

In OpenSearch 3.1, we introduced memory-optimized search to enable vector search in memory-constrained environments. However, 16-bit floating point (FP16) vector processing remained a performance bottleneck. Over the next two releases, we progressively optimized FP16 distance calculations—first with SIMD in OpenSearch 3.4, then with bulk SIMD in OpenSearch 3.5, achieving up to 310% throughput improvement and dramatically reducing latency. This blog post presents the details of our optimization journey and the techniques that made these performance gains possible.
Optimizing FP16 performance
We improved FP16 performance through a series of optimizations: introducing memory-optimized search in OpenSearch 3.1, implementing SIMD distance calculations in 3.4, and adding bulk SIMD processing in 3.5.
OpenSearch 3.1: Memory-optimized search
In OpenSearch 3.1, we introduced memory-optimized search, enabling the use of Faiss indexes in environments with tight memory constraints, where available memory is smaller than the index size. This was achieved by combining Lucene’s search algorithm with a Faiss index. Thanks to Lucene’s early termination optimization, almost all vector types—except FP16—showed improved search QPS in multi-segment scenarios when the index was fully loaded in memory.
FP16 presented a bigger challenge. Conversion from FP16 to FP32 was performed in Java, meaning that even if a CPU could handle FP16-to-FP32 conversion in hardware, the JVM relied on a software-based conversion instead. Because the JVM lacks native FP16 support, FP16 vectors had to be encoded to FP32 before performing distance calculations.
This became a major performance bottleneck: searches using FP16 were nearly twice as slow compared to the default implementation.
OpenSearch 3.4: SIMD FP16 distance calculation
In OpenSearch 3.4, we addressed the FP16 performance limitation by intercepting the distance calculation and delegating it to C++ SIMD. From an implementation perspective, we leveraged the optimized SIMD code already provided by the Faiss library, which simplified the implementation.
Faiss SIMD uses SIMD registers to encode multiple FP16 values into FP32 and then performs operations on them simultaneously. This approach applies SIMD between a query and a single vector, significantly speeding up distance computations compared to the software-based calculations used in OpenSearch 3.1.
The following diagram illustrates the inner product computation using SIMD. It processes four dimensions of a vector simultaneously using a loop-unrolling technique, which optimizes and accelerates the computations.
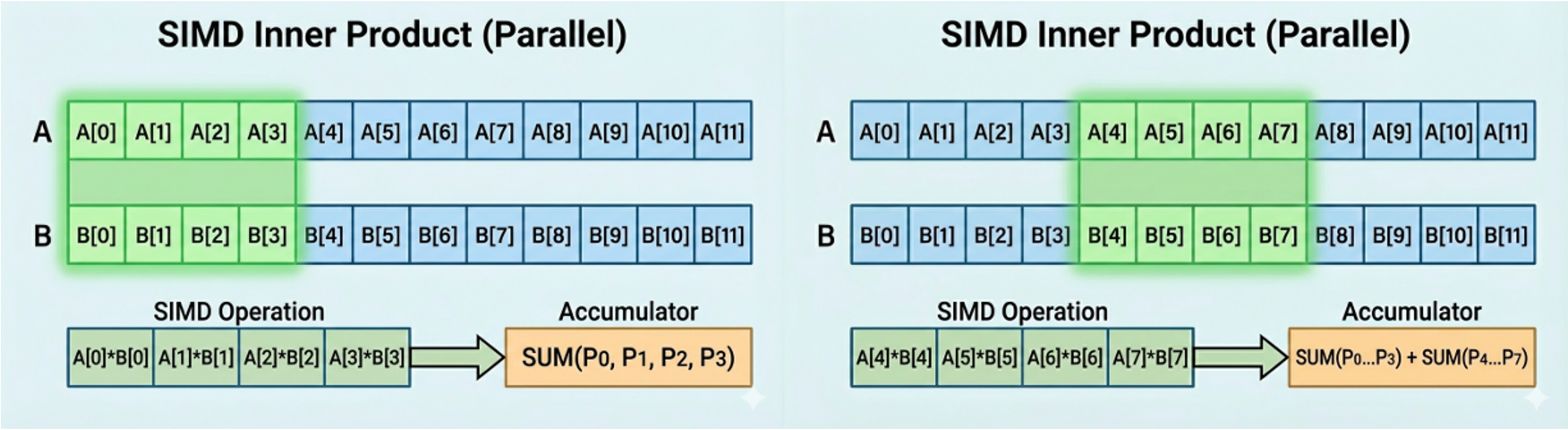 OpenSearch 3.5: Bulk SIMD FP16 distance calculation
OpenSearch 3.5: Bulk SIMD FP16 distance calculation
While the Faiss SIMD approach in OpenSearch 3.4 was already efficient, it only applied SIMD between a query and a single vector at a time. This meant that the same portion of the query vector had to be reloaded into the register for every vector comparison. We improved this by reusing loaded query values across multiple vectors whenever possible. For example, consider a 768-dimensional vector: when the first eight FP32 values are loaded into a SIMD register, they can be applied to multiple vectors simultaneously, rather than reloading them for each vector comparison. This approach is faster because performing operations in bulk between registers is much quicker than repeatedly loading values and processing them individually.
In OpenSearch 3.5, we introduced Bulk SIMD FP16 distance calculation. The key insight was that if the candidate vectors to evaluate are already known, distance calculations can be performed in bulk rather than comparing the query with each vector individually.
This is the core idea behind Bulk SIMD: we load the corresponding float values from multiple vectors into registers and compute distances, accumulating results all at once. By leveraging multiple registers simultaneously, many operations can be performed in parallel, resulting in significantly faster performance.
To illustrate how this works in practice, let’s examine the inner product calculation.
Inner product example
The following diagram illustrates how bulk SIMD calculates the inner product in parallel across multiple vectors.
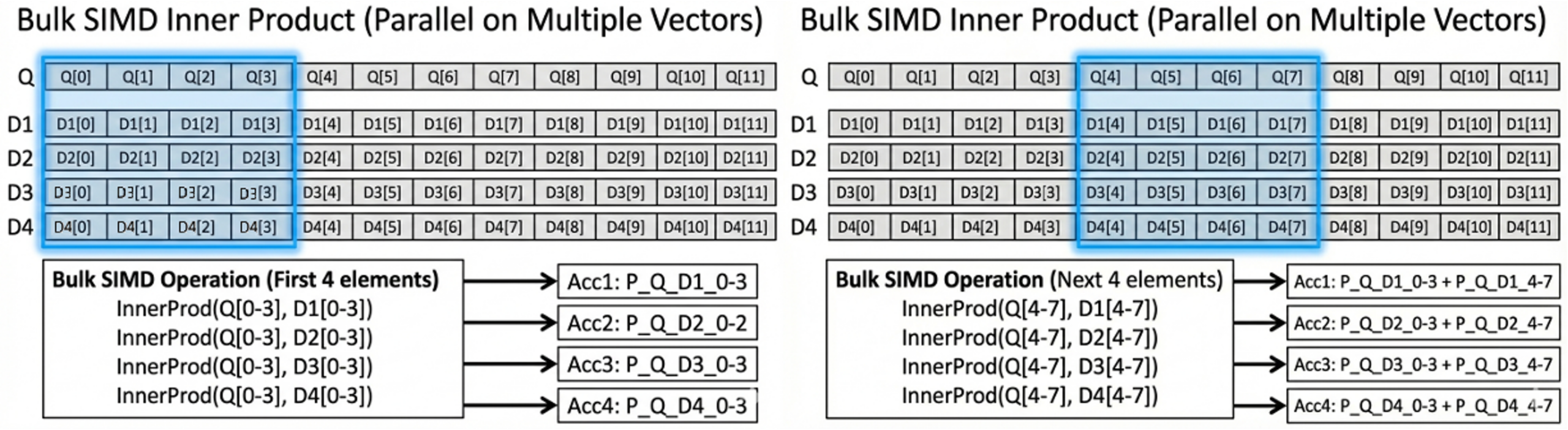 Bulk SIMD processes multiple vector elements simultaneously rather than one by one. For example, the CPU can load four elements from a query vector and four elements from a data vector into a SIMD register, then compute their distance in parallel. On wider SIMD architectures (e.g., AVX2 or AVX-512), even more elements can be processed per instruction.
Bulk SIMD processes multiple vector elements simultaneously rather than one by one. For example, the CPU can load four elements from a query vector and four elements from a data vector into a SIMD register, then compute their distance in parallel. On wider SIMD architectures (e.g., AVX2 or AVX-512), even more elements can be processed per instruction.
Because the computation occurs entirely in registers and the data is accessed sequentially:
- The L1 cache hit rate is high
- The CPU’s hardware prefetcher can automatically load upcoming elements
- Memory latency is effectively hidden
Thus, bulk SIMD improves throughput by combining parallel computation with efficient, cache-friendly memory access.
The following pseudocode presents the bulk SIMD approach:
// We know query and 4 candidate vectors uint8_t* Query_Vector <- Prepare Query Vector uint8_t* Vector1 <- Get Vector1's Pointer uint8_t* Vector2 <- Get Vector2's Pointer uint8_t* Vector3 <- Get Vector3's Pointer uint8_t* Vector4 <- Get Vector4's Pointer // Registers for accumulation // FMA stands for fused multiply-add, FMA(a, b, c) = a * b + c FP32_Register fmpSum1 FP32_Register fmpSum2 FP32_Register fmpSum3 FP32_Register fmpSum4 // For all values, we do bulk SIMD Inner product. // In this example, the dimension is assumed to be a multiple of 8 for simplicity. for (int i = 0 ; i < Dimension ; i += 8) { // Load 8 FP32 values into a register FP32_Register queryFloats <- Query_Vector[i:i+8] // Load 8 FP16 values into registers FP16_Register1 vec1Float16s <- Vector1[i:i+8] FP16_Register2 vec2Float16s <- Vector2[i:i+8] FP16_Register3 vec3Float16s <- Vector3[i:i+8] FP16_Register4 vec4Float16s <- Vector4[i:i+8] // Convert FP16 values to FP32 FP32_Register vec1Float32s <- ConvertToFP32(FP16_Register1) FP32_Register vec2Float32s <- ConvertToFP32(FP16_Register2) FP32_Register vec3Float32s <- ConvertToFP32(FP16_Register3) FP32_Register vec4Float32s <- ConvertToFP32(FP16_Register4) // Inner Product : SIMD FMA, accumulate = accumulate + q[i] * v[i] fmpSum1 = SIMD_FMA(fmpSum1, queryFloats, vec1Float32s) fmpSum2 = SIMD_FMA(fmpSum2, queryFloats, vec2Float32s) fmpSum3 = SIMD_FMA(fmpSum3, queryFloats, vec3Float32s) fmpSum4 = SIMD_FMA(fmpSum4, queryFloats, vec4Float32s) } // Set score values SCORE[0] = SUM(fmpSum1) SCORE[1] = SUM(fmpSum2) SCORE[2] = SUM(fmpSum3) SCORE[3] = SUM(fmpSum4)
For information about the ARM Neon implementation, see the k-NN repo.
Performance benchmarks
The following sections present performance benchmark results.
Benchmark environment
- Data set : Cohere-10M, 768 Dimension
- Node : r7i.4xlarge, r7g.4xlarge
- Shards : 3 nodes 1 replica
- Index type : FP16
- Number of segments : 80
Benchmark results
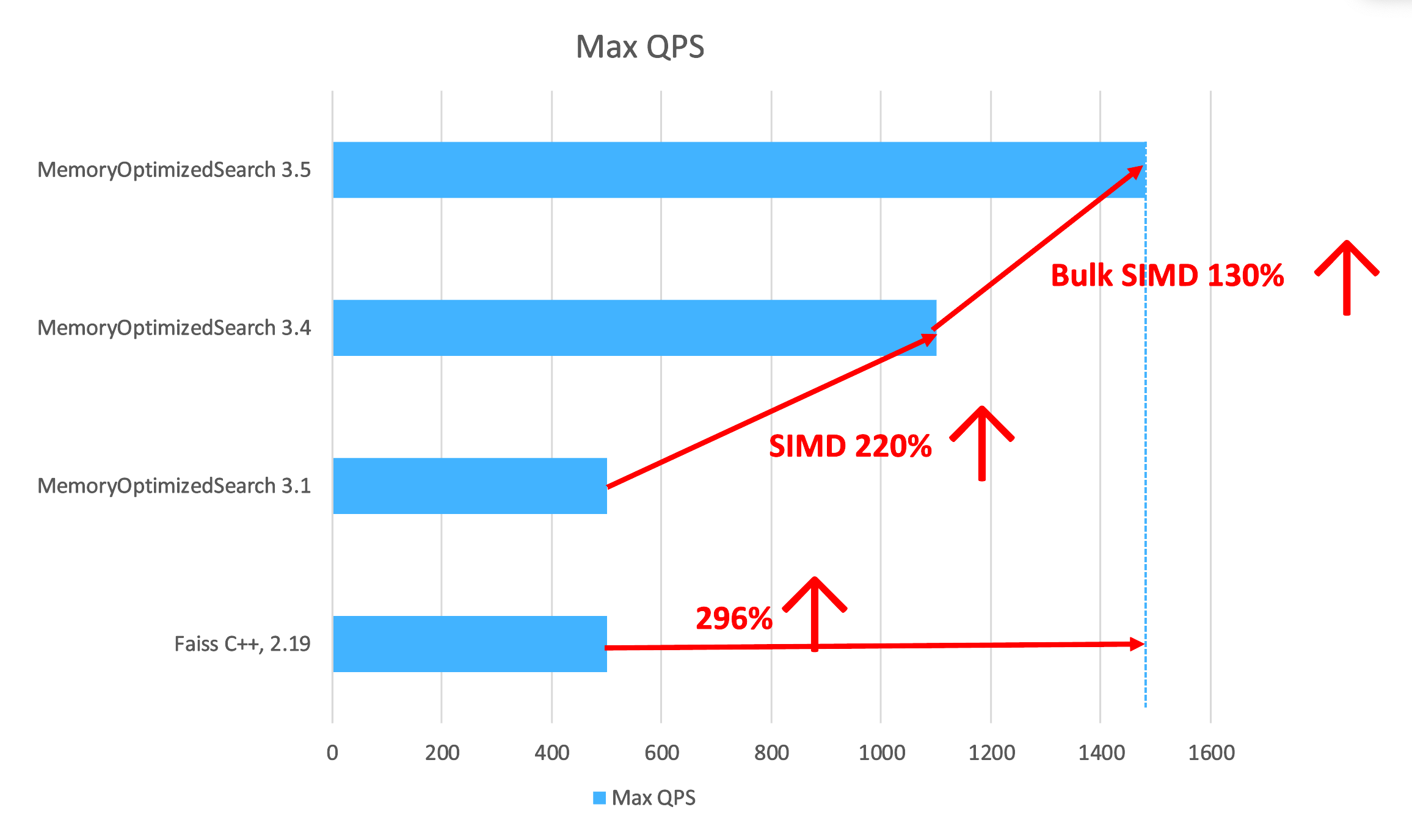
The following graph presents the benchmarking results.
 The following table provides detailed throughput and latency metrics for each version and CPU architecture.
The following table provides detailed throughput and latency metrics for each version and CPU architecture.
| Version | CPU architecture | Max throughput | Average latency | p90 latency | p99 latency |
|---|---|---|---|---|---|
| 3.1 | r7i | 398.87 | 209.66 | 300 | 330 |
| 3.1 | r7g | 495.49 | 168.64 | 235 | 253 |
| 3.4 | r7i | 1025.45 | 81.42 | 124 | 136 |
| 3.4 | r7g | 1112.13 | 75.09 | 111 | 120 |
| 3.5 | r7i | 1303.76 | 63.99 | 95 | 105 |
| 3.5 | r7g | 1477.88 | 56.42 | 82 | 91 |
Upgrading from OpenSearch 3.1 to 3.4 resulted in approximately 230% higher QPS and cut average latency in half, reducing p99 latency from about 300 ms to 120 ms. Moving from 3.4 to 3.5 added an additional 30% boost in throughput, bringing p99 latency down to an all-time low of 91 ms.
Overall, comparing OpenSearch 3.1 to 3.5 shows a total performance evolution: throughput increased by 310%, while latency dropped by nearly 300%. Bulk SIMD transformed the system from a slow baseline handling roughly 450 req/s into a high-performance engine capable of nearly 1,500 req/s with almost instantaneous responses.
What’s next?
From an implementation perspective, this optimization can also be applied to byte and FP32 indexes, which are our primary targets. We are actively exploring opportunities to further optimize their performance.
For binary indexes, however, bulk SIMD does not provide any performance improvement. We believe this is because the XOR operation is already heavily optimized in the JVM. Should opportunities for SIMD optimization in binary indexes emerge, we will evaluate them.
Try it out
Ready to experience these performance improvements? Upgrade to OpenSearch 3.5 and enable memory-optimized search with FP16 vector indexes to take advantage of bulk SIMD optimizations. We’d love to hear about your results and use cases on the OpenSearch forum. Your feedback helps us continue improving vector search performance for the community.



