
Extensions is a new experimental feature in OpenSearch 2.9 that allows you to extend OpenSearch and independently scale workloads without impacting cluster availability. In this blog post, we will introduce extensions and compare them to plugins. Using a 36-node cluster running a machine learning algorithm that performs high-cardinality anomaly detection, we’ll demonstrate how we have achieved a cost reduction of 33% per data node, with performance matching that of a plugin and the only added cost of one extension node.
The old way: Plugins
OpenSearch is a fork of Elasticsearch 7.10, which offered extending features through plugins. Until now, plugins were the best way to extend features in OpenSearch, and we’ve written a blog post to help you understand how they work. The OpenSearch project currently maintains 17 plugins, and we have learned a lot developing and operating them at scale over the last two years. In such, we’ve encountered many bottlenecks in the existing plugin architecture.
Plugins are class-loaded into memory during OpenSearch bootstrap and therefore run within the OpenSearch process. This leads to the following three architectural problems:
- Plugins require rigid version compatibility with OpenSearch. Every patch version change in OpenSearch core requires the plugin to be recompiled and rereleased.
- Plugins are not isolated, so they can fatally impact the OpenSearch cluster and cannot scale independently.
- Having to manage the dependencies of all the components together makes it challenging to include 20+ plugins in a single product distribution.
The new way: Extensions
Unlike plugins, extensions run as independent processes or on a remote node, are isolated, and have cleaner, well-defined interfaces that interact with OpenSearch core. These interfaces are versioned (they follow semantic versioning) and work across minor and patch versions, providing the future possibility of being compatible with multiple major versions of OpenSearch.
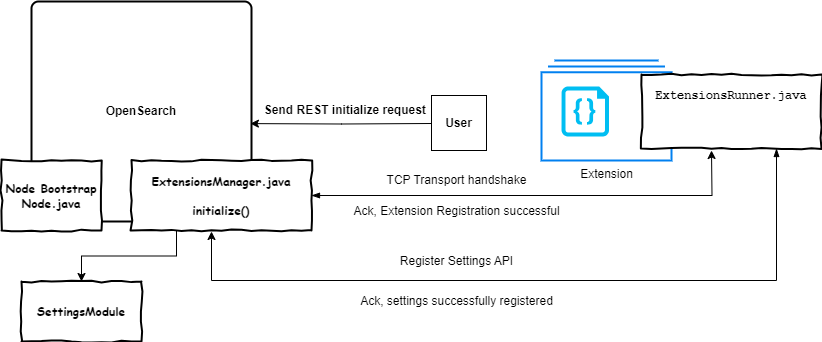
The extensions architecture is illustrated in the following figure. For details, see extension design documentation.
Experimental SDK launch
The first step on our extensibility roadmap is to launch an SDK that makes the experience of extending OpenSearch easier than with plugins. Today we are launching a Java version, opensearch-sdk-java, that works with OpenSearch 2.9 and later. To learn how to turn on the experimental extensions feature, see the Developer Guide.
The extension interfaces are compatible across minor and patch versions of OpenSearch, therefore there’s no need to recompile, redeploy, or reinstall your extension when you upgrade to the next version of OpenSearch 2.10. These APIs currently include the capability to expose a REST interface in your extension and ship with client libraries to interact with data in your OpenSearch cluster.
The first version of the SDK, v0.1.0, is available in Maven under org.opensearch.sdk. Start with the developer documentation to build your first extension.
How did we write our first extension?
We selected the Anomaly Detection plugin as the first plugin to migrate to an extension because of its combination of complexity and performance sensitivity.
Technically, Anomaly Detection wasn’t our first extension. Like anyone exploring a new space, we created a “Hello World” example to show how easy it was to get started and to demonstrate the usage of the basic interfaces without the complexity of a real-world application. We then wanted to face the challenges of migrating a full-fledged, production-ready plugin ourselves.
Most plugins make requests to OpenSearch for user data or cluster state. Our extensions needed a REST client to match this functionality. Our initial choice was the OpenSearch Java client. As a robust, spec-based, auto-generated client, it seemed to be an ideal choice, especially because of our future plan to port the SDK to other programming languages that all have similar clients. This is still the preferred client for new extension development. However, for the experimental release, Anomaly Detection was very dependent on the existing NodeClient API, and we found ourselves rewriting too much code.
The Java high-level REST client, currently part of OpenSearch core, had a nearly identical interface but has been proposed for deprecation. We chose to use it for the early migration work and decided not to switch the client until it has been removed in OpenSearch 3.0 or 4.0. This allowed us to minimize the amount of work and to quickly migrate all APIs by adding a handful of wrapper classes.
While trying to minimize work, we did implement several inefficient operations. The Anomaly Detection plugin made frequent use of the OpenSearch cluster state object. Because cluster state is always up to date in OpenSearch core, it proved useful for fetching information efficiently. However, in an extension environment, retrieving the entire cluster state multiple times for the purposes of, for example, finding out whether an index or alias existed, proved to be a waste of resources and led to many API timeouts (creating a detector in our initial prototype often took nearly 13 seconds). To fix this, we used existing settings and targeted calls to the Index API and Cluster API to bring bootstrap time down to a fraction of a second.
For implementation details and to examine the differences between Anomaly Detection as a plugin and as an extension, see the code for Anomaly Detection as an extension.
Performance testing
To benchmark high-cardinality Anomaly Detection (HCAD) as an extension, we have replicated the setup described in this blog post, replacing 36 r5.2xlarge data nodes with 28 r5.2xlarge data nodes (at the same cost), plus a single r5.16xlarge instance running the Anomaly Detection extension. We analyzed 1,000 historical time periods with 1,000 entities to generate 1 million results:
GET /_extensions/_ad/detectors/results/_search
{
"query": {
"range": {
"execution_start_time": {
"gte": 1687456200000,
"lte": 1687456260000
}
}
},
"track_total_hits": true
}
{
...
"hits": {
"total": {
"value": 1000000,
"relation": "eq"
},
...
...
}
The plugin limits these analysis rates to ensure stable cluster performance. After some fine-tuning (we increased simultaneous detector tasks from 10 to 96 and reduced the batch task piece interval from 5 to 3 seconds), the extension version of Anomaly Detection was able to successfully complete this analysis in 55 seconds. This isn’t quite an apples-to-apples comparison because the test in the previously mentioned blog post involved 1 million smaller models x 1 time slice each to generate 1 million results (we needed more time to implement support for real-time anomaly detection in the extension). However, we believe that we should be able to support 1M models on a single node or on a small number of nodes once extensions are capable of running in that environment.
Because our extension ran on a remote node, we did observe an expected increase in API call latency. For example, the start/stop detector call went from 50–100ms to 200–300ms. These calls are marginal CRUD operations that are used to set up Anomaly Detection. The following figure provides a latency comparison between extensions and plugins. For more information, see Performance testing for the Anomaly Detection extension.
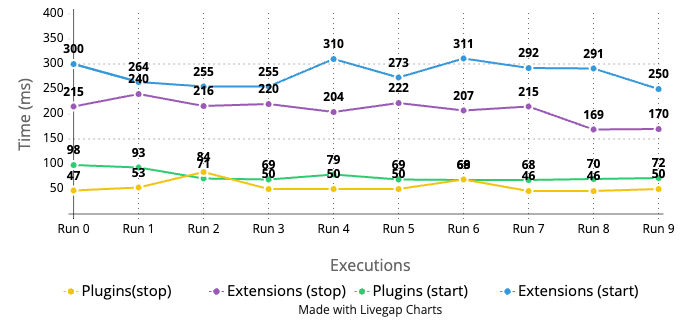
Improving performance
We proved that upgrading Anomaly Detection from a plugin to an extension could match existing performance for end users. But we believe that we can do even better in the following three ways.
1. Use a cheaper cluster
We found that by rewriting Anomaly Detection as an extension, we could reduce the cost of our cluster and still meet the same performance bar. Because Anomaly Detection no longer runs on data nodes, we were able to replace all memory-optimized r5.2xlarge nodes with general-purpose c5.2xlarge nodes, resulting in a 33% cost reduction per data node for historical analysis, with the additional cost of 1 extension node.
We were also able to further decrease the number of data nodes in order to optimize searching data and indexing results. For example, because most data nodes in the original performance benchmark had insignificant usage other than indexing results, we tested a cluster with only 24 c5.2xlarge data nodes along with 1x r5.16xlarge extension node, a further 33% reduction. We believe that with further experimentation and fine-tuning, you can find an even more optimal mix, depending on other resource requirements for the cluster.
2. Increase indexing throughput
While we have not run this experiment, we believe you can further independently fine-tune the cluster by increasing sharding and achieve better throughput when indexing Anomaly Detection results.
3. Increase the historical results generation rate
Anomaly Detection’s historical HCAD restricts the rate of historical time period results, limits the use of Anomaly Detection to half the heap, and sets the maximum for detection at 10 simultaneous threads to protect the cluster from being maxed out. You can raise these limits by adding more CPUs or RAM, swapping space with SSDs independently from the rest of the cluster, or horizontally scaling extension nodes.
Conclusion
Extensions save costs and improve performance by right-sizing all resources to the task being performed. In our test, we did not need memory-optimized servers for the whole cluster to perform historical Anomaly Detection and therefore could achieve a 33% cost reduction per data node.
As a plugin, Anomaly Detection shares CPU and memory with OpenSearch I/O and must limit its own resource consumption in order to ensure the cluster’s stability. For example, in the Anomaly Detection plugin HCAD tests, models were limited to using half of the heap, which itself was half of the node’s memory. In the Anomaly Detection extension scenario, it was possible to scale the heap to consume most of the server’s memory and fully utilize 64 vCPUs dedicated only to Anomaly Detection tasks.
Other existing plugins that could similarly benefit from this model include all plugins that have memory- or CPU-bound concerns, such as ML Commons, k-NN, and Reporting. This new technology also allows implementing new resource-heavy extensions, such as reranking, data transformation, big data processing, or video indexing.
Next steps
We are thrilled with the progress we have made with extensibility so far and with the early performance benchmarking results. Moving forward, in the short term we will shift our focus to using the learnings from the Extensibility project to enable extensibility in our OpenSearch Machine Learning (ML) offerings. The goal is to deliver a spec-based application framework where users will be able to create no-code ML-powered applications in OpenSearch and ultimately deliver a simple one-click way for users to test, build, and deploy ML-powered applications using OpenSearch. Additionally, before we commit to releasing this experimental feature and the SDK as generally available, we would like your feedback. After reading extension documentation, try implementing an experimental extension and give us feedback by posting in the OpenSearch forum or opening issues in the opensearch-sdk-java repo. We can’t wait to hear from you!






