OpenSearch now integrates with DeepSeek, offering powerful and cost-effective AI capabilities. In this blog post, we’ll guide you through setting up a retrieval-augmented generation (RAG) system using OpenSearch and the DeepSeek model in just 5 minutes. This combination provides a robust and efficient way to build AI applications with accurate information retrieval.
RAG with OpenSearch and DeepSeek
The following diagram depicts the RAG workflow in OpenSearch using the DeepSeek model.
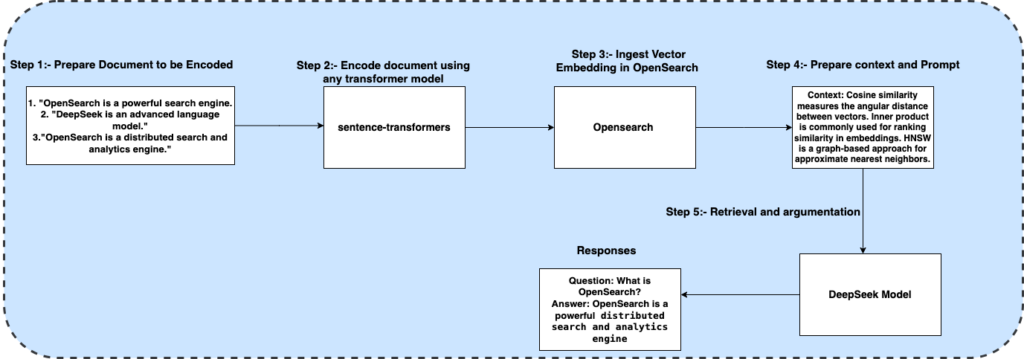
Follow these steps to set up RAG.
Prerequisites
- Python 3.8+
- Docker (for OpenSearch)
- Basic understanding of RAG systems
Step 1: Set up OpenSearch
First, run OpenSearch using Docker:
sudo docker run -d --name opensearch \ -p 9200:9200 -p 9600:9600 \ -e
"discovery.type=single-node" \ -e
"OPENSEARCH_INITIAL_ADMIN_PASSWORD=StrongPassword123!" \ -e
"plugins.security.disabled=true" \ opensearchproject/opensearch-knn:latest
Step 2: Install required packages
To install required packages, run the following command:
pip install opensearch-py transformers torch sentence-transformers
These packages form the backbone of the RAG system:
opensearch-py: The official Python client for OpenSearchtransformers: Hugging Face’s library for working with transformer modelstorch: PyTorch library for deep learning operationssentence-transformers: Used for creating embeddings
Step 3: Initialize the OpenSearch client and create an index
This setup creates a secure connection to OpenSearch and initializes an index. You’ll use basic authentication and SSL, though certificate verification is disabled for simplicity. In production, you must properly configure SSL certificates and use strong authentication.
from opensearchpy import OpenSearch, RequestsHttpConnection
# Step 1: OpenSearch Client Initialization with Error Handling
def get_opensearch_client():
try:
client = OpenSearch(
hosts=[{"host": "localhost", "port": 9200}],
http_compress=True,
http_auth=("admin", "StrongPassword123!"),
use_ssl=True,
verify_certs=False,
ssl_assert_hostname=False,
ssl_show_warn=False,
connection_class=RequestsHttpConnection
)
logger.info("✅ Connected to OpenSearch")
return client
except Exception as e:
logger.error(f" Failed to connect to OpenSearch: {e}")
exit(1)
client = get_opensearch_client()
# Step 2: Determine Embedding Model Dimension
embedding_model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2")
embedding_dim = embedding_model.get_sentence_embedding_dimension()
# Step 3: Create OpenSearch Index with k-NN Enabled
index_name = "documents"
index_body = {
"settings": {
"index": {
"knn": True, # Enable k-NN search
"number_of_shards": 1,
"number_of_replicas": 1
}
},
"mappings": {
"properties": {
"text": {"type": "text"},
"embedding": {
"type": "knn_vector",
"dimension": embedding_dim,
"method": {
"name": "hnsw",
"engine": "faiss",
"space_type": "innerproduct"
}
}
}
}
}
# Delete and recreate index if exists
if client.indices.exists(index=index_name):
client.indices.delete(index=index_name)
client.indices.create(index=index_name, body=index_body)
Step 4: Set up the DeepSeek model
In this step, you’ll initialize two key components:
- The SentenceTransformer model for creating document embeddings.
- The DeepSeek model for generating responses. The MiniLM-L6-v2 model provides a good balance between embedding performance and accuracy.
*from* transformers *import* AutoTokenizer, AutoModelForCausalLM
*from* sentence_transformers *import* SentenceTransformer
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/deepseek-coder-6.7b-base")
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/deepseek-coder-6.7b-base")
Step 5: Create a RAG pipeline
The RAG pipeline consists of two main functions:
index_document: Converts text into embeddings and stores them in OpenSearch.query_documents: Performs similarity search using k-NN to find relevant documents. In this example, k-NN search returns the three most similar documents; you can adjust this number based on your needs.
# Step 5: Normalize Embeddings for Inner Product
def normalize_vector(vector):
return vector / np.linalg.norm(vector)
# Step 6: Function to Index Documents
def index_document(text, doc_id=None, metadata=None):
embedding = embedding_model.encode(text)
embedding = normalize_vector(embedding).tolist() # Normalize for IP space
doc = {
"text": text,
"embedding": embedding,
"metadata": metadata or {}
}
try:
client.index(index=index_name, id=doc_id, body=doc)
logger.info(f"📄 Indexed document: {text}")
except Exception as e:
logger.error(f" Failed to index document {text}: {e}")
# Step 7: Function to Query Documents using k-NN
def query_documents(question, k=3):
question_embedding = embedding_model.encode(question)
question_embedding = normalize_vector(question_embedding).tolist()
search_query = {
"size": k,
"query": {
"knn": {
"embedding": {
"vector": question_embedding,
"k": k
}
}
}
}
try:
response = client.search(index=index_name, body=search_query)
return response["hits"]["hits"]
except Exception as e:
logger.error(f" Query failed: {e}")
return []
Example usage
This example demonstrates the complete workflow:
- Indexing sample documents
- Querying the system with a question
- Retrieving relevant context
- Generating a response using DeepSeek
# Step 8: Generate AI Response using DeepSeek
def generate_response(question):
results = query_documents(question)
if not results:
return " No relevant documents found."
context = " ".join([hit["_source"]["text"] for hit in results])
prompt = f"Context: {context}\nQuestion: {question}\nAnswer:"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_length=200)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
# Step 9: Index Multiple Documents
documents = [ ("OpenSearch is a powerful search engine.", "1"),
("DeepSeek is an advanced language model.", "2"),
("Elasticsearch is a distributed search and analytics engine.", "3"),
("Vector databases are optimized for handling vector-based queries.", "4"),
("Machine learning models use embeddings to represent data efficiently.", "5"),
("Large language models like GPT-4 can generate human-like text.", "6"),
("FAISS is a library for fast nearest neighbor search.", "7"),
("HNSW is a graph-based approach for approximate nearest neighbors.", "8"),
("Cosine similarity measures the angular distance between vectors.", "9"),
("Inner product is commonly used for ranking similarity in embeddings.", "10")
]
for text, doc_id in documents:
index_document(text, doc_id=doc_id)
queries = [
"What is OpenSearch?",
"How does FAISS work?",
"Explain cosine similarity.",
"What is a vector database?",
"Tell me about large language models."
]
for query in queries:
response = generate_response(query)
logger.info(f"\n📝 **Question:** {query}")
logger.info(f"📢 **Answer:** {response}")
Try it out
The following complete one-click script contains all of the preceding steps. Save this script as deepseek_rag.py:
import time
import logging
import numpy as np
from opensearchpy import OpenSearch, RequestsHttpConnection
from transformers import AutoTokenizer, AutoModelForCausalLM
from sentence_transformers import SentenceTransformer
# Configure logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# Step 1: OpenSearch Client Initialization
def get_opensearch_client():
try:
client = OpenSearch(
hosts=[{"host": "localhost", "port": 9200}],
http_compress=True,
http_auth=("admin", "StrongPassword123!"),
use_ssl=True,
verify_certs=False,
ssl_assert_hostname=False,
ssl_show_warn=False,
connection_class=RequestsHttpConnection
)
logger.info("✅ Connected to OpenSearch")
return client
except Exception as e:
logger.error(f" Failed to connect to OpenSearch: {e}")
exit(1)
client = get_opensearch_client()
# Step 2: Determine Embedding Model Dimension
embedding_model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2")
embedding_dim = embedding_model.get_sentence_embedding_dimension()
logger.info(f"✅ Embedding Dimension: {embedding_dim}")
# Step 3: Create OpenSearch Index with k-NN Enabled
index_name = "documents"
index_body = {
"settings": {
"index": {
"knn": True,
"number_of_shards": 1,
"number_of_replicas": 1
}
},
"mappings": {
"properties": {
"text": {"type": "text"},
"embedding": {
"type": "knn_vector",
"dimension": embedding_dim,
"method": {
"name": "hnsw",
"engine": "faiss",
"space_type": "ip"
}
}
}
}
}
if client.indices.exists(index=index_name):
client.indices.delete(index=index_name)
client.indices.create(index=index_name, body=index_body)
logger.info(f"✅ Created index: {index_name} with k-NN enabled and dimension {embedding_dim}")
# Step 4: Load DeepSeek Model
logger.info("🔄 Loading DeepSeek model...")
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/deepseek-coder-6.7b-base")
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/deepseek-coder-6.7b-base")
logger.info("✅ DeepSeek model loaded!")
# Step 5: Normalize Embeddings
def normalize_vector(vector):
return vector / np.linalg.norm(vector)
# Step 6: Function to Index Documents
def index_document(text, doc_id=None, metadata=None):
embedding = embedding_model.encode(text)
embedding = normalize_vector(embedding).tolist()
doc = {
"text": text,
"embedding": embedding,
"metadata": metadata or {}
}
try:
client.index(index=index_name, id=doc_id, body=doc)
logger.info(f"📄 Indexed document: {text}")
except Exception as e:
logger.error(f" Failed to index document {text}: {e}")
# Step 7: Function to Query Documents
def query_documents(question, k=3):
question_embedding = embedding_model.encode(question)
question_embedding = normalize_vector(question_embedding).tolist()
search_query = {
"size": k,
"query": {
"knn": {
"embedding": {
"vector": question_embedding,
"k": k
}
}
}
}
try:
response = client.search(index=index_name, body=search_query)
return response["hits"]["hits"]
except Exception as e:
logger.error(f" Query failed: {e}")
return []
# Step 8: Generate AI Response using DeepSeek
def generate_response(question):
results = query_documents(question)
if not results:
return " No relevant documents found."
context = " ".join([hit["_source"]["text"] for hit in results])
prompt = f"Context: {context}\nQuestion: {question}\nAnswer:"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_length=200)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
# Step 9: Index Multiple Documents
documents = [
("OpenSearch is a powerful search engine.", "1"),
("DeepSeek is an advanced language model.", "2"),
("OpenSearch is a distributed search and analytics engine.", "3"),
("Vector databases are optimized for handling vector-based queries.", "4"),
("Machine learning models use embeddings to represent data efficiently.", "5"),
("Large language models like GPT-4 can generate human-like text.", "6"),
("FAISS is a library for fast nearest neighbor search.", "7"),
("HNSW is a graph-based approach for approximate nearest neighbors.", "8"),
("Cosine similarity measures the angular distance between vectors.", "9"),
("Inner product is commonly used for ranking similarity in embeddings.", "10")
]
for text, doc_id in documents:
index_document(text, doc_id=doc_id)
logger.info("✅ All documents indexed!")
# Step 10: Run Multiple Queries
time.sleep(2) # Small delay for indexing
queries = [
"What is OpenSearch?",
"How does FAISS work?",
"Explain cosine similarity.",
"What is a vector database?",
"Tell me about large language models."
]
for query in queries:
response = generate_response(query)
logger.info(f"\n📝 **Question:** {query}")
logger.info(f"📢 **Answer:** {response}")
Before running the script, run OpenSearch:
sudo docker run -d --name opensearch \
-p 9200:9200 -p 9600:9600 \
-e "discovery.type=single-node" \
-e "OPENSEARCH_INITIAL_ADMIN_PASSWORD=StrongPassword123!" \
-e "plugins.security.disabled=true" \
opensearchproject/opensearch-knn:latest
Then run the deepseek_rag.py script:
python deepseek_rag.py
DeepSeek conversation responses
The following questions and answers show a conversation with DeepSeek using the RAG system:
Q:- What is a vector database?
A:- A vector database is a database that stores and indexes data in a
vector format.
Q:- What is OpenSearch?
A:- OpenSearch is a powerful search engine.
Q:- What is FAISS?
A:- FAISS is a library for fast nearest neighbor search.
Q:- How does FAISS work?
A:- FAISS is a library for fast nearest neighbor search.
It is used to find the nearest neighbors of a given vector in a large dataset.
The library uses a tree-based data structure to efficiently
search for the nearest neighbors.
Q:- Explain HNSW
A:- HNSW is a graph-based approach for approximate nearest neighbors.
It is used for ranking similarity in embeddings.
Q:- Explain the difference between cosine similarity and inner product.
A:-Cosine similarity measures the angle between two vectors,
while inner product is the dot product of two vectors.
Conclusion
This simple RAG implementation combines the power of OpenSearch’s vector search capabilities with DeepSeek’s advanced language understanding. While this is a basic setup, it provides a foundation that you can build upon for more complex applications.
The following are some key benefits of this implementation:
- Fast and efficient vector search with OpenSearch
- High-quality language understanding with DeepSeek
- Scalable architecture for larger datasets
- Easy to extend and customize
This implementation serves as a foundation for developing more advanced RAG systems. For production environments, it’s important to incorporate proper error handling, connection pooling, and potentially implement more refined retrieval strategies.


