
Inference processors, such as text_embedding, text_image_embedding, and sparse_encoding, enable the generation of vector embeddings during document ingestion or updates. Today, these processors invoke model inference every time a document is ingested or updated, even if the embedding source fields remain unchanged. This can lead to unnecessary compute usage and increased costs.
This blog post introduces a new inference processor optimization that reduces redundant inference calls, lowering costs and improving overall performance.
How the optimization works
The optimization adds a caching mechanism that compares the embedding source fields in the updated document against the existing document. If the embedding fields have not changed, the processor directly copies the existing embeddings into the updated document instead of triggering new inference. If the fields differ, the processor proceeds with inference as usual. The following diagram illustrates this workflow.
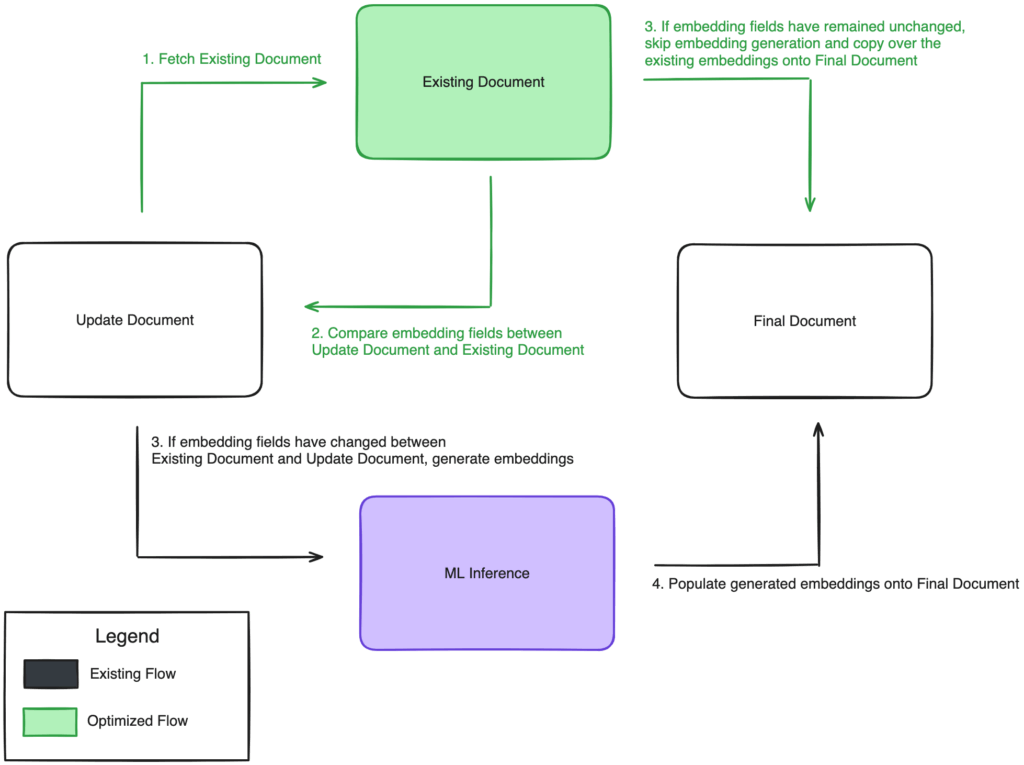
This approach minimizes redundant inference calls, significantly improving efficiency without impacting the accuracy or freshness of embeddings.
How to enable the optimization
To enable this optimization, set the skip_existing parameter to true in your ingest pipeline processor definition. This option is available for text_embedding, text_image_embedding, and sparse_encoding processors. By default, skip_existing is set to false.
Text embedding processor
The text_embedding processor generates vector embeddings for text fields, typically used in semantic search.
- Optimization behavior: If
skip_existingistrue, the processor checks whether the text fields mapped infield_maphave changed. If they haven’t, inference is skipped and the existing vector is reused.
Example pipeline:
PUT /_ingest/pipeline/optimized-ingest-pipeline
{
"description": "Optimized ingest pipeline",
"processors": [
{
"text_embedding": {
"model_id": "<model_id>",
"field_map": {
"text": "<vector_field>"
},
"skip_existing": true
}
}
]
}
Text/image embedding processor
The text_image_embedding processor generates combined embeddings from text and image fields for multimodal search use cases.
- Optimization behavior: Because embeddings are generated for combined text and image fields, inference is skipped only if both the text and image fields mapped in
field_mapare unchanged.
Example pipeline:
PUT /_ingest/pipeline/optimized-ingest-pipeline
{
"description": "Optimized ingest pipeline",
"processors": [
{
"text_image_embedding": {
"model_id": "<model_id>",
"embedding": "<vector_field>",
"field_map": {
"text": "<input_text_field>",
"image": "<input_image_field>"
},
"skip_existing": true
}
}
]
}
Sparse encoding processor
The sparse_encoding processor generates sparse vectors from text fields used in neural sparse retrieval.
- Optimization behavior: If the text fields in
field_mapare unchanged, the processor skips inference and reuses the existing sparse encoding.
Example pipeline:
PUT /_ingest/pipeline/optimized-ingest-pipeline
{
"description": "Optimized ingest pipeline",
"processors": [
{
"sparse_encoding": {
"model_id": "<model_id>",
"prune_type": "max_ratio",
"prune_ratio": "0.1",
"field_map": {
"text": "<vector_field>"
},
"skip_existing": true
}
}
]
}
Performance results
In addition to reducing compute costs, skipping redundant inference significantly lowers latency. The following benchmarks compare processor performance with and without the skip_existing optimization.
Test environment
We used the following cluster setup to run benchmarking tests.

Text embedding processor
- Model:
huggingface/sentence-transformers/msmarco-distilbert-base-tas-b - Dataset: Trec-Covid
Sample requests
Single document:
PUT /test_index/_doc/1
{
"text": "Hello World"
}
Bulk update:
POST _bulk
{ "index": { "_index": "test_index" } }
{ "text": "hello world" }
{ "index": { "_index": "test_index" } }
{ "text": "Hi World" }
The following table presents the benchmarking test results for the text_embedding processor.
| Operation type | Doc size | Batch size | Baseline (skip_existing=false) |
Updated (skip_existing=true) |
Δ vs. baseline | Unchanged (skip_existing=true) |
Δ vs. baseline |
|---|---|---|---|---|---|---|---|
| Single update | 3,000 | 1 | 1,400,710 ms | 1,401,216 ms | +0.04% | 292,020 ms | -79.15% |
| Batch update | 171,332 | 200 | 2,247,191 ms | 2,192,883 ms | -2.42% | 352,767 ms | -84.30% |
Text/image embedding processor
- Model:
amazon.titan-embed-image-v1 - Dataset: Flickr Image
Sample requests
Single document:
PUT /test_index/_doc/1
{
"text": "Orange table",
"image": "bGlkaHQtd29rfx43..."
}
Bulk update:
POST _bulk
{ "index": { "_index": "test_index" } }
{ "text": "Orange table", "image": "bGlkaHQtd29rfx43..." }
{ "index": { "_index": "test_index" } }
{ "text": "Red chair", "image": "aFlkaHQtd29rfx43..." }
The following table presents the benchmarking test results for the text_image_embedding processor.
| Operation type | Doc size | Batch size | Baseline | Updated | Δ vs. baseline | Unchanged | Δ vs. baseline |
|---|---|---|---|---|---|---|---|
| Single update | 3,000 | 1 | 1,060,339 ms | 1,060,785 ms | +0.04% | 465,771 ms | -56.07% |
| Batch update | 31,783 | 200 | 1,809,299 ms | 1,662,389 ms | -8.12% | 1,571,012 ms | -13.17% |
Sparse encoding processor
- Model:
huggingface/sentence-transformers/msmarco-distilbert-base-tas-b - Dataset: Trec-Covid
- Prune method:
max_ratio, ratio:0.1
Sample requests
Single document:
PUT /test_index/_doc/1
{
"text": "Hello World"
}
Bulk update:
POST _bulk
{ "index": { "_index": "test_index" } }
{ "text": "hello world" }
{ "index": { "_index": "test_index" } }
{ "text": "Hi World" }
The following table presents the benchmarking test results for the sparse_encoding processor.
| Operation type | Doc size | Batch size | Baseline | Updated | Δ vs. baseline | Unchanged | Δ vs. baseline |
|---|---|---|---|---|---|---|---|
| Single update | 3,000 | 1 | 1,942,907 ms | 1,965,918 ms | +1.18% | 306,766 ms | -84.21% |
| Batch update | 171,332 | 200 | 3,077,040 ms | 3,101,697 ms | +0.80% | 475,197 ms | -84.56% |
Conclusion
As demonstrated by the cost and performance results, the skip_existing optimization significantly reduces redundant inference operations, which translates to lower costs and improved system performance. By reusing existing embeddings when input fields remain unchanged, ingest pipelines can process updates faster and more efficiently. This strategy improves system performance, enhances scalability, and delivers more cost-effective embedding retrieval at scale.
What’s next
If you use the Bulk API with ingest pipelines, it’s important to understand how different operations behave.
The Bulk API supports two operations—index and update:
- The
indexoperation replaces the entire document and does trigger ingest pipelines. - The
updateoperation modifies only the specified fields but does not currently trigger ingest pipelines.
If you’d like to see ingest pipeline support added to the update operation in Bulk API requests, consider supporting this GitHub issue by adding a +1.


