
OpenSearch 3.1 introduces the system ingest pipeline, a new capability designed specifically for plugin developers. It lets you automatically process documents during ingestion by defining system ingest processors that run based on fields or parameters in the index mapping. This allows you to embed processing logic directly into your plugin without requiring users to manually configure ingest pipelines.
Previously, if you built a custom ingest processor, users had to set up and manage the pipeline themselves. With system ingest pipelines, that burden shifts to the plugin, enabling a smoother out-of-the-box experience for users and reducing configuration complexity.
System ingest pipeline compared to standard ingest pipeline
In OpenSearch, a standard ingest pipeline is defined using the Ingest Pipeline API. Users must manually configure the pipeline and specify it in the index settings or in each indexing request.
A system ingest pipeline works similarly: it applies one or more processors during document ingestion. However, it’s not configured by users. Instead, OpenSearch generates the pipeline automatically based on the index mapping and the system ingest processor factories you register in your plugin.
The following table highlights the key differences between standard and system ingest pipelines in OpenSearch.
| Pipeline type | How it’s defined | How it’s triggered | How to disable it |
|---|---|---|---|
| Standard ingest pipeline | Manually defined by users using the Ingest Pipeline API | Specified in index settings (as default or final) or passed as a parameter in the indexing request | Omit references to the pipeline in index settings or indexing requests. |
| System ingest pipeline | Automatically generated by OpenSearch based on index mappings and plugin-registered processor factories | Triggered automatically when the index mapping includes fields or parameters recognized by the processor factory | Set the cluster.ingest.system_pipeline_enabled cluster setting to false. |
How it works
When OpenSearch receives a document indexing request, it determines which ingest pipelines to apply. Starting with OpenSearch 3.1, this process includes resolving a system ingest pipeline based on the index mapping of the target index.
To enable system ingest pipelines, you need to register a system ingest processor and its associated factory. The factory evaluates the index mapping and decides whether to create a processor. If applicable, the processor is added to the automatically generated system ingest pipeline.
The following diagram illustrates how OpenSearch resolves the ingest pipeline for an indexing request.
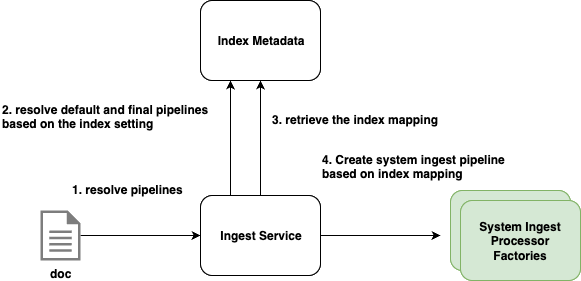
Pipeline execution and update behavior
To optimize performance, OpenSearch caches the generated system ingest pipeline for each index. This cache is automatically invalidated when the index mapping changes, ensuring that pipelines remain consistent with the latest mapping.
During indexing, OpenSearch executes all applicable pipelines in order. The system ingest pipeline always runs after the default and final pipelines.
Ingest pipelines and update operations
In OpenSearch, you can update existing documents using either single update or bulk update operations. These updates typically include a partial document that specifies only the fields you want to change.
Update operations interact with ingest pipelines in the following ways:
-
Single updates always trigger the default and final ingest pipelines.
-
Bulk updates do not trigger any ingest pipelines on the partial document by default, with the following exceptions:
- If
doc_as_upsertis set totrue, the partial document triggers the default and final pipelines. - If an
upsertdocument is provided, ingest pipelines are executed on that document.
- If
Improving the configurability of this behavior is under discussion in this proposal.
System ingest pipelines behave differently: they are always applied to all update operations, including both single and bulk updates. This ensures that your system processors can maintain or regenerate derived fields even when updates occur after initial indexing. For example, the system_ingest_processor_semantic_field processor (introduced in the Neural Search plugin in OpenSearch 3.1) uses system pipelines to generate text embeddings at ingest time and automatically regenerate them when their source fields are updated.
As a plugin developer, ensure that your system ingest processors handle partial documents correctly and include update scenarios in your unit and integration tests. Otherwise, your processor may fail when processing updates.
Building a custom system ingest processor
You can extend the system ingest pipeline by creating and registering a custom system ingest processor. To build a custom system ingest processor, follow these steps:
- Create a system ingest processor: Create a system ingest processor class that extends AbstractBatchingSystemProcessor. Define the logic for transforming incoming documents.
- Create a system ingest processor factory: Implement a factory that extends SystemIngestProcessor.Factory. This factory determines whether the processor should be applied based on the index mapping.
- Register the processor factory: Register the factory in your plugin by overriding the
getSystemIngestProcessorFactories()method.
Follow these complete implementation steps to create and register a system ingest processor in a plugin.
Step 1: Create a system ingest processor
/**
* This system ingest processor will add a field to the ingest doc.
*/
public class ExampleSystemIngestProcessor extends AbstractBatchingSystemProcessor {
/**
* The type of the processor.
*/
public static final String TYPE = "example_system_ingest_processor";
/**
* Constructs a new ExampleSystemIngestProcessor
* @param tag tag of the processor
* @param description description of the processor
* @param batchSize batch size which is used to control each batch how many docs the processor can process
*/
protected ExampleSystemIngestProcessor(String tag, String description, int batchSize) {
super(tag, description, batchSize);
}
@Override
protected void subBatchExecute(List<IngestDocumentWrapper> ingestDocumentWrappers, Consumer<List<IngestDocumentWrapper>> handler) {
// Add your logic to batch process the docs
handler.accept(ingestDocumentWrappers);
}
@Override
public void execute(IngestDocument ingestDocument, BiConsumer<IngestDocument, Exception> handler) {
super.execute(ingestDocument, handler);
}
@Override
public IngestDocument execute(IngestDocument ingestDocument) {
// Add your logic to process the doc
return ingestDocument;
}
@Override
public String getType() {
return TYPE;
}
}
Step 2: Create a system ingest processor factory
/**
* A factory to create the example system ingest processor
*/
public class ExampleSystemIngestProcessorFactory extends AbstractBatchingSystemProcessor.Factory {
/**
* The type of the factory.
*/
public static final String TYPE = "example_system_ingest_processor_factory";
/**
* A default batch size.
*/
private static final int DEFAULT_BATCH_SIZE = 10;
/**
* Constructs a new ExampleSystemIngestProcessorFactory
*/
protected ExampleSystemIngestProcessorFactory() {
super(TYPE);
}
@SuppressWarnings("unchecked")
@Override
protected AbstractBatchingSystemProcessor newProcessor(String tag, String description, Map<String, Object> config) {
// Currently we only support index mapping data but in future we can support
// using more info to control your system ingest processor
final List<Map<String, Object>> mappings = new ArrayList<>();
final Object mappingFromIndex = config.get(INDEX_MAPPINGS);
final Object mappingFromTemplates = config.get(INDEX_TEMPLATE_MAPPINGS);
if (mappingFromTemplates instanceof List) {
mappings.addAll((List<Map<String, Object>>) mappingFromTemplates);
}
if (mappingFromIndex instanceof Map) {
mappings.add((Map<String, Object>) mappingFromIndex);
}
// If no config we are not able to create a processor so simply return a null to show no processor created
if (mappings.isEmpty()) {
return null;
}
// Add your logic to decide if we should create the system processor
// and how to create it
return new ExampleSystemIngestProcessor(tag, description, DEFAULT_BATCH_SIZE)
}
}
Step 3: Register the processor factory
/**
* Example plugin that implements a custom system ingest processor.
*/
public class ExampleSystemIngestProcessorPlugin extends Plugin implements IngestPlugin {
/**
* Constructs a new ExampleSystemIngestProcessorPlugin
*/
public ExampleSystemIngestProcessorPlugin() {}
@Override
public Map<String, Processor.Factory> getSystemIngestProcessors(Processor.Parameters parameters) {
return Map.of(ExampleSystemIngestProcessorFactory.TYPE, new ExampleSystemIngestProcessorFactory());
}
}
Summary
System ingest pipelines simplify document processing by automatically generating pipelines based on index mappings and registered processor factories. This removes the need for manual configuration and ensures that custom logic, such as generating embeddings with the Neural Search plugin, runs consistently during ingestion. Unlike standard pipelines, system pipelines also apply to partial updates, making them especially useful for machine learning and search use cases.
What’s next
Building on the foundation introduced in OpenSearch 3.1, we’re planning to implement enhancements to system ingest pipelines that will offer more flexibility and better developer tooling. The following improvements are under discussion:
- Configurable execution conditions: Allows you to specify when the pipeline should run—for example, only on create, update, or full document replacement operations.
- Simulation support: Allows you to simulate pipeline execution on sample documents to validate behavior and troubleshoot issues during development.
- Explain API for system ingest pipelines: Provides a way to view the generated pipeline for an index, including processor details and their originating plugin or factory. This helps you understand how documents are transformed during ingestion.


