
REST APIs have been the foundation of web services for decades, offering simplicity and broad compatibility. However, as data-intensive applications scale, the text-based JSON format used by REST APIs can become a bottleneck because of parsing overhead and larger payload sizes. Modern alternatives such as gRPC, paired with Protocol Buffers (Protobuf), address these limitations using binary serialization, HTTP/2 multiplexing, and strong typing.
The industry has recognized these benefits—companies such as Google, Netflix, and Uber have adopted gRPC for internal microservices. Now OpenSearch joins this movement by introducing native gRPC endpoints that use Protobuf schemas, offering a high-performance alternative to traditional REST APIs.
This blog post explores the challenges of maintaining consistent REST and gRPC APIs, our automated approach to generating Protobuf definitions from the OpenSearch OpenAPI specifications, and benchmark results demonstrating real-world performance gains.
Protobuf generation and automation
Adding gRPC support to the existing REST API framework presents several challenges:
- Maintaining consistency: REST and gRPC APIs must expose identical functionality, accept the same inputs, and return equivalent outputs. Manual synchronization is error-prone and doesn’t scale.
- Capturing complex semantics: OpenSearch REST APIs have intricate behaviors—polymorphic request bodies, conditional field validation, and dynamic mappings—that must be accurately represented in Protobuf schemas.
- Keeping APIs in sync: As OpenSearch evolves, both REST and gRPC APIs need simultaneous updates. Manual maintenance creates drift and technical debt.
To address these challenges, we developed an automated conversion pipeline that generates Protobuf schemas directly from the existing OpenSearch OpenAPI specifications. This ensures that REST and gRPC APIs remain synchronized at the source.
High-level conversion pipeline
Our conversion pipeline consists of three stages (preprocessing, customized OpenAPI generation, and post-processing), as shown in the following image.
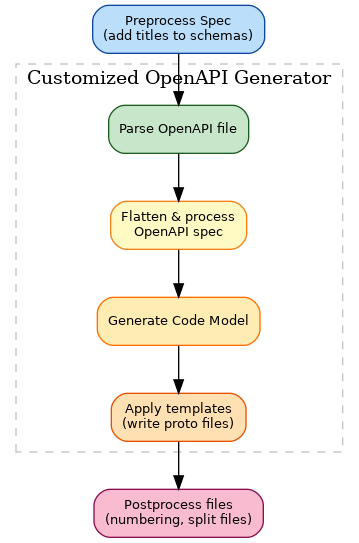
The following sections describe each stage.
Stage 1: Preprocessing
The pipeline first normalizes the OpenAPI specification:
- Resolves all
$refpointers to inline definitions. - Flattens nested schemas for cleaner Protobuf message generation.
- Validates required fields and type constraints.
- Standardizes naming conventions to be Protobuf-compatible.
Stage 2: Core conversion
Using the OpenAPI Generator tool, the preprocessed specification is translated to Protobuf:
- OpenAPI objects become Protobuf
messagetypes. - REST endpoints map to gRPC
servicedefinitions withrpcmethods. - JSON primitive types convert to Protobuf scalar types.
- Arrays transform into
repeatedfields.
The tool applies custom templates and configurations specific to OpenSearch API patterns, handling edge cases such as polymorphic types and optional fields.
Stage 3: Post-processing and compatibility checks
The final stage validates the generated Protobuf schemas:
- Wire compatibility verification ensures that REST JSON and gRPC Protobuf representations serialize and deserialize to equivalent structures.
- Semantic validation confirms that field constraints, defaults, and validation rules match between protocols.
- Regression testing compares generated schemas against previous versions to prevent breaking changes.
- Custom refinements apply manual adjustments when automated conversion cannot capture nuanced API behavior.
This pipeline runs as part of our continuous integration system. When developers modify OpenAPI specifications, the pipeline automatically regenerates Protobuf schemas and validates compatibility, ensuring that the two APIs never diverge.
Native gRPC support in OpenSearch
The OpenSearch gRPC implementation runs directly within OpenSearch nodes, not as a proxy or adapter layer. The gRPC transport operates in parallel with the REST transport, and both share the same underlying request handlers and business logic.
This approach provides several benefits:
- No additional infrastructure: You don’t need to deploy separate gRPC gateway services.
- Consistent behavior: Both protocols execute identical code paths, guaranteeing functional equivalence.
- Incremental adoption: You can adopt gRPC incrementally, using it for some endpoints while keeping REST for others. Both protocols can be enabled at the same time because they run on different ports.
Benchmark experiments: gRPC compared to REST
To quantify the performance impact of gRPC, we conducted benchmarks comparing gRPC and REST across two common workloads: vector search and bulk ingestion.
Test setup
We used the following test configuration:
- Cluster configuration:
- OpenSearch version 3.3
- 3
c5.xlargecluster manager nodes - 5
r5.xlargedata nodes
- Benchmarking tool: OpenSearch Benchmark (OSB)
- Network: All nodes within the same AWS Availability Zone to minimize network variance
k-NN vector search
We benchmarked k-nearest neighbor (k-NN) vector search, a latency-sensitive workload common in semantic search and recommendation systems. Our dataset for this workload was a random sample of MS MARCO using mxbai-large-v1 (100,000 queries on 1 million vectors ingested, 4.3 GB total).
The following table shows the latency comparison.
| Percentile | REST (ms) | gRPC (ms) | Improvement |
|---|---|---|---|
| P50 | 5.33 | 5.08 | 4.74% |
| P90 | 6.00 | 5.64 | 5.98% |
The following table shows the throughput comparison.
| REST (ops/sec) | gRPC (ops/sec) | Improvement |
|---|---|---|
| 143.26 | 173.12 | 17.24% |
In our tests, gRPC delivered consistent P50 latency improvements of 4.74%. The mean throughput increased by 17.24%, allowing the same cluster to handle more queries per second. These improvements are driven by the following factors:
- A 53% reduction in payload size because of Protobuf’s compact binary encoding.
- An approximately 58% reduction in client-side processing time for serialization and deserialization.
- Lower CPU utilization on both client and server sides.
Bulk ingestion
We tested bulk document indexing using the http_logs dataset from the opensearch-benchmark-workloads repository (247 million documents, approximately 31 GB total).
The following table shows the performance by bulk request size.
| Documents per request | gRPC throughput benefit | gRPC latency reduction (P50) |
|---|---|---|
| 10,000 | 16.2% | 22.6% |
| 5,000 | 15.8% | 22.4% |
| 2,500 | 14.8% | 21.1% |
| 1,000 | 12% | 13.6% |
Key findings include the following:
- A consistent approximately 22% latency reduction across different bulk sizes.
- On average, a 16.4% payload size reduction because of binary encoding.
- Performance improvement that plateaus at approximately 5,000 documents per bulk request, suggesting optimal batch sizing for this dataset.
Bulk ingestion benefits significantly from gRPC for the following reasons:
- Large JSON arrays compress poorly and require expensive parsing.
- HTTP/2 multiplexing allows concurrent bulk requests over a single connection.
- Binary encoding reduces network transfer time, which is especially important for high-throughput ingestion pipelines.
Binary document formats
In addition to Protobuf for API structure, OpenSearch supports binary document formats for the actual indexed content:
- SMILE, a binary encoding of JSON maintained by the Jackson project.
- Concise Binary Object Representation (CBOR), an IETF standard binary format similar to JSON.
These formats further reduce payload sizes and parsing overhead when combined with gRPC. For example, using SMILE with gRPC can achieve up to 65% total payload reduction compared to using REST with JSON.
You can specify binary formats using Content-Type headers; OpenSearch automatically handles serialization and deserialization. For implementation details, see issue #19311.
Best practices
Based on our benchmarks and production experience, gRPC performs best in the following scenarios:
- Large payloads: When request or response sizes exceed several kilobytes, Protobuf’s binary encoding delivers measurable performance gains.
- High-throughput workloads: Applications requiring thousands of operations per second benefit from gRPC’s lower CPU overhead and HTTP/2 connection efficiency.
- Binary document formats: Combining gRPC with SMILE or CBOR maximizes payload reduction and parsing speed.
For use cases in which these conditions don’t apply—such as low-frequency administrative operations or interactive debugging—REST remains a simpler, more accessible choice.
We recommend end-to-end benchmarking using your specific workload and data characteristics to determine whether gRPC provides sufficient benefit to justify migration.
Current state and future plans
The OpenSearch gRPC support is available for select APIs, including the following:
- Bulk Indexing API
- k-NN vector search
- Search API (experimental)
OpenSearch Benchmark (OSB) supports this implementation and includes native gRPC workload configurations for performance testing.
What’s next
We’re actively expanding gRPC support across OpenSearch:
- Broader API coverage: Adding gRPC endpoints for aggregations, snapshots, cluster management, and other frequently used APIs.
- Client library support: Developing official gRPC clients for Java, Python, JavaScript, and Go to simplify adoption.
- Security and observability: Integrating gRPC with the OpenSearch Security plugin for authentication and authorization and enhancing logging and tracing for gRPC requests.
- Performance optimizations: Exploring advanced techniques such as streaming search results, server-side batching, and custom compression algorithms.
Rather than replacing REST, gRPC is a complementary option that excels in performance-critical scenarios. OpenSearch will continue supporting both protocols, allowing you to choose the best fit for your use case.
Get involved
We welcome feedback and contributions from the OpenSearch community:
- Share your experience: Have you tried gRPC with OpenSearch? Join the discussion on the OpenSearch forum.
- Contribute: Visit the gRPC project board to view planned work and contribute code or ideas.
- Documentation: Explore the gRPC API documentation for usage examples and migration guides.
Together, we can continue advancing OpenSearch performance and capabilities for modern search and analytics workloads.
For more information about the automated Protobuf conversion pipeline, see the pipeline documentation and Protobuf conversion rules.





