
In OpenSearch 3.0, we introduced semantic highlighting — an AI-powered feature that intelligently identifies relevant passages in search results based on meaning rather than exact keyword matches.
OpenSearch 3.3 introduces batch processing for externally hosted semantic highlighting models, reducing machine learning (ML) inference calls from N to 1 per search query. Our benchmarks demonstrate 100–1,300% performance improvements, depending on document length and result set size.
Try our demo now: Experience semantic highlighting on the OpenSearch ML Playground, presented in the following image.
 What’s new: Batch processing for remote models
What’s new: Batch processing for remote models
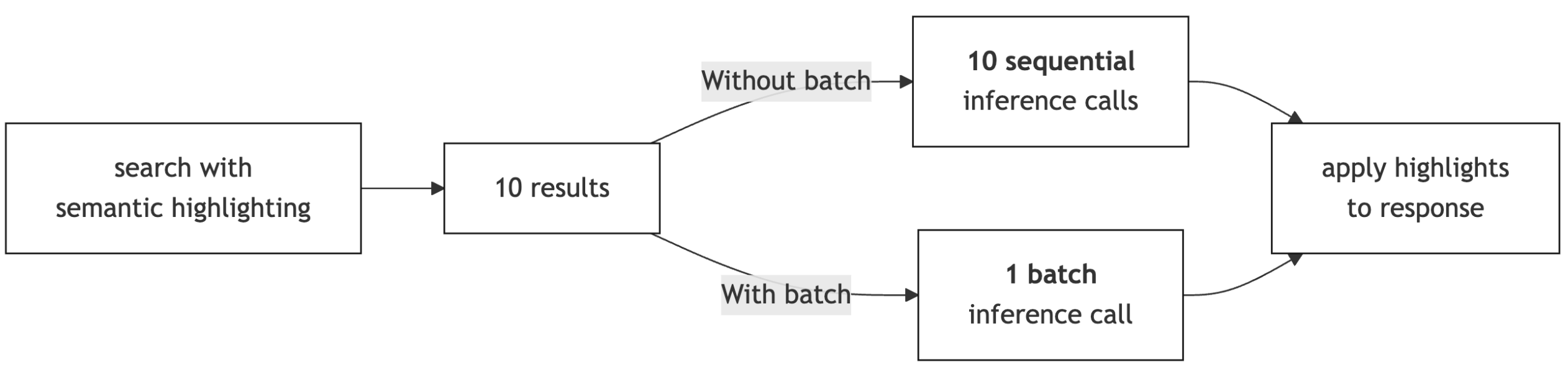
In OpenSearch 3.0, semantic highlighting processes each search result individually, making one ML inference call per result. For queries returning many results, this sequential approach can add latency that grows with result set size. OpenSearch 3.3 introduces a new approach (shown in the following diagram): collecting all search results and sending them in a single batched ML inference call, reducing overhead latency and improving GPU utilization.
Batch processing currently applies to remote semantic highlighting models only (those deployed on Amazon SageMaker or other external endpoints).
Using batch semantic highlighting in search requests
To get started with batch semantic highlighting in your searches, follow these steps. For a complete setup, see the semantic highlighting tutorial.
Step 1: Configure your remote model
To use batch processing, you’ll need a model that supports remote batch inference deployed on an external endpoint. Here’s how to integrate with an Amazon SageMaker endpoint hosted on AWS:
- Create the necessary Amazon SageMaker model endpoint resources. For more information, see the README guide.
- Deploy the model endpoint to OpenSearch. For more information, see the Amazon SageMaker blueprint guide.
Step 2: Enable system-generated pipelines
Add the following cluster setting to enable OpenSearch to automatically create the system-default batch semantic highlighting pipeline for processing search responses:
PUT /_cluster/settings { "persistent": { "search.pipeline.enabled_system_generated_factories": ["semantic-highlighter"] } }
Step 3: Add the batch flag to your query
Include batch_inference: true in your search request to enable batch semantic highlighting. The following example uses a neural query:
POST /neural-search-index/_search { "size": 10, "query": { "neural": { "embedding": { "query_text": "treatments for neurodegenerative diseases", "model_id": "<your-text-embedding-model-id>", "k": 10 } } }, "highlight": { "fields": { "text": { "type": "semantic" } }, "options": { "model_id": "<your-semantic-highlighting-model-id>", "batch_inference": true } } }
Your queries will now use batch processing automatically.
Performance benchmarks
We evaluated the performance impact of batch processing for semantic highlighting on the MultiSpanQA dataset. The test environment was configured as follows.
| OpenSearch cluster | Version 3.3.0 deployed on AWS (us-east-2) | | Data nodes | 3 × r6g.2xlarge (8 vCPUs, 64 GB memory each) | | Manager nodes | 3 × c6g.xlarge (4 vCPUs, 8 GB memory each) | | Semantic highlighting model | opensearch-semantic-highlighter-v1 deployed remotely at Amazon SageMaker endpoint with single GPU-based ml.g5.xlarge | | Embedding model | sentence-transformers/all-MiniLM-L6-v2 deployed within OpenSearch cluster | | Benchmark client | ARM64, 16 cores, 61 GB RAM | | Test configuration | 10 warmup iterations, 50 test iterations, 3 shards, 0 replicas |
We tested with two document sets with different document lengths.
| Dataset | Document length | Mean tokens | P50 tokens | P90 tokens | Max tokens |
|---|---|---|---|---|---|
| MultiSpanQA | Long documents | ~303 | ~278 | ~513 | ~1,672 |
| MultiSpanQA-Short | Short documents | ~79 | ~70 | ~113 | ~213 |
Latency
We measured the latency overhead of semantic highlighting by comparing semantic search highlighting both when enabled and disabled. The baseline semantic search latency is approximately 20–25 ms across all configurations. The following table shows the highlighting overhead only (values exclude the baseline search time). All latency measurements are service-side took times from OpenSearch responses.
| k value | Search client | Document length | P50 without batch processing (ms) | P50 with batch processing (ms) | P50 improvement | P90 without batch processing (ms) | P90 with batch processing (ms) | P90 improvement |
|---|---|---|---|---|---|---|---|---|
| 10 | 1 | Long | 209 | 123 | 70% | 262 | 179 | 46% |
| 10 | 4 | Long | 378 | 171 | 121% | 487 | 302 | 61% |
| 10 | 8 | Long | 699 | 309 | 126% | 955 | 624 | 53% |
| 10 | 1 | Short | 175 | 55 | 218% | 217 | 59 | 268% |
| 10 | 4 | Short | 327 | 62 | 427% | 445 | 120 | 271% |
| 10 | 8 | Short | 610 | 101 | 504% | 860 | 227 | 279% |
| 50 | 1 | Long | 867 | 633 | 37% | 999 | 717 | 39% |
| 50 | 4 | Long | 1,937 | 912 | 112% | 2,248 | 1,685 | 33% |
| 50 | 8 | Long | 3,638 | 1,474 | 147% | 4,355 | 3,107 | 40% |
| 50 | 1 | Short | 760 | 82 | 827% | 828 | 205 | 304% |
| 50 | 4 | Short | 1,666 | 193 | 763% | 1,971 | 362 | 445% |
| 50 | 8 | Short | 3,162 | 219 | 1,344% | 3,704 | 729 | 408% |
The benchmarking demonstrates that batch processing reduces the semantic highlighting overhead. For short documents with k=50 and 8 clients, batch processing reduces highlighting latency from 3,162 ms to just 219 ms (P50)—a 1,344% improvement. The P90 latency also shows improvements (408%), demonstrating consistent performance benefits. The semantic search baseline (~25 ms) remains constant, so these improvements directly translate to faster end-to-end response times.
Key findings:
- k=10: Moderate to significant improvement (46–504% for P50, 46–279% for P90).
- k=50: Dramatic improvement (37–1,344% for P50, 33–445% for P90).
- Short documents benefit more: Up to 1,344% faster (P50) compared to 147% for long documents at k=50.
- Why the difference?: Long documents could exceed the model’s 512 token limit, requiring multiple chunked inference runs even with batch processing. Short documents can be processed in a single pass, maximizing the benefit of batching.
- P50 shows larger gains: Median latency improves more than tail latency, but both benefit significantly.
Throughput
To understand how batch processing affects the system’s capacity to handle concurrent requests, we also measured the throughput (mean number of operations per second). The results (presented in the following table) show consistent improvements across all configurations.
| k value | Search clients | Doc length | Without batch (ops/s) | With batch (ops/s) | Improvement |
|---|---|---|---|---|---|
| 10 | 1 | Long | 4.23 | 6.29 | 49% |
| 10 | 4 | Long | 9.18 | 17.9 | 95% |
| 10 | 8 | Long | 10.02 | 21.27 | 112% |
| 10 | 1 | Short | 4.83 | 11.59 | 140% |
| 10 | 4 | Short | 10.47 | 37.79 | 261% |
| 10 | 8 | Short | 12.03 | 48.33 | 302% |
| 50 | 1 | Long | 1.11 | 1.49 | 34% |
| 50 | 4 | Long | 1.99 | 3.74 | 88% |
| 50 | 8 | Long | 2.12 | 4.28 | 102% |
| 50 | 1 | Short | 1.27 | 4.3 | 239% |
| 50 | 4 | Short | 2.27 | 11.55 | 409% |
| 50 | 8 | Short | 2.43 | 14.33 | 490% |
Throughput improvements demonstrate that batch processing not only reduces individual query latency but also increases the overall system capacity, allowing you to serve more concurrent users with the same infrastructure.
Conclusion
Batch processing in OpenSearch 3.3 brings significant performance improvements to semantic highlighting for remote models. By reducing the number of ML inference calls from N to 1 per search, we’ve delivered:
- Faster response times and higher query throughput when highlighting multiple search results.
- More efficient use of remote model resources.
- Backward-compatible queries (existing queries work as is).
Try batch processing for semantic highlighting and share your feedback on the OpenSearch forum.
