
If you’re an OpenSearch user, you probably often run OpenSearch queries to retrieve the most recent logs, metrics, or events—for example, fetching the latest 100 error logs from the past 24 hours or identifying system metrics over the last 7 days for anomaly detection. These queries often include range filters on time or numeric fields (for example, @timestamp > now-1d), sorting (typically descending), or match_all queries to power dashboard visualizations and alerts. Because these are used interactively or in streaming dashboards, latency and efficiency are critical for this experience.
These queries are typically non-scoring and are often used as the first step in visualizing time-series or event-based data. For example, you may sort results by a timestamp field in descending order to fetch the latest events, or you may sort them in ascending order to analyze the earliest entries within a given time frame. While Lucene introduced an optimization (IndexOrDocValuesQuery) that intelligently uses doc values instead of scanning the entire index when running non-scoring range queries, the default algorithm still traverses all segments and often scores more documents than necessary. This results in unnecessarily processing a large set of documents, while you actually require only a small subset of top results (for example, the first 50 or 100 hits).
To address this, we introduced the Approximation Framework, which applies early termination logic during BKD tree traversal for eligible queries. The idea is to override the default PointRangeQuery and inject a custom IntersectVisitor that stops once the requested number of hits is collected, significantly reducing query latency. This approach preserves result correctness while avoiding unnecessary work, making it a valuable optimization for high-volume time-based or event-based workloads.
Starting with version 3.0.0, OpenSearch includes the Approximation Framework as a GA feature.
Overview
The OpenSearch Approximation Framework is a query optimization technique that implements custom BKD tree traversal with early termination. The key insight is that for queries with a size limit, the Approximation Framework doesn’t need to visit all matching documents; it can stop as soon as it has collected enough results.
The framework creates custom versions of standard Lucene queries (like PointRangeQuery) that have the following features:
- Early termination of the BKD tree traversal once the size limit is reached.
- Returning exact results, so the documents returned are always correct matches.
- Optimized traversal order based on sort requirements.
Supported sample query shapes and types
The Approximation Framework currently benefits the following query patterns, particularly when track_total_hits is not set to true and no aggregations are involved. The framework supports all numeric types, including int, long, float, double, half_float, unsigned_long, and scaled_float.
Range queries
{
"query": {
"range": {
"@timestamp": {
"gte": "2023-01-01T00:00:00",
"lt": "2023-01-03T00:00:00"
}
}
}
}
The framework traverses the BKD tree and stops once the requested size is met.
Match all + sort (ASC/DESC)
{
"query": { "match_all": {} },
"sort": [{ "@timestamp": "desc" }]
}
The query is automatically rewritten into a bounded range query with early termination.
Range + sort (ASC/DESC)
{
"query": {
"range": {
"@timestamp": {
"gte": "2023-01-01T00:00:00",
"lte": "2023-01-13T00:00:00"
}
}
},
"sort": [{ "@timestamp": "asc" }]
}
The framework optimizes left-to-right (ASC) or right-to-left (DESC) traversal to find the top size documents quickly.
BKD walk (custom BKD tree traversal)
Instead of using Lucene’s standard tree traversal, which visits all matching documents, the framework implements custom intersectLeft and intersectRight methods with sort-aware traversal, which ensures collection of the correct top-N documents without visiting unnecessary nodes.
ASCsort: UsesintersectLeftto traverse from the smallest to the largest values. This method is the default and is used for plain range queries.DESCsort: UsesintersectRightto traverse from the largest to the smallest values.
Example: Traversal with approximation
The following example illustrates a BKD tree traversal with approximation.
intersectLeft traversal
The following diagram illustrates how the Approximation Framework performs a BKD tree traversal for a query with the following parameters:
size= 1100range= 10:00 – 10:30
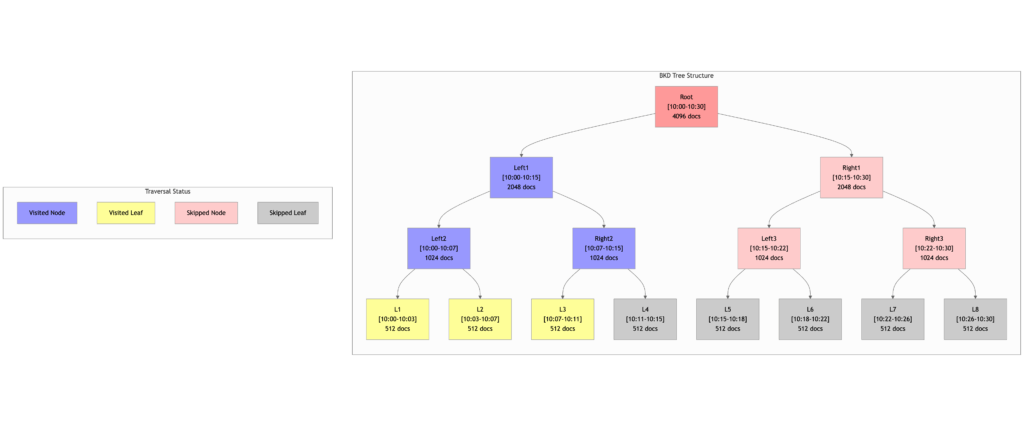
Because the goal is to collect only 1,100 matching documents, the traversal short-circuits once this threshold is met.
Traversal path
The tree is traversed as follows:
Root → Left1 → Left2 → L1 → L2 → Right2 → L3 → Done
- Nodes like
Right1,Left3,Right3and all their children (L5–L8) are entirely skipped because enough documents were already collected from the left side of the tree. - This demonstrates how the framework avoids visiting unnecessary subtrees, reducing query latency while still returning accurate top-N results.
intersectRight traversal
The following diagram illustrates how the Approximation Framework performs a descending sort (SortOrder.DESC) traversal for a query with the following parameters:
size= 1100range= 10:00 – 10:30
Because the query is sorted in descending order, the traversal prioritizes the rightmost (newest) values first.
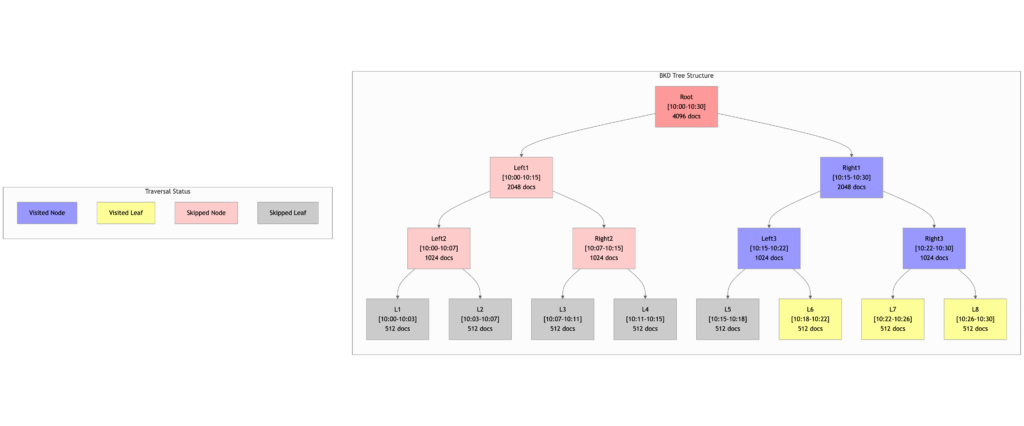
Traversal path
The tree is traversed as follows:
Root → Right1 → Right3 → L8 → L7 → Left3 → L6 → Done- As soon as the traversal collects enough documents (≥1,100), it terminates early, skipping the remaining subtrees on the left.
- Nodes like
Left1,Left2,Right2, and their respective leaf children are entirely skipped because they fall outside the descending priority range or are no longer needed.
Performance: Benchmarking tests and results
While numeric sort, range, and match_all queries have seen significant performance improvements overall, the following are specific scenarios highlighting improvements in P90 latencies.
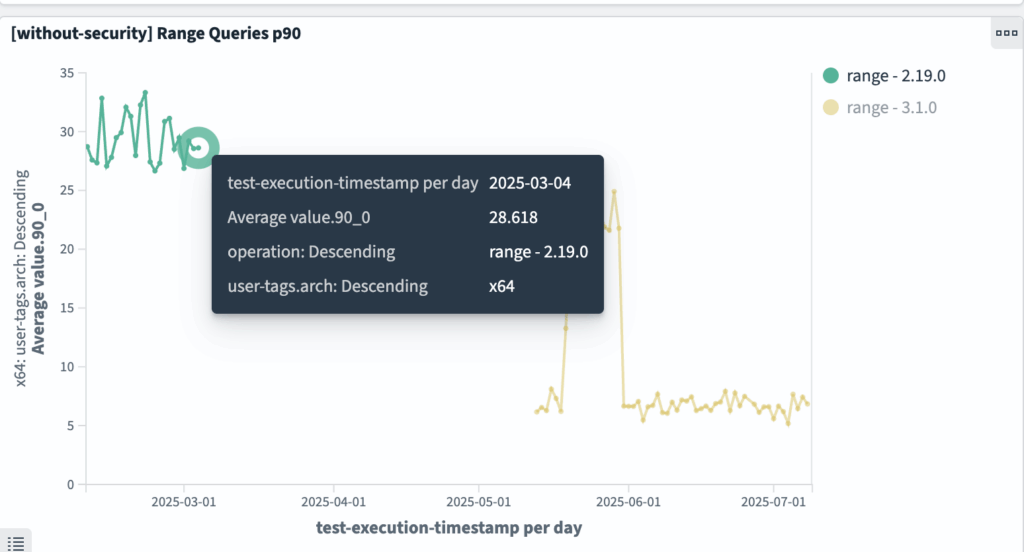
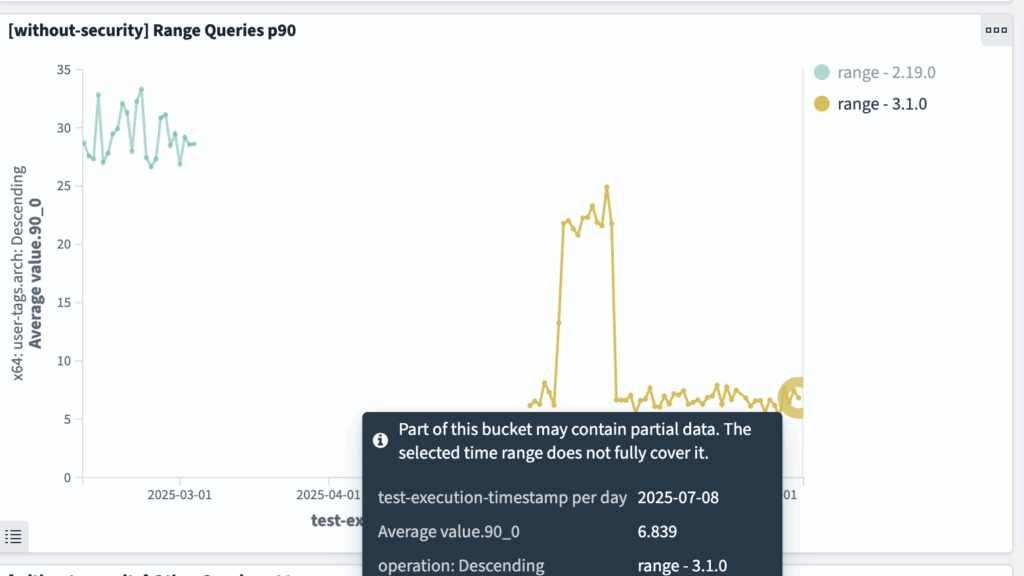
big5: range query
range queries have improved from ~28 ms to ~6 ms, as shown in the following graphs.
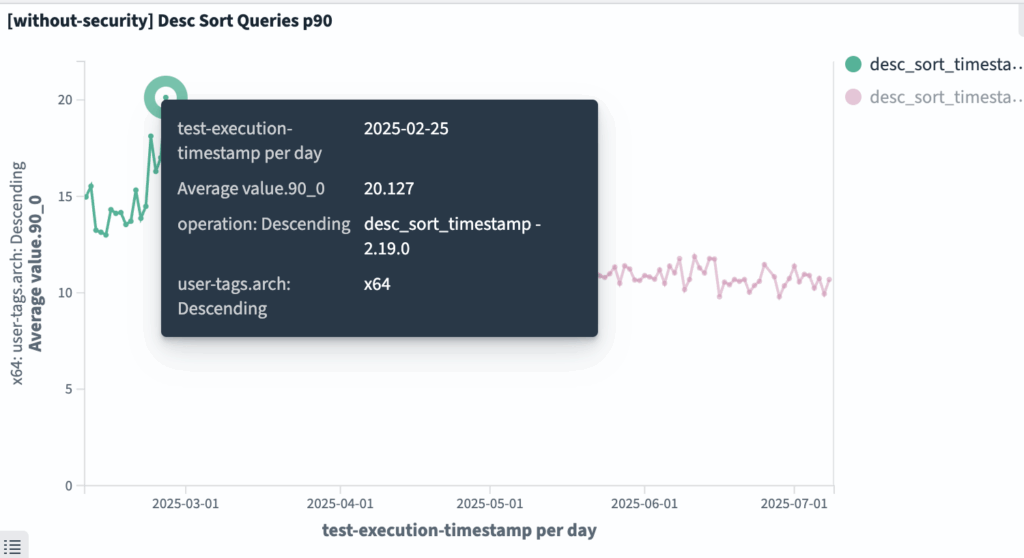
big5: desc_sort_timestamp query
desc_sort_timestamp queries have improved from ~20 ms to ~10 ms.
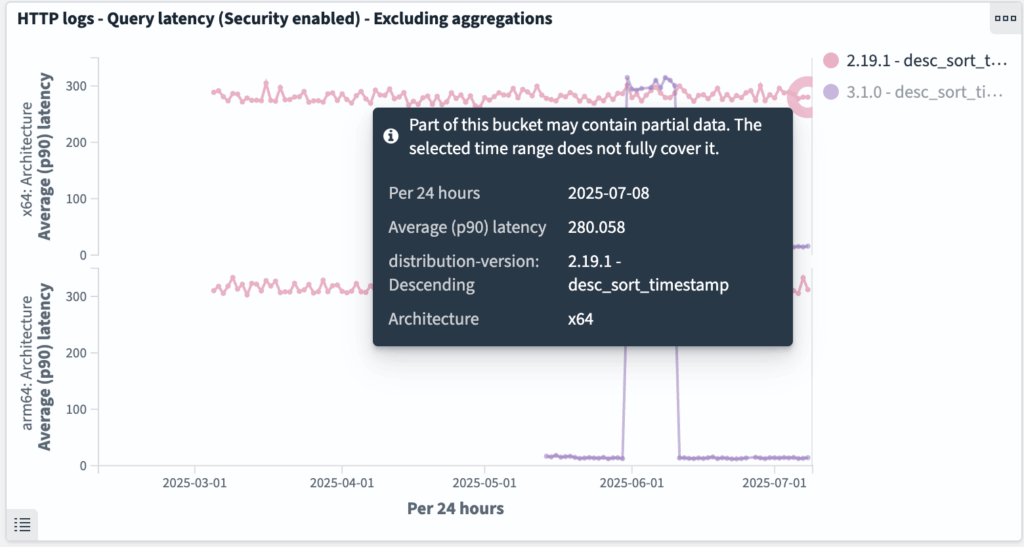
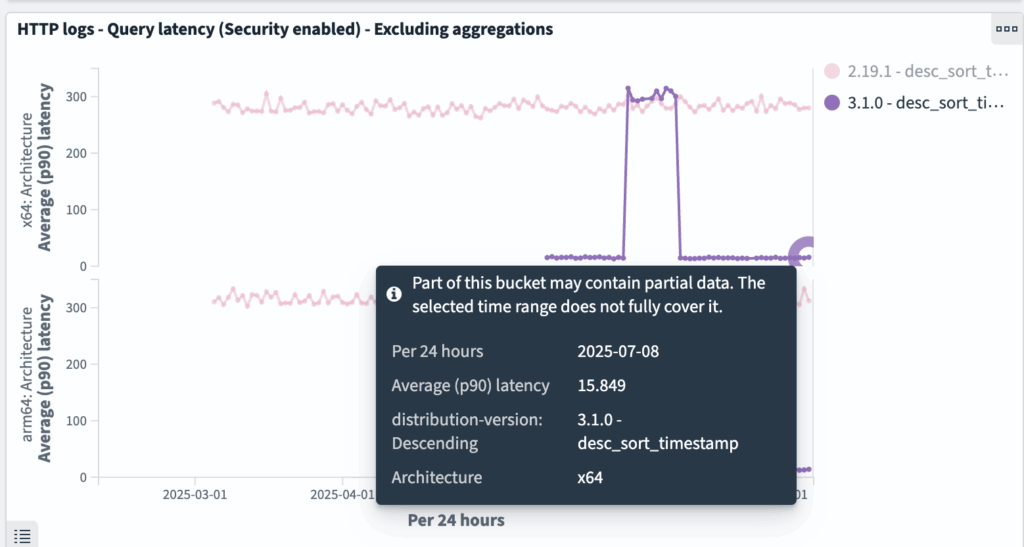
http_logs: desc_sort_timestamp query
desc_sort_timestamp queries have improved from ~280 ms to ~15 ms, as shown in the following graphs.
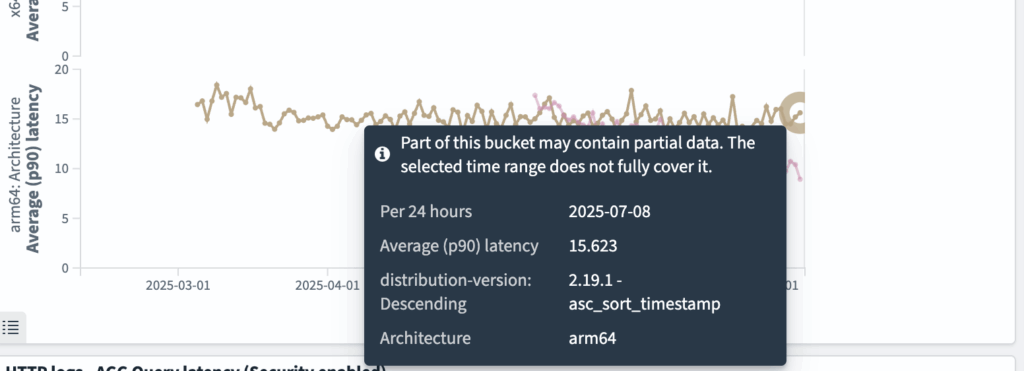
http_logs: asc_sort_timestamp query
asc_sort_timestamp queries have improved from ~15 ms to ~8 ms, as shown in the following graphs.
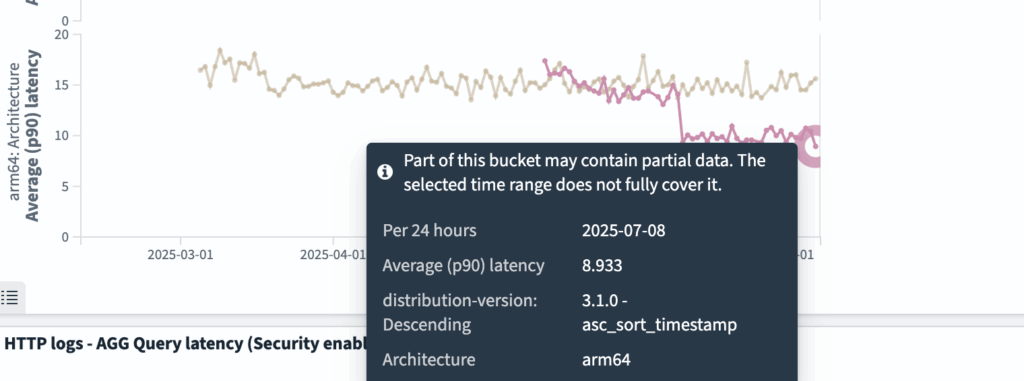
Additional improvements
Further improvements, particularly in sort query performance, were observed in the OpenSearch 3.1 release and are shared in detail in the 3.1.0 release issue.
This result comes from a single-segment test for desc_sort_timestamp. According to this comment, a force merge to a single segment with an optimized custom BKD walk (intersectRight) reduced P90 latency dramatically from 2,111 ms to 6.1 ms. This improvement is made possible by the Approximation Framework, which enables early termination during BKD traversal, efficiently collecting the most relevant documents with minimal overhead.
As shown in this comment, which captures benchmark results from the development phase, several query types showed significant improvements: http_logs: desc_sort_size improved by more than 80%, http_logs: desc_sort_timestamp improved by more than 80%, and asc_sort_timestamp achieved more than an 80.55% performance improvement.
Upcoming improvements
The high-level META issue contains the next set of enhancements related to the Approximation Framework.
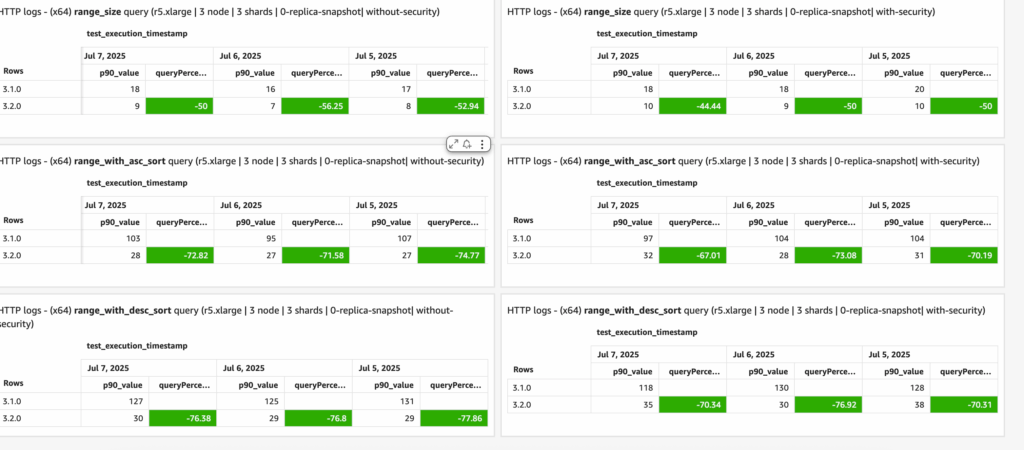
The following are some of the upcoming improvements planned for the 3.2.0 release, including extending the Approximation Framework to support all numeric types (see this related PR). Additional performance gains have also been observed in range and sort queries, particularly when tested on the skewed http_logs dataset, as shown in the following diagram.
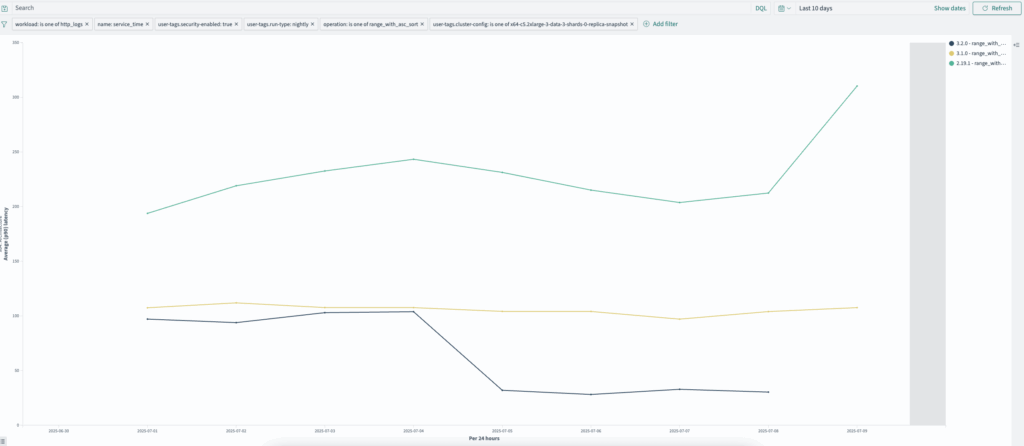
http_logs: range_with_asc_sort (2.19.1–3.2.0)
range_with_asc_sort queries have improved from ~300 ms to ~30 ms, as shown in the following graph.
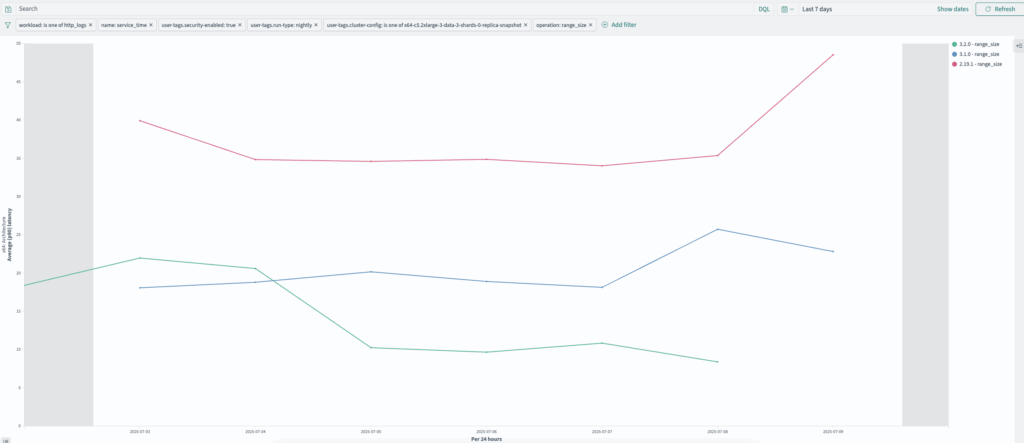
http_logs: range_size (2.19.1–3.2.0
range_size queries have improved from ~48 ms to ~8 ms, as shown in the following graph.
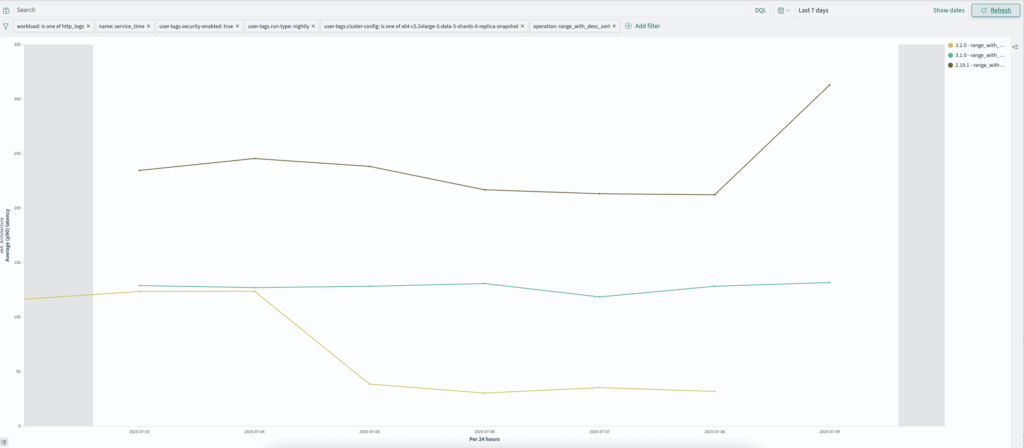
http_logs: range_with_desc_sort (2.19.1–3.2.0)
range_with_desc_sort queries have improved from ~312 ms to ~31 ms, as shown in the following graph.
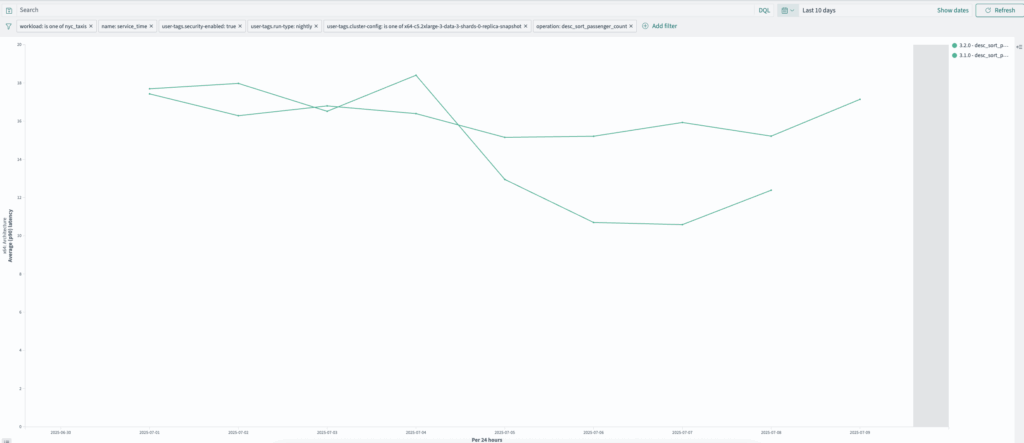
nyc_taxis: desc_sort_passenger_count (3.1.0–3.2.0)
desc_sort_passenger_count queries have improved from ~17 ms to ~12 ms, as shown in the following graph.
Additional query shapes and types under exploration
We’re exploring several promising extensions of the Approximation Framework to additional query types. Here are the types of queries we can target in future releases.
Term query
The proof of concept for extending the framework to top-level term queries on numeric fields has shown a decrease of approximately 25% in latency on the http_logs dataset. See these related benchmark results and this related issue for more information.
Boolean query
This related issue and RFC provide information about implementing ApproximateBooleanQuery, which can optimize both single- and multi-clause boolean queries, as a proof of concept.
Numeric search_after queries
During a proof-of-concept effort outlined in this issue, we observed significant improvements in numeric queries using the search_after parameter, which is designed for efficient deep pagination of large datasets. In tests with asc_sort_with_after_timestamp, the P90 latency dropped from 194.828 ms to 8.459 ms, and it dropped from 188.037 ms to 7.09 ms for desc_sort_with_after_timestamp.



