
Retrieval-augmented generation (RAG) has become a critical approach for building trustworthy, domain-specific artificial intelligence (AI) systems. By combining retrieval systems with large language models (LLMs), RAG allows applications to ground their outputs in external knowledge sources. However, building reliable RAG systems remains challenging, especially when working with complex enterprise documents and large-scale retrieval. Two key bottlenecks frequently arise: accurate document ingestion and high-quality retrieval. This is where Docling and OpenSearch together provide a powerful solution. Docling ensures precise document parsing and structuring, while OpenSearch enables scalable, metadata-aware search and retrieval. The result is a RAG foundation that can accurately represent and efficiently retrieve knowledge across diverse document types.
What is Docling?
Docling is an open-source document processing toolkit that transforms complex documents into structured, machine-readable data for AI applications, including generative AI systems. It can parse a wide range of document formats, such as PDF, DOCX, and PPTX, while preserving essential structural information like layout, tables, and reading order. The parsed content can then be exported as Markdown, JSON, or HTML, making it easy to incorporate document data into modern AI workflows. Originally developed at IBM Research, Docling was donated as an incubation-stage project to the LF AI & Data Foundation in April 2025. It has since seen rapid community adoption, with more than 42,000 GitHub stars, usage across 2,400 GitHub organizations, and 1.5 million monthly downloads from PyPI. Docling integrates seamlessly with the broader generative AI ecosystem, providing flexible serializers, metadata enrichment, and hierarchical chunking mechanisms‚ all key enablers for high-quality RAG workflows.
Why combine Docling and OpenSearch for RAG?
Together, Docling and OpenSearch address both sides of the RAG challenge:
- Docling ensures that the input documents are transformed into structured, semantically meaningful chunks with rich metadata.
- OpenSearch provides a scalable, high-performance search engine capable of storing embeddings, running vector similarity searches, and filtering or aggregating results using metadata.
This combination helps developers build AI applications that are accurate, explainable, and robust when dealing with real-world data.
Leveraging Docling and OpenSearch for advanced RAG
The integration between Docling and OpenSearch unlocks several key benefits for developers building RAG applications.
Faithful document conversion with Docling
Docling can parse and convert a variety of document formats, including PDF, DOCX, and HTML, into a structured representation in JSON (the DoclingDocument). This representation retains hierarchical relationships, such as sections and subsections, and preserves complex data like tables and figures. Docling also supports multimodal inputs: it can transcribe audio files and run vision models on images to produce descriptive captions. By fusing these capabilities, developers can build a RAG pipeline that draws from multiple formats in a single, coherent representation. Example: parsing a PDF into structured data using Docling’s Python API
from docling.document_converter import DocumentConverter # Document path or URL source = "https://arxiv.org/pdf/2408.09869" # Convert to structured format (DoclingDocument) converter = DocumentConverter() doc = converter.convert(source).document # Inspect the parsed structure print(len(doc.tables)) #> 3 # Export to markdown format print(doc.export_to_markdown()) #> "## Docling Technical Report[...]"
Chunking and custom serialization
Docling provides flexible chunking mechanisms that allow developers to segment documents into meaningful, structured units for retrieval and generative AI tasks. The HierarchicalChunker splits content into semantically coherent segments‚ such as sections, paragraphs, tables, and figures‚ while preserving the logical document hierarchy in metadata. This structure-aware approach improves both the precision and interpretability of retrieval results. Building on this foundation, Docling introduces the HybridChunker, which applies tokenization-aware refinements on top of hierarchical chunking. The hybrid approach ensures that the resulting chunks are optimally sized for embedding models, maintaining semantic integrity while respecting model token limits. In addition, Docling supports custom serializers, such as Markdown serializers for tabular data. These serializers make it easier for generative models to understand the structure and context of the information. By combining hybrid chunking with structured serialization and OpenSearch’s vector indexing, developers can build RAG pipelines that deliver high-fidelity document understanding, scalable storage, and accurate retrieval.
Context-aware retrieval using OpenSearch
OpenSearch supports vector search with metadata filtering, allowing retrievals that consider both semantic similarity and contextual fields provided by Docling, such as section type, table presence, or document source. This enables domain-specific retrieval strategies‚ such as focusing on quantitative data or specific document sections‚ resulting in more relevant and accurate generative outputs.
Context expansion for better answers
Docling retains hierarchical relationships in chunk metadata, enabling context expansion during retrieval. For instance, when a subsection is retrieved, related chunks from the parent section can be included automatically to provide a more coherent context. This expansion ensures that the model receives coherent, contextually complete inputs‚ reducing hallucinations and improving factual accuracy.
Integrating Docling and OpenSearch in RAG workflows
The LlamaIndex framework simplifies RAG orchestration by connecting document parsers, vector stores, and LLMs. Docling integrates naturally into this workflow as the ingestion and structuring component, while OpenSearch serves as the vector and metadata store. The following diagram shows an example of the integration workflow.
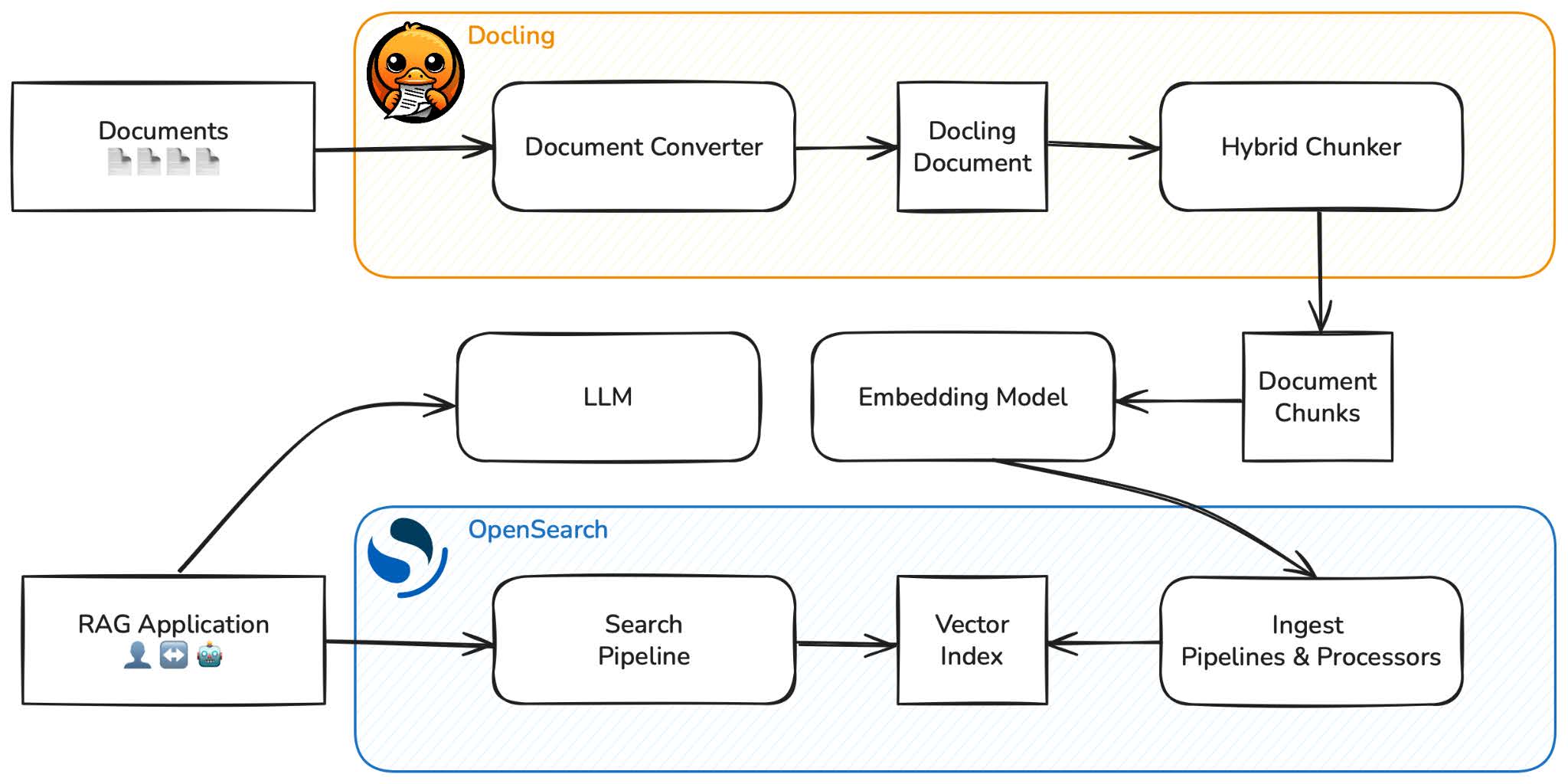 Load the files
Load the files
from llama_index.core import SimpleDirectoryReader
from llama_index.readers.docling import DoclingReader
my_docs = "/path/to/my/documents"
reader = DoclingReader(export_type=DoclingReader.ExportType.JSON)
dir_reader = SimpleDirectoryReader(
input_dir=my_docs,
file_extractor={".pdf": reader},
)
documents = dir_reader.load_data()
Define the transformations
Before ingesting data, define the transformations to apply to the DoclingDocument:
DoclingNodeParserexecutes the document-based chunking.MetadataTransformensures that generated chunk metadata is correctly formatted for indexing in OpenSearch.
from docling.chunking import HybridChunker
from llama_index.node_parser.docling import DoclingNodeParser
node_parser = DoclingNodeParser(chunker=HybridChunker())
class MetadataTransform(TransformComponent):
def __call__(self, nodes, **kwargs):
for node in nodes:
binary_hash = node.metadata.get("origin", {}).get("binary_hash", None)
if binary_hash is not None:
node.metadata["origin"]["binary_hash"] = str(binary_hash)
return nodes
Calculate, insert, and index the embeddings
Create an OpenSearchVectorClient, which encapsulates the logic for a single OpenSearch index with vector search enabled. Then initialize the index using the converted files, the Docling node parser, and the OpenSearch client that you just created. The DoclingDocument objects will be chunked, and the calculated embeddings will be stored and indexed in OpenSearch:
from llama_index.core import StorageContext, VectorStoreIndex
from llama_index.embeddings.ollama import OllamaEmbedding
from llama_index.vector_stores.opensearch import (
OpensearchVectorClient,
OpensearchVectorStore,
)
opensearch_endpoint = "http://localhost:9200" # Set the OpenSearch endpoint
text_field = "content"
embed_field = "embedding"
embed_model = OllamaEmbedding(model_name="granite-embedding:30m") # Set a LlamaIndex embedding object
embed_dim = len(embed_model.get_text_embedding("hi"))
client = OpensearchVectorClient(
endpoint="http://localhost:9200",
index=opensearch_endpoint,
dim=embed_dim,
embedding_field=embed_field,
text_field=text_field,
)
vector_store = OpensearchVectorStore(client)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(
documents=documents,
transformations=[node_parser, MetadataTransform()],
storage_context=storage_context,
embed_model=embed_model,
)
Assemble and run the RAG system
With LlamaIndex’s query engine, you can simply run a RAG system as follows:
from llama_index.llms.ollama import Ollama
from rich.console import Console
gen_model = Ollama(model="granite4:micro") # Set a LlamaIndex LLM object
console = Console(width=88)
query = "Which are the main AI models in Docling?"
query_engine = index.as_query_engine(llm=gen_model)
res = query_engine.query(query)
console.print(f"üë§: {query}\nü§ñ: {res.response.strip()}")
# 👤: Which are the main AI models in Docling?
# 🤖: Docling primarily utilizes two AI models. The first one is a layout analysis model,
# serving as an accurate object-detector for page elements. The second model is
# TableFormer, a state-of-the-art table structure recognition model. Both models are
# pre-trained and their weights are hosted on Hugging Face. They also power the
# deepsearch-experience, a cloud-native service for knowledge exploration tasks.
This example shows how easily developers can combine the best of Docling’s document understanding with OpenSearch’s search capabilities to build robust RAG applications.
Learn more
To explore these integrations and capabilities in more detail, see the following resources:
By combining Docling’s advanced document understanding with OpenSearch’s scalable retrieval, you can build RAG systems that deliver grounded, high-quality answers to complex questions.



