In 2019, OpenSearch introduced the Vector Engine, which supports three native engines: Non-Metric Space Library (NMSLIB), Facebook AI Similarity Search (Faiss), and Lucene. Unlike Lucene, which is Java based, Faiss and NMSLIB are C++ libraries that OpenSearch accesses through a lightweight Java Native Interface (JNI) layer. However, these native engines handle I/O using file-based APIs, with Faiss relying on FILE pointers and NMSLIB using std::fstream to manage graph indexes.
This blog post explains how we addressed these limitations by introducing an abstraction layer for loading data into native engines without compromising performance. We’ll start with an overview of k-NN search, discuss the challenges of file API dependencies, and explain the solution we implemented. Finally, we’ll explore how these changes support searchable snapshots of vector indexes, which involves running approximate k-NN search on remote snapshots using native engines.
What is k-NN search?
The k-nearest neighbors (k-NN) search algorithm identifies the k closest vectors to a given query vector. It uses a distance metric, such as cosine similarity, to measure similarity between vectors, with closer points considered to be more similar.
In the OpenSearch vector database, you can choose from different vector search algorithms. A popular algorithm for approximate nearest neighbor (ANN) search in high-dimensional spaces is Hierarchical Navigable Small World (HNSW). HNSW organizes data points into a multi-layer graph in which each layer contains connections for efficient data navigation. Inspired by skip lists, HNSW graph layers have varying densities that increase proportionally with depth. This helps narrow the search space from broader to more specific regions—similar to locating an address by starting with a country and then narrowing down to a state, city, and street.
For more information about building a k-NN similarity search engine with OpenSearch, see our documentation.
Challenges with file-based APIs
Native vector engines, such as Faiss and NMSLIB, offer high performance and predictable latencies. However, their reliance on file-based APIs makes them difficult to integrate with storage that is not file system based.
Lucene uses the Java-based Directory abstraction for reading and writing files. The Directory class abstracts file storage, enabling operations like reading, writing, and managing file metadata across diverse storage systems. This abstraction allows the Lucene vector engine to store files independently of the underlying OpenSearch storage.
Unlike Lucene, native engines tightly couple their operations to file-based I/O. To address these limitations, we applied Lucene’s principles to native engines. By abstracting the I/O layer, we eliminated the engines’ tight coupling to specific file APIs. This enhancement enables integration with any OpenSearch directory implementation, making vector search compatible with a broader range of storage systems.
Introducing the loading layer
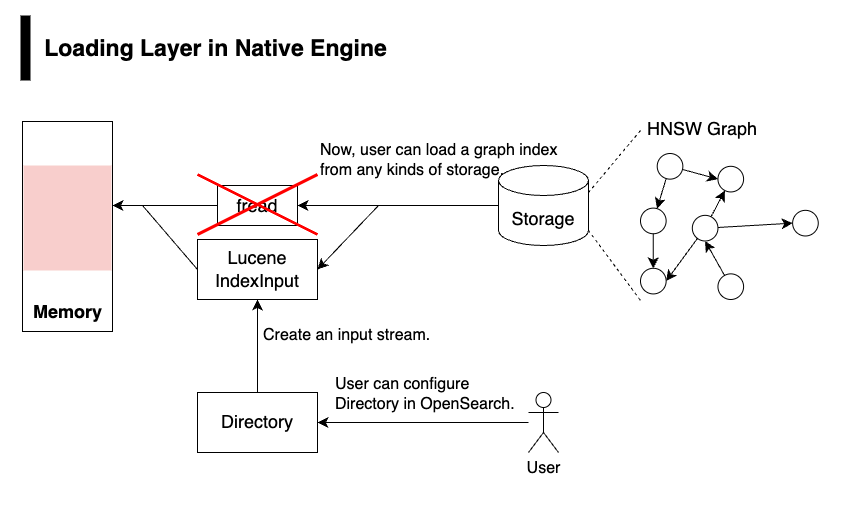
Both Faiss and NMSLIB load graph-based vector indexes from storage into memory. During this process, they use fread to fetch the bytes needed to reconstruct the graph.
To improve flexibility, we replaced fread with a read interface. Faiss provides an IOReader interface for reading index data from various storage systems. For NMSLIB, we introduced a similar read interface called NmslibIOReader. These interfaces allow the native engines to read data through an abstraction layer, making integration possible with OpenSearch’s directory implementations.
Because k-NN search is conducted after the graph is loaded into memory, this change does not impact average search performance.
The following diagram provides a high-level overview of the loading layer in native engines.
Performance benchmarks
The following sections present performance benchmark results.
Benchmarking environment
We ran benchmarking tests in an environment with the following configuration.
| OpenSearch version | 2.18 |
| vCPUs | 48 |
| Physical memory | 128 GB |
| Storage type | Amazon Elastic Block Store (Amazon EBS) |
| JVM | 63 GB |
| Total number of vectors | 1M |
| Dimensions | 128 |
Benchmarking results
During benchmarking, we observed that introducing the loading layer resulted in identical search performance compared to the baseline. Additionally, there were no differences in system metrics or JVM GC metrics when introducing the loading layer.
Based on these findings, we concluded that we successfully replaced the tight coupling of the File API with Lucene’s IndexInput. This change maintained the same search performance. Additionally, with this change you can integrate a custom Directory in OpenSearch and save a vector index in your preferred storage system.
The following table presents our benchmarking results, comparing query latency with the loading layer (candidate) to the baseline.
| Engine | Metric | Description | Baseline | Candidate |
|---|---|---|---|---|
| Faiss | Average query latency | The time taken to process a vector search query. | 3.5832 ms | 3.83349 ms |
| Faiss | p99 query latency | The p99 latency for processing a vector search query. | 22.1628 ms | 23.8439 ms |
| Faiss | Total Young Gen JVM GC time | The time spent on Young GC in the JVM. | 0.338 sec | 0.342 sec |
The results demonstrate that replacing the file-based API with Lucene’s IndexInput maintains search performance while enabling broader storage compatibility.
Configuring searchable snapshots for vector search
With the loading layer in place, you can now perform vector searches directly on remote snapshots. At a high level, you’ll create a vector index, take a snapshot of the index, and run a vector search on the snapshot. The following diagram illustrates these steps.
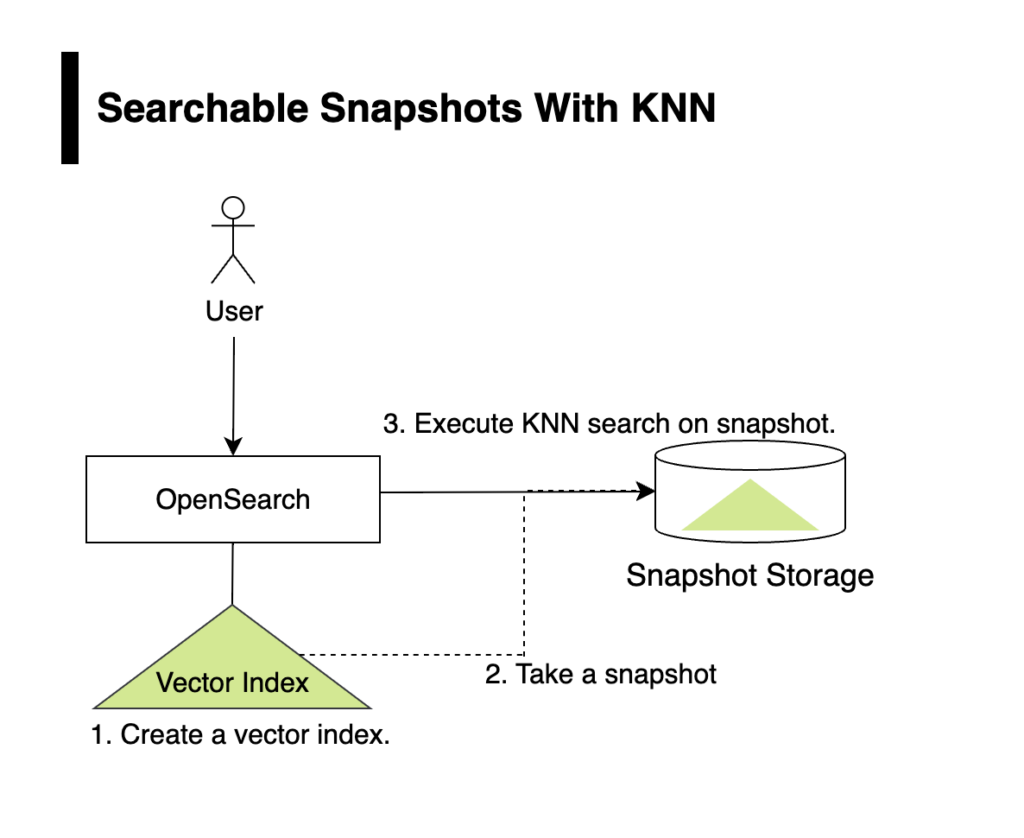
Follow these steps to configure searchable snapshots.
Prerequisites
Configure your cluster for searchable snapshots. For detailed steps, see Configuring a node to use searchable snapshots.
Step 1: Create a local index
Use the following request to create a local vector index:
PUT /knn-index/
{
"settings": {
"index": {
"knn": true
}
},
"mappings": {
"properties": {
"my_vector": {
"type": "knn_vector",
"dimension": 2
}
}
}
}
Step 2: Ingest data
Ingest some data into the index:
POST _bulk?refresh
{ "index": { "_index": "knn-index", "_id": "1" } }
{ "my_vector": [1.5, 2.5], "price": 12.2 }
{ "index": { "_index": "knn-index", "_id": "2" } }
{ "my_vector": [2.5, 3.5], "price": 7.1 }
{ "index": { "_index": "knn-index", "_id": "3" } }
{ "my_vector": [3.5, 4.5], "price": 12.9 }
{ "index": { "_index": "knn-index", "_id": "4" } }
{ "my_vector": [5.5, 6.5], "price": 1.2 }
{ "index": { "_index": "knn-index", "_id": "5" } }
{ "my_vector": [4.5, 5.5], "price": 3.7 }
Step 3: Query the local index
Query the local index to ensure that it’s configured correctly:
POST knn-index/_search
{
"query": {
"knn": {
"my_vector": {
"vector": [2, 3],
"k": 2
}
}
}
}
The response returns the vectors closest to the query vector:
{
"took": 16,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.6666667,
"hits": [
{
"_index": "knn-index",
"_id": "1",
"_score": 0.6666667,
"_source": {
"my_vector": [
1.5,
2.5
],
"price": 12.2
}
},
{
"_index": "knn-index",
"_id": "2",
"_score": 0.6666667,
"_source": {
"my_vector": [
2.5,
3.5
],
"price": 7.1
}
}
]
}
}
Step 4: Take a snapshot
Take a snapshot of the index. For detailed steps, see Take and restore snapshots. After taking the snapshot, delete the knn-index so that it is no longer available locally.
Step 5: Create a searchable snapshot index from the snapshot
Use the following request to restore the original index from the snapshot in order to create a searchable snapshot index
POST _snapshot/<SNAPSHOT_REPO>/<SNAPSHOT_NAME>/_restore
{
"storage_type": "remote_snapshot",
"indices": "knn-index"
}
To verify the successful creation of the searchable snapshot index, use the following request:
GET /_cat/indices
For more information, see Create a searchable snapshot index.
Step 6: Run a vector search query
Run a vector search query on the searchable snapshot index:
POST knn-index/_search
{
"query": {
"knn": {
"my_vector": {
"vector": [2, 3],
"k": 2
}
}
}
}
The query returns the same results as the local index query in Step 3.
Conclusion
By introducing an I/O layer that uses Lucene’s Directory abstraction, we eliminated the native engines’ dependency on file-based APIs that limit storage to local file systems. This change allows the vector engine to read graph data structures from any storage system supported by OpenSearch’s Directory implementation. Our extensive benchmarking tests confirmed that this change maintains the search performance of the original file-API-based approach. Notably, we observed no regression in search times after the graphs were loaded into memory (graph loading is a one-time operation for a properly scaled cluster).
With this new read interface, you can now use vector indexes with any OpenSearch Directory implementation. This added flexibility makes it possible to store vector data in remote storage solutions like Amazon Simple Storage Service (Amazon S3).
Next steps
In version 2.18, we introduced the ability to use vector search queries with Lucene’s Directory and IndexInput classes. Looking ahead, version 2.19 will expand this functionality to the native index creation process. Specifically, the k-NN plugin will begin using the IndexOutput class to write graph files directly to segments. For more information, see this GitHub issue.
Additionally, the k-NN plugin now having the ability to stream vector data structure files presents an opportunity for partial loading of these files. This enhancement will reduce memory pressure on the cluster and deliver better price-performance, especially under high-stress conditions. For more information, see this GitHub issue.



