You're viewing version 2.10 of the OpenSearch documentation. This version is no longer maintained. For the latest version, see the current documentation. For information about OpenSearch version maintenance, see Release Schedule and Maintenance Policy.
k-NN search with filters
To refine k-NN results, you can filter a k-NN search using one of the following methods:
- Efficient k-NN filtering: This approach applies filtering during the k-NN search, as opposed to before or after the k-NN search, which ensures that
kresults are returned (if there are at leastkresults in total). This approach is supported by the following engines:- Lucene engine with a Hierarchical Navigable Small World (HNSW) algorithm (k-NN plugin versions 2.4 and later)
- Faiss engine with an HNSW algorithm (k-NN plugin versions 2.9 and later) or IVF algorithm (k-NN plugin versions 2.10 and later)
- Post-filtering: Because it is performed after the k-NN search, this approach may return significantly fewer than
kresults for a restrictive filter. You can use the following two filtering strategies for this approach:- Boolean post-filter: This approach runs an approximate nearest neighbor (ANN) search and then applies a filter to the results. The two query parts are executed independently, and then the results are combined based on the query operator (
should,must, and so on) provided in the query. - The
post_filterparameter: This approach runs an ANN search on the full dataset and then applies the filter to the k-NN results.
- Boolean post-filter: This approach runs an approximate nearest neighbor (ANN) search and then applies a filter to the results. The two query parts are executed independently, and then the results are combined based on the query operator (
- Scoring script filter: This approach involves pre-filtering a document set and then running an exact k-NN search on the filtered subset. It may have high latency and does not scale when filtered subsets are large.
The following table summarizes the preceding filtering use cases.
| Filter | When the filter is applied | Type of search | Supported engines and methods | Where to place the filter clause |
|---|---|---|---|---|
| Efficient k-NN filtering | During search (a hybrid of pre- and post-filtering) | Approximate | - lucene (hnsw) - faiss (hnsw, ivf) | Inside the k-NN query clause. |
| Boolean filter | After search (post-filtering) | Approximate | - lucene- nmslib- faiss | Outside the k-NN query clause. Must be a leaf clause. |
The post_filter parameter | After search (post-filtering) | Approximate | - lucene- nmslib- faiss | Outside the k-NN query clause. |
| Scoring script filter | Before search (pre-filtering) | Exact | N/A | Inside the script score query clause. |
Filtered search optimization
Depending on your dataset and use case, you might be more interested in maximizing recall or minimizing latency. The following table provides guidance on various k-NN search configurations and the filtering methods used to optimize for higher recall or lower latency. The first three columns of the table provide several example k-NN search configurations. A search configuration consists of:
- The number of documents in an index, where one OpenSearch document corresponds to one k-NN vector.
- The percentage of documents left in the results after filtering. This value depends on the restrictiveness of the filter that you provide in the query. The most restrictive filter in the table returns 2.5% of documents in the index, while the least restrictive filter returns 80% of documents.
- The desired number of returned results (k).
Once you’ve estimated the number of documents in your index, the restrictiveness of your filter, and the desired number of nearest neighbors, use the following table to choose a filtering method that optimizes for recall or latency.
| Number of documents in an index | Percentage of documents the filter returns | k | Filtering method to use for higher recall | Filtering method to use for lower latency |
|---|---|---|---|---|
| 10M | 2.5 | 100 | Efficient k-NN filtering/Scoring script | Scoring script |
| 10M | 38 | 100 | Efficient k-NN filtering | Efficient k-NN filtering |
| 10M | 80 | 100 | Efficient k-NN filtering | Efficient k-NN filtering |
| 1M | 2.5 | 100 | Efficient k-NN filtering/Scoring script | Scoring script |
| 1M | 38 | 100 | Efficient k-NN filtering | Efficient k-NN filtering |
| 1M | 80 | 100 | Efficient k-NN filtering | Efficient k-NN filtering |
Efficient k-NN filtering
You can perform efficient k-NN filtering with the lucene or faiss engines.
Lucene k-NN filter implementation
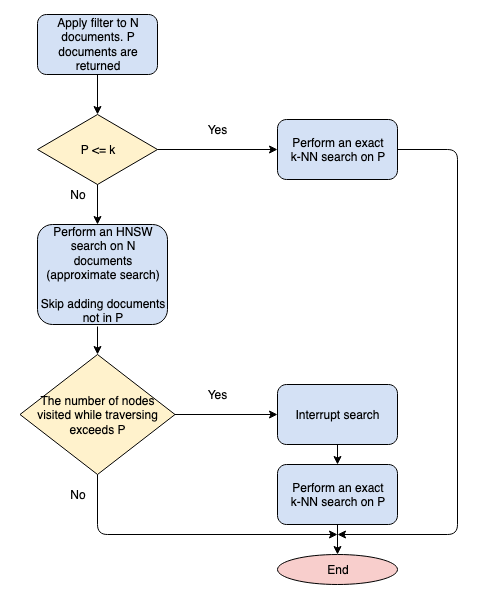
k-NN plugin version 2.2 introduced support for running k-NN searches with the Lucene engine using HNSW graphs. Starting with version 2.4, which is based on Lucene version 9.4, you can use Lucene filters for k-NN searches.
When you specify a Lucene filter for a k-NN search, the Lucene algorithm decides whether to perform an exact k-NN search with pre-filtering or an approximate search with modified post-filtering. The algorithm uses the following variables:
- N: The number of documents in the index.
- P: The number of documents in the document subset after the filter is applied (P <= N).
- k: The maximum number of vectors to return in the response.
The following flow chart outlines the Lucene algorithm.
For more information about the Lucene filtering implementation and the underlying KnnVectorQuery, see the Apache Lucene documentation.
Using a Lucene k-NN filter
Consider a dataset that includes 12 documents containing hotel information. The following image shows all hotels on an xy coordinate plane by location. Additionally, the points for hotels that have a rating between 8 and 10, inclusive, are depicted with orange dots, and hotels that provide parking are depicted with green circles. The search point is colored in red:
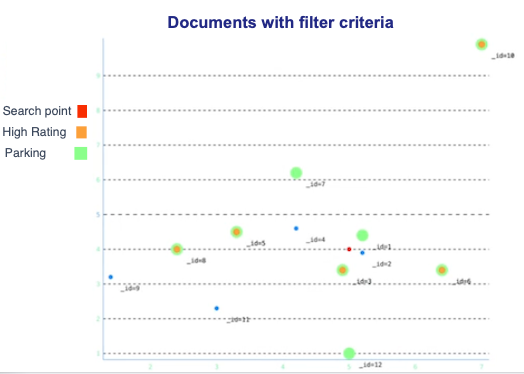
In this example, you will create an index and search for the three hotels with high ratings and parking that are the closest to the search location.
Step 1: Create a new index
Before you can run a k-NN search with a filter, you need to create an index with a knn_vector field. For this field, you need to specify lucene as the engine and hnsw as the method in the mapping.
The following request creates a new index called hotels-index with a knn-filter field called location:
PUT /hotels-index
{
"settings": {
"index": {
"knn": true,
"knn.algo_param.ef_search": 100,
"number_of_shards": 1,
"number_of_replicas": 0
}
},
"mappings": {
"properties": {
"location": {
"type": "knn_vector",
"dimension": 2,
"method": {
"name": "hnsw",
"space_type": "l2",
"engine": "lucene",
"parameters": {
"ef_construction": 100,
"m": 16
}
}
}
}
}
}
Step 2: Add data to your index
Next, add data to your index.
The following request adds 12 documents that contain hotel location, rating, and parking information:
POST /_bulk
{ "index": { "_index": "hotels-index", "_id": "1" } }
{ "location": [5.2, 4.4], "parking" : "true", "rating" : 5 }
{ "index": { "_index": "hotels-index", "_id": "2" } }
{ "location": [5.2, 3.9], "parking" : "false", "rating" : 4 }
{ "index": { "_index": "hotels-index", "_id": "3" } }
{ "location": [4.9, 3.4], "parking" : "true", "rating" : 9 }
{ "index": { "_index": "hotels-index", "_id": "4" } }
{ "location": [4.2, 4.6], "parking" : "false", "rating" : 6}
{ "index": { "_index": "hotels-index", "_id": "5" } }
{ "location": [3.3, 4.5], "parking" : "true", "rating" : 8 }
{ "index": { "_index": "hotels-index", "_id": "6" } }
{ "location": [6.4, 3.4], "parking" : "true", "rating" : 9 }
{ "index": { "_index": "hotels-index", "_id": "7" } }
{ "location": [4.2, 6.2], "parking" : "true", "rating" : 5 }
{ "index": { "_index": "hotels-index", "_id": "8" } }
{ "location": [2.4, 4.0], "parking" : "true", "rating" : 8 }
{ "index": { "_index": "hotels-index", "_id": "9" } }
{ "location": [1.4, 3.2], "parking" : "false", "rating" : 5 }
{ "index": { "_index": "hotels-index", "_id": "10" } }
{ "location": [7.0, 9.9], "parking" : "true", "rating" : 9 }
{ "index": { "_index": "hotels-index", "_id": "11" } }
{ "location": [3.0, 2.3], "parking" : "false", "rating" : 6 }
{ "index": { "_index": "hotels-index", "_id": "12" } }
{ "location": [5.0, 1.0], "parking" : "true", "rating" : 3 }
Step 3: Search your data with a filter
Now you can create a k-NN search with filters. In the k-NN query clause, include the point of interest that is used to search for nearest neighbors, the number of nearest neighbors to return (k), and a filter with the restriction criteria. Depending on how restrictive you want your filter to be, you can add multiple query clauses to a single request.
The following request creates a k-NN query that searches for the top three hotels near the location with the coordinates [5, 4] that are rated between 8 and 10, inclusive, and provide parking:
POST /hotels-index/_search
{
"size": 3,
"query": {
"knn": {
"location": {
"vector": [
5,
4
],
"k": 3,
"filter": {
"bool": {
"must": [
{
"range": {
"rating": {
"gte": 8,
"lte": 10
}
}
},
{
"term": {
"parking": "true"
}
}
]
}
}
}
}
}
}
The response returns the three hotels that are nearest to the search point and have met the filter criteria:
{
"took" : 47,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 0.72992706,
"hits" : [
{
"_index" : "hotels-index",
"_id" : "3",
"_score" : 0.72992706,
"_source" : {
"location" : [
4.9,
3.4
],
"parking" : "true",
"rating" : 9
}
},
{
"_index" : "hotels-index",
"_id" : "6",
"_score" : 0.3012048,
"_source" : {
"location" : [
6.4,
3.4
],
"parking" : "true",
"rating" : 9
}
},
{
"_index" : "hotels-index",
"_id" : "5",
"_score" : 0.24154587,
"_source" : {
"location" : [
3.3,
4.5
],
"parking" : "true",
"rating" : 8
}
}
]
}
}
For more ways to construct a filter, see Constructing a filter.
Faiss k-NN filter implementation
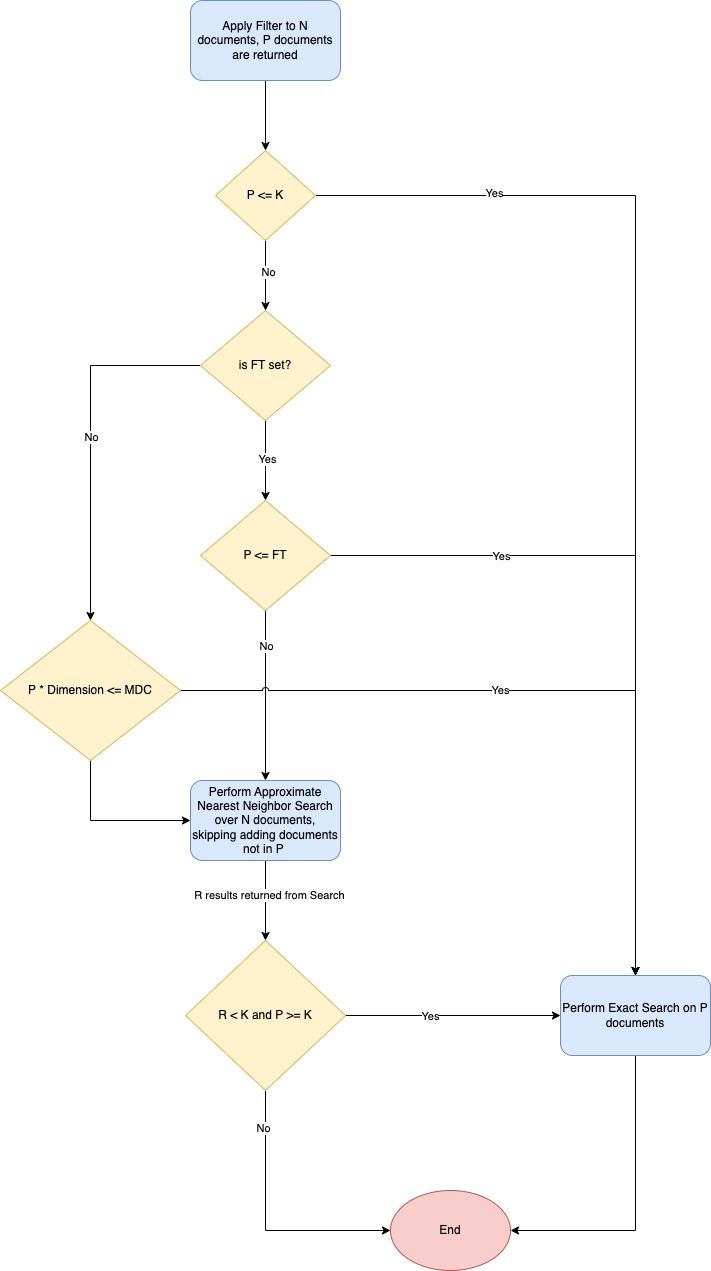
For k-NN searches, you can use faiss filters with an HNSW algorithm (k-NN plugin versions 2.9 and later) or IVF algorithm (k-NN plugin versions 2.10 and later).
When you specify a Faiss filter for a k-NN search, the Faiss algorithm decides whether to perform an exact k-NN search with pre-filtering or an approximate search with modified post-filtering. The algorithm uses the following variables:
- N: The number of documents in the index.
- P: The number of documents in the document subset after the filter is applied (P <= N).
- k: The maximum number of vectors to return in the response.
- R: The number of results returned after performing the filtered approximate nearest neighbor search.
- FT (filtered threshold): An index-level threshold defined in the
knn.advanced.filtered_exact_search_thresholdsetting that specifies to switch to exact search. - MDC (max distance computations): The maximum number of distance computations allowed in exact search if
FT(filtered threshold) is not set. This value cannot be changed.
The following flow chart outlines the Faiss algorithm.
Using a Faiss efficient filter
Consider an index that contains information about different shirts for an e-commerce application. You want to find the top-rated shirts that are similar to the one you already have but would like to restrict the results by shirt size.
In this example, you will create an index and search for shirts that are similar to the shirt you provide.
Step 1: Create a new index
Before you can run a k-NN search with a filter, you need to create an index with a knn_vector field. For this field, you need to specify faiss and hnsw as the method in the mapping.
The following request creates an index that contains vector representations of shirts:
PUT /products-shirts
{
"settings": {
"index": {
"knn": true
}
},
"mappings": {
"properties": {
"item_vector": {
"type": "knn_vector",
"dimension": 3,
"method": {
"name": "hnsw",
"space_type": "l2",
"engine": "faiss"
}
}
}
}
}
Step 2: Add data to your index
Next, add data to your index.
The following request adds 12 documents that contain information about shirts, including their vector representation, size, and rating:
POST /_bulk?refresh
{ "index": { "_index": "products-shirts", "_id": "1" } }
{ "item_vector": [5.2, 4.4, 8.4], "size" : "large", "rating" : 5 }
{ "index": { "_index": "products-shirts", "_id": "2" } }
{ "item_vector": [5.2, 3.9, 2.9], "size" : "small", "rating" : 4 }
{ "index": { "_index": "products-shirts", "_id": "3" } }
{ "item_vector": [4.9, 3.4, 2.2], "size" : "xlarge", "rating" : 9 }
{ "index": { "_index": "products-shirts", "_id": "4" } }
{ "item_vector": [4.2, 4.6, 5.5], "size" : "large", "rating" : 6}
{ "index": { "_index": "products-shirts", "_id": "5" } }
{ "item_vector": [3.3, 4.5, 8.8], "size" : "medium", "rating" : 8 }
{ "index": { "_index": "products-shirts", "_id": "6" } }
{ "item_vector": [6.4, 3.4, 6.6], "size" : "small", "rating" : 9 }
{ "index": { "_index": "products-shirts", "_id": "7" } }
{ "item_vector": [4.2, 6.2, 4.6], "size" : "small", "rating" : 5 }
{ "index": { "_index": "products-shirts", "_id": "8" } }
{ "item_vector": [2.4, 4.0, 3.0], "size" : "small", "rating" : 8 }
{ "index": { "_index": "products-shirts", "_id": "9" } }
{ "item_vector": [1.4, 3.2, 9.0], "size" : "small", "rating" : 5 }
{ "index": { "_index": "products-shirts", "_id": "10" } }
{ "item_vector": [7.0, 9.9, 9.0], "size" : "xlarge", "rating" : 9 }
{ "index": { "_index": "products-shirts", "_id": "11" } }
{ "item_vector": [3.0, 2.3, 2.0], "size" : "large", "rating" : 6 }
{ "index": { "_index": "products-shirts", "_id": "12" } }
{ "item_vector": [5.0, 1.0, 4.0], "size" : "large", "rating" : 3 }
Step 3: Search your data with a filter
Now you can create a k-NN search with filters. In the k-NN query clause, include the vector representation of the shirt that is used to search for similar ones, the number of nearest neighbors to return (k), and a filter by size and rating.
The following request searches for size small shirts rated between 7 and 10, inclusive:
POST /products-shirts/_search
{
"size": 2,
"query": {
"knn": {
"item_vector": {
"vector": [
2, 4, 3
],
"k": 10,
"filter": {
"bool": {
"must": [
{
"range": {
"rating": {
"gte": 7,
"lte": 10
}
}
},
{
"term": {
"size": "small"
}
}
]
}
}
}
}
}
}
The response returns the two matching documents:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.8620689,
"hits": [
{
"_index": "products-shirts",
"_id": "8",
"_score": 0.8620689,
"_source": {
"item_vector": [
2.4,
4,
3
],
"size": "small",
"rating": 8
}
},
{
"_index": "products-shirts",
"_id": "6",
"_score": 0.029691212,
"_source": {
"item_vector": [
6.4,
3.4,
6.6
],
"size": "small",
"rating": 9
}
}
]
}
}
For more ways to construct a filter, see Constructing a filter.
Constructing a filter
There are multiple ways to construct a filter for the same condition. For example, you can use the following constructs to create a filter that returns hotels that provide parking:
- A
termquery clause in theshouldclause - A
wildcardquery clause in theshouldclause - A
regexpquery clause in theshouldclause - A
must_notclause to eliminate hotels withparkingset tofalse.
The following request illustrates these four different ways of searching for hotels with parking:
POST /hotels-index/_search
{
"size": 3,
"query": {
"knn": {
"location": {
"vector": [ 5.0, 4.0 ],
"k": 3,
"filter": {
"bool": {
"must": {
"range": {
"rating": {
"gte": 1,
"lte": 6
}
}
},
"should": [
{
"term": {
"parking": "true"
}
},
{
"wildcard": {
"parking": {
"value": "t*e"
}
}
},
{
"regexp": {
"parking": "[a-zA-Z]rue"
}
}
],
"must_not": [
{
"term": {
"parking": "false"
}
}
],
"minimum_should_match": 1
}
}
}
}
}
}
Post-filtering
You can achieve post-filtering with a Boolean filter or by providing the post_filter parameter.
Boolean filter with ANN search
A Boolean filter consists of a Boolean query that contains a k-NN query and a filter. For example, the following query searches for hotels that are closest to the specified location and then filters the results to return hotels with a rating between 8 and 10, inclusive, that provide parking:
POST /hotels-index/_search
{
"size": 3,
"query": {
"bool": {
"filter": {
"bool": {
"must": [
{
"range": {
"rating": {
"gte": 8,
"lte": 10
}
}
},
{
"term": {
"parking": "true"
}
}
]
}
},
"must": [
{
"knn": {
"location": {
"vector": [
5,
4
],
"k": 20
}
}
}
]
}
}
}
The response includes documents containing the matching hotels:
{
"took" : 95,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : 0.72992706,
"hits" : [
{
"_index" : "hotels-index",
"_id" : "3",
"_score" : 0.72992706,
"_source" : {
"location" : [
4.9,
3.4
],
"parking" : "true",
"rating" : 9
}
},
{
"_index" : "hotels-index",
"_id" : "6",
"_score" : 0.3012048,
"_source" : {
"location" : [
6.4,
3.4
],
"parking" : "true",
"rating" : 9
}
},
{
"_index" : "hotels-index",
"_id" : "5",
"_score" : 0.24154587,
"_source" : {
"location" : [
3.3,
4.5
],
"parking" : "true",
"rating" : 8
}
}
]
}
}
post-filter parameter
If you use the knn query alongside filters or other clauses (for example, bool, must, match), you might receive fewer than k results. In this example, post_filter reduces the number of results from 2 to 1:
GET my-knn-index-1/_search
{
"size": 2,
"query": {
"knn": {
"my_vector2": {
"vector": [2, 3, 5, 6],
"k": 2
}
}
},
"post_filter": {
"range": {
"price": {
"gte": 5,
"lte": 10
}
}
}
}
Scoring script filter
A scoring script filter first filters the documents and then uses a brute-force exact k-NN search on the results. For example, the following query searches for hotels with a rating between 8 and 10, inclusive, that provide parking and then performs a k-NN search to return the 3 hotels that are closest to the specified location:
POST /hotels-index/_search
{
"size": 3,
"query": {
"script_score": {
"query": {
"bool": {
"filter": {
"bool": {
"must": [
{
"range": {
"rating": {
"gte": 8,
"lte": 10
}
}
},
{
"term": {
"parking": "true"
}
}
]
}
}
}
},
"script": {
"source": "knn_score",
"lang": "knn",
"params": {
"field": "location",
"query_value": [
5.0,
4.0
],
"space_type": "l2"
}
}
}
}
}