
The open platform for AI-powered enterprise search
Retrieval, reasoning, and answers from the data you already have.
Enterprise data is growing faster than any team’s ability to find and use it. An estimated 80% of that data is unstructured—scattered across documents, emails, wikis, code repositories, collaboration tools, and ticket systems that legacy keyword search methods were never designed to handle. The organizations that can unlock this data gain a decisive edge in speed, decision-making, and institutional knowledge.
OpenSearch brings AI-powered search to your enterprise data, compressing decision cycles, reducing operational risk, and turning institutional knowledge into a measurable competitive advantage.


Modernizing Search: An Enterprise Guide to AI-Powered Information Retrieval
Your search infrastructure wasn’t built for AI. This guide is.
Built for how modern enterprises work
Recent advances in large language models (LLMs) and vector search have fundamentally changed what’s possible. Search no longer has to mean typing keywords and scanning result lists. Modern enterprise search understands intent, reasons across sources, and delivers synthesized knowledge grounded in your organization’s own data.
About OpenSearch
OpenSearch is a unified, open-source platform that supports the full search modernization continuum. Start with hybrid retrieval that combines keyword precision with semantic understanding. Layer in retrieval-augmented generation (RAG) to connect your data to LLMs and return contextual, plain-language answers. Then extend into agentic workflows where the system plans, reasons, and iteratively retrieves across multiple systems to handle complex, multi-step questions.
Each stage builds on the last—and OpenSearch supports all of them within a single, extensible platform with no vendor lock-in.
Download GigaOm Radar for Vector Databases
OpenSearch named a Leader and Fast Mover in the GigaOm Radar for Vector Databases report.
GigaOm report
GigaOm report 
Download 451 Research Special Report
451 Research special report on enterprise search, produced by S&P Global for the Linux Foundation.
451 RESEARCH REPORT
451 RESEARCH REPORT Under the hood: How OpenSearch delivers answers
Retrieval-augmented generation connects OpenSearch retrieval to LLMs
When a user asks a question, the system finds the most relevant content across your data, then uses an LLM to synthesize a clear, grounded answer—turning search from a list of documents into a knowledge delivery system.
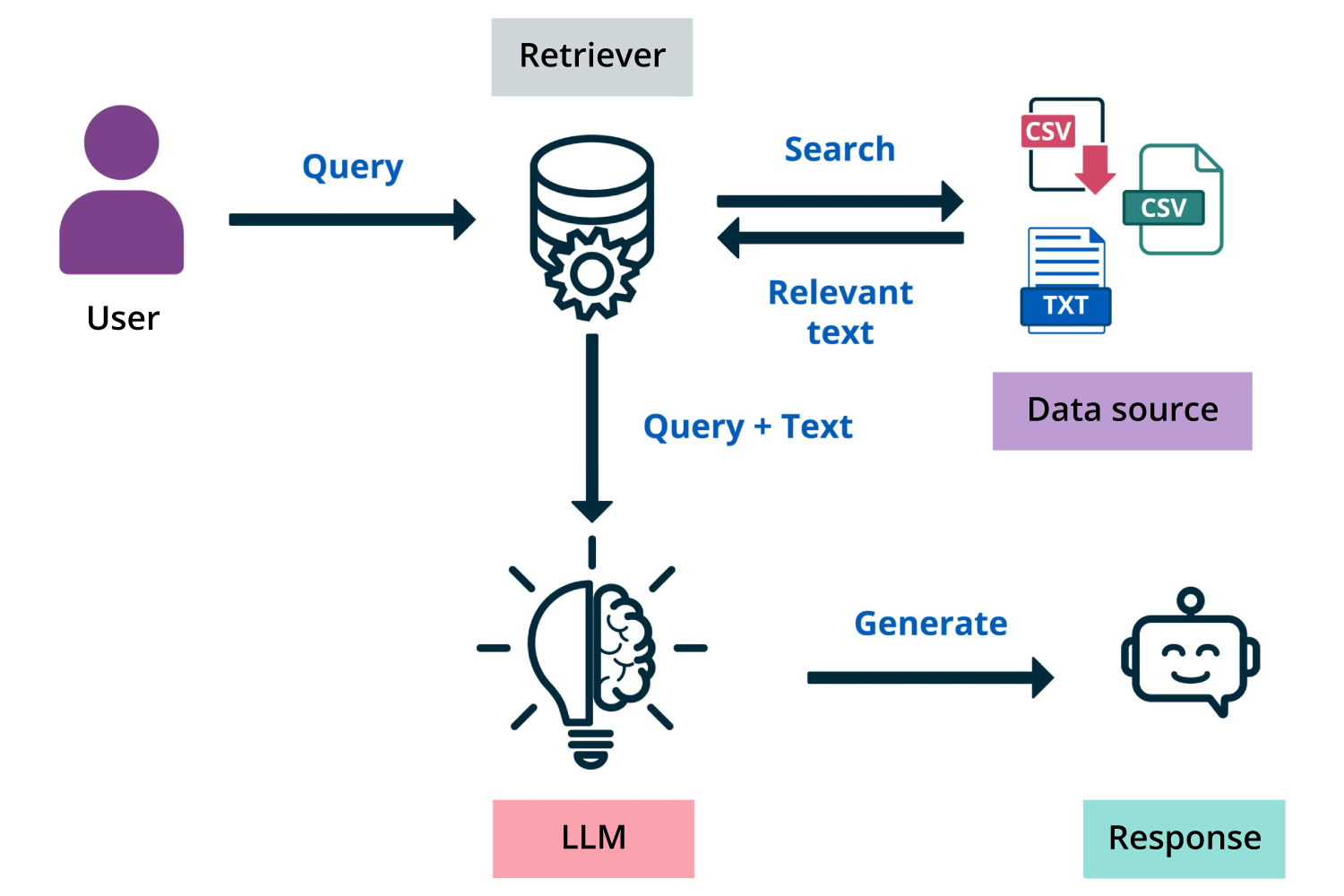
RAG connects OpenSearch retrieval to LLMs, generating synthesized answers grounded in enterprise data.
Agentic workflows go further
Instead of a single query-and-respond cycle, agentic systems plan what information they need, retrieve in stages, refine their approach as new context emerges, and synthesize across multiple data sources and tools. This makes it possible to answer questions that span departments, systems, and document types—questions that no single query could resolve.

Agentic workflows extend RAG with multi-step reasoning, planning, and iterative retrieval across data sources and tools.
Why AI-powered search is a strategic investment

The business case for modernizing enterprise search extends well beyond faster document retrieval. When search understands intent, reasons across systems, and delivers synthesized answers, the impact is measurable across the organization.
Faster decisions: Senior teams spend less time hunting for context across disconnected systems. Hours of research compress into minutes of synthesis.
Lower operational risk. Complex questions receive thorough, consistent answers with complete audit trails, rather than depending on whoever happens to remember the right policy or procedure.
Competitive separation. In knowledge-intensive work, speed and accuracy compound over time. Organizations that act on institutional knowledge faster than their competitors build advantages that are difficult to replicate.
OpenSearch is Apache 2.0 licensed, giving your organization full control over architecture, data residency, and the pace of adoption — with no vendor lock-in.
Key features
Hybrid search
Combine BM25 keyword matching with vector-based semantic search in a single query for high precision and broad recall across structured and unstructured data.
Learn more
Learn more RAG integration
Connect OpenSearch retrieval to LLMs using built-in RAG pipelines that generate synthesized, plain-language answers grounded in authoritative enterprise sources.
Learn more
Learn more Agentic workflows
Build multi-step search workflows that plan, reason, and iteratively retrieve across data sources, formats, and organizational boundaries — enabling use cases like compliance synthesis and cross-system incident response.
Learn more
Learn more Search relevance and explainability
Evaluate and improve search quality with the Search Relevance Workbench, the Explain API for scoring transparency, and side-by-side result comparison tools.
Learn more
Learn more Flexible deployment
Deploy on-premises, in any cloud, or in hybrid configurations with full control over architecture, data residency, and upgrade timing. Apache 2.0 licensed.
Learn more
Learn more Security and access control
Enforce document-level and field-level permissions at the retrieval layer, not the UI, so unauthorized content is excluded before it reaches ranking algorithms or generative models. Supports GDPR and HIPAA compliance with audit logging and access governance.
Learn more
Learn more Scalable vector engine
Store and query billions of vectors with low latency and high availability. Supports approximate k-NN, exact search, and multiple distance functions for production-grade semantic search.
Learn more
Learn more Open and extensible
Integrate with LLMs and embedding models hosted on Amazon Bedrock, Amazon SageMaker, OpenAI, Cohere, DeepSeek, and other platforms through the ML Commons connector framework.
Learn more
Learn more Where enterprise search delivers impact
Enterprise data holds more institutional knowledge than most teams can easily reach. The following use cases represent proven starting points where AI-powered search drives measurable outcomes from data that’s already in your systems.
Use cases
Description
Compliance and policy discovery
Find relevant policies, regulations, and audit records across jurisdictions with full traceability for regulatory reporting. Supports compliance workflows under GDPR, HIPAA, and industry-specific frameworks with consistent access controls and auditable decision trails.
Customer support resolution
Retrieve relevant knowledge articles, case histories, and troubleshooting guides in real time to reduce response times and improve resolution rates.
Data access governance
Enforce fine-grained permissions at the retrieval layer to prevent unauthorized data exposure in AI-generated responses. Maintain audit trails across the full search and generation pipeline to support regulatory reporting and zero-trust security requirements.
Employee knowledge assistants
Give employees fast, accurate answers from wikis, collaboration tools, and document repositories; reducing time spent searching and eliminating duplicate work across teams.
Engineering and code search
Navigate large codebases, APIs, and documentation with semantic understanding. Locate relevant code examples, runbooks, and prior incident reports without knowing the exact file or keyword.
Incident response and observability
Trace similar past incidents, retrieve recent change history, and identify contributing factors across monitoring systems, ticket histories, and code repositories before the on-call engineer finishes reading the initial alert.
M&A due diligence
Synthesize insights across the legal agreements, financial statements, and operational data associated with mergers and acquisitions (M&A) under compressed timelines using agentic search workflows.
Search relevance and experimentation
Compare retrieval configurations side by side, evaluate ranking quality across query sets, and iterate on embedding models and hybrid search pipelines using built-in relevance tooling and the Explain API.
Getting started
OpenSearch enterprise search capabilities are available today. Start building with these resources:
Configure hybrid search, neural search, and conversational search
Search plugins documentation
Search plugins documentation Related resources on OpenSearch.org

Machine learning and AI
Build flexible, scalable, and future-ready machine learning and artificial intelligence applications
Learn more 
OpenSearch Vector Engine
An open-source, all-in-one vector database for building scalable and future-proof AI apps
Learn more 
Document Search
Unify your documents and empower teams with fast, intelligent search
Learn more 
Search Relevance
Bridge the gap between your users’ intent and their search results
Learn more