3 enhances the Query Insights Dashboard with integrated Workload Management (WLM) capabilities, enabling cluster administrators to monitor and analyze live queries by workload group. This integration introduces a new WLM Group column in the live queries table and provides bi-directional navigation between the Query Insights and WLM dashboards. Users can now filter active queries by workload group and view workload-specific metrics, including CPU usage, memory consumption, and elapsed time. When WLM is enabled, administrators can seamlessly navigate from query details to workload group configurations and back, streamlining workload-specific query analysis. This helps administrators quickly identify performance issues, optimize resource allocation, and troubleshoot queries within specific workload contexts without switching between multiple interfaces. The feature maintains backward compatibility for environments where WLM is not installed.
Simplify workload management with rule-based auto-tagging
Rule-based auto-tagging automatically labels incoming requests based on defined rules, helping administrators manage workloads and monitor cluster activity. Previously, rules could only be applied using index patterns, limiting the system’s ability to differentiate requests that share similar indexes but originate from different users or roles. The new principal attributes feature addresses this gap by allowing rules to leverage attributes such as username and role, in addition to index patterns. This enables more precise, context-aware tagging, allowing clusters to prioritize critical workloads, enforce policies, and reduce resource contention. Rules are evaluated using a priority-based mechanism, ensuring the most specific match is applied. This enhancement improves workload balancing, visibility, and control while laying the foundation for future multi-dimensional tagging capabilities in OpenSearch.
Getting started
You can find the latest version of OpenSearch on our downloads page or check out the visualization tools on OpenSearch Playground. For more information, visit the release notes, documentation release notes, and updated documentation. If you’re exploring a migration to OpenSearch from another software provider, we offer tools and documentation designed to guide you through the process, available here.
Feel free to visit our community forum to share your valuable feedback on this release and connect with other OpenSearch users on our Slack instance.

