
Two years ago, I was an OpenSearch user at Cloudera, running queries, tuning configurations, and occasionally frustrated by search results that didn’t quite make sense. Today, I’m a maintainer of the search relevance plugin (dashboards-search-relevance and search-relevance) in Opensearch. This is the story of how that happened, and what I learned along the way.
It started with curiosity, not code
I want to be upfront about something. My path to becoming a maintainer didn’t begin with a pull request. It began with gratitude.
I’ve been using OpenSearch at Cloudera for over two years now, and I’m genuinely fond of the product. It made a huge difference for us, OpenSearch helped us replace a million-dollar subscription we were paying for another product.
 Seeing that kind of impact firsthand made me want to give back to the community that built it. I began exploring the codebase and connecting with the community. While searching for ways to get more involved, I found the OpenSearch Meetup page and discovered that there was a Search Triage call that happened every week. I joined, and looking back, I feel like that was where it all truly started.
Seeing that kind of impact firsthand made me want to give back to the community that built it. I began exploring the codebase and connecting with the community. While searching for ways to get more involved, I found the OpenSearch Meetup page and discovered that there was a Search Triage call that happened every week. I joined, and looking back, I feel like that was where it all truly started.
Listening to people in that call discuss search relevance, how users evaluate results, how tooling could make that process better, something clicked for me. Search relevance wasn’t just a feature area, it was a craft. And I found myself developing a real love for it after talking with people like Eric Pugh. But here’s the thing about the OpenSearch community: nobody made me feel like an outsider. People answered my questions. They pointed me to issues. They encouraged me to stay.
I kept showing up. Week after week. And slowly, I stopped being someone who just listened. I started having opinions. I started caring about what happened to this plugin.
The first pull request
I had spent enough time in triage calls and GitHub issues to know the codebase. I decided it was time to contribute code.
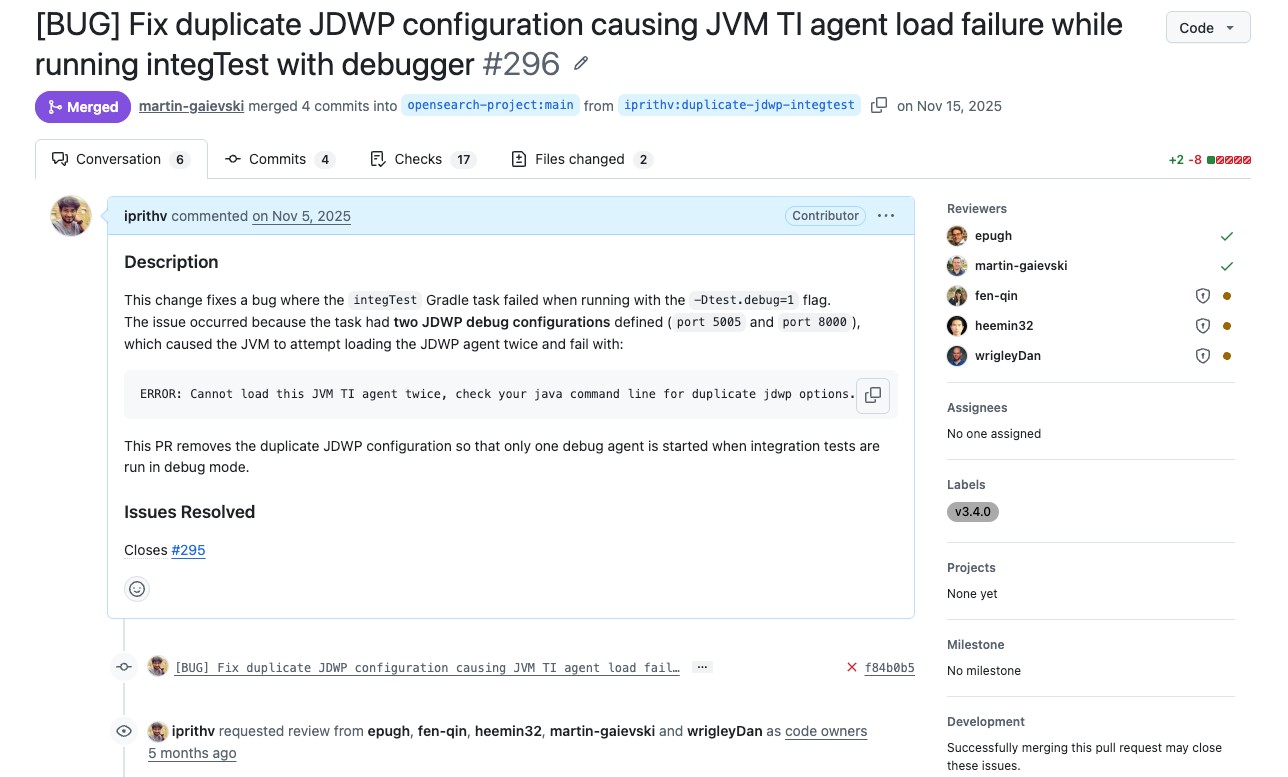 My first backend PR came from something very personal to how I work. I usually work with a debugger. It’s how I understand code best. When I was setting up the search-relevance project locally, I hit an issue: a duplicate Java Debug Wire Protocol (JDWP) configuration was causing a JVM Tool Interface (JVM TI) agent load failure when running integration tests with the debugger attached. A two line fix in two files got it working for me. I could have just kept it as a local change and moved on with my debugging. But I thought maybe this could be a contribution. Maybe someone else has hit this too. I honestly didn’t think such a small change would get merged, but it did.
My first backend PR came from something very personal to how I work. I usually work with a debugger. It’s how I understand code best. When I was setting up the search-relevance project locally, I hit an issue: a duplicate Java Debug Wire Protocol (JDWP) configuration was causing a JVM Tool Interface (JVM TI) agent load failure when running integration tests with the debugger attached. A two line fix in two files got it working for me. I could have just kept it as a local change and moved on with my debugging. But I thought maybe this could be a contribution. Maybe someone else has hit this too. I honestly didn’t think such a small change would get merged, but it did.
That moment taught me something: everything that is useful to the community is important. There’s no contribution too small if it saves someone else from the same frustration.
On the frontend side, my first contribution was supporting GUID filtering in Query Sets, a small feature that lets users filter by unique identifiers. Again, not a massive change, but it taught me the patterns of the Dashboards plugin, the review process, and the rhythm of contributing.
Those early PRs taught me something important: the size of your contribution doesn’t matter nearly as much as the act of contributing. Every PR, no matter how small, is a signal that you care about the project.
Building momentum: From bug fixes to features
After those first contributions, I understood the codebase. I knew the people. I had context from triage calls. So I started picking up bigger work.
Over the period, I contributed across both the frontend and backend repositories. Here are some of the highlights that I’m particularly proud of:
On the backend (search-relevance):
- Fixed a floating-point precision bug in the weight generation logic used by hybrid search (combining lexical and vector search results), which was producing incorrect search quality metrics.
- Added status filtering to the List Judgments API to address incomplete judgment ratings groups being shown during selection. This one required understanding the full lifecycle of judgment objects.
- Introduced judgment thresholds for metrics calculation, giving users more control over how search quality is measured.
- Extended the set of search quality metrics available for evaluation.
- Built the feature to provide a name and description for experiments, a change that touched the core experiment workflow.
On the frontend (dashboards-search-relevance):
- Implemented the resizable query section, a significant UX overhaul, making the comparison interface much more usable.
- Built support for manually creating a Query Set from the UI, something users had been asking for.
- Created the feature to reuse Search Configurations with the Single Query Comparison UI, connecting previously siloed parts of the workflow.
- Improved the Judgment Detail page UX, making it easier for users to work with judgment data.
- Fixed a persistent bug with deleting judgment ratings that had been affecting users, rethinking parts of the state management.
The list of works tells one story. But the real story is about what happened between the pull requests.
Beyond code: The work that doesn’t show up in git log
In open source, there’s a principle that resonates deeply with me. In the OpenSearch world, I understood that the health of the community matters as much as the quality of the code. The OpenSearch founding principle says clearly this project is for the community and by the community.
I took that to heart. Here’s what my contribution looked like beyond writing code:
Filing issues and shaping the roadmap. I opened several issues across the dashboards-search-relevance and search-relevance repositories bug reports, feature requests, and improvements that I identified from using the product and from triage discussions. Some of these, like #766, #747, and #753, became PRs that I or others worked on. Filing a clear, well-scoped issue is a contribution in itself, it helps maintainers prioritize and gives other contributors something to pick up.
Closing stale issues. I helped triage and close older issues like #58, #103, #494, #528, #608, and #706 verifying whether they were still relevant, providing context, or confirming they had been resolved. This kind of housekeeping is unglamorous but essential. A clean issue tracker is a sign of a healthy project.
Reviewing others’ code. I reviewed PRs like #723, #672, #400, and #360. Code review is where you learn the most, you see how others solve problems, catch edge cases, and build trust with fellow contributors
Writing RFCs. I authored an RFC for the search-relevance project, proposing design changes and inviting community feedback before writing a single line of implementation code.
What I learned about becoming a maintainer
Becoming a maintainer isn’t a promotion you apply for. It’s a recognition that you’ve already been doing the work. By the time the conversation happened, I had been reviewing code, filing issues, triaging bugs, contributing features, and attending every triage call for a long time. The title just made official what was already true.
If you’re working toward maintainership in an OpenSearch plugin or any open-source project, here’s what I’d tell you:
Use the product first. I had two years of hands-on experience with OpenSearch at Cloudera before I wrote a single line of open-source code. That real world usage gave me the instinct to know what mattered to users, which bugs were painful, and which features would make a difference. Don’t rush to contribute code before you understand the product.
Start with the community, not the codebase. Join the triage calls. Listen. Ask questions. Understand the priorities. When you eventually open a PR, it won’t be guesswork, it’ll be aligned.
Pick issues that match your context. My first backend PR was about a JVM debugging configuration, something I ran into because I like to work with a debugger to understand code deeply. My early frontend PRs were small filtering features. Start where your natural habits lead you, and expand from there.
Do the work nobody celebrates. File issues. Close stale ones. Review PRs. Write RFCs. Update documentation. These contributions don’t generate GitHub activity graphs, but they build trust with maintainers faster than any feature PR.
Be patient and persistent. I went from attending my first triage call to becoming a maintainer over the course of roughly a year. There’s no shortcut. Show up, contribute consistently, and the rest follows.
What’s next
I recently became a maintainer of the search relevance plugin (dashboards-search-relevance and search-relevance) in Opensearch. But the title changes less than you’d think. I’m still doing the same work: reviewing PRs, filing issues, joining triage calls, and writing code to make search relevance tooling better for everyone who uses OpenSearch.
Beyond that, I’m looking to expand my contributions into OpenSearch core search. There’s so much depth to explore there, and I want to understand the engine at an even deeper level. And honestly, if another plugin excites me along the way, I’ll follow that curiosity too. That’s the beauty of a project this large. There’s always something new to learn, always another corner of the codebase that could use a pair of hands.
What excites me most is helping others take the same path. If you’re reading this and wondering whether you can contribute to OpenSearch you can. The community is welcoming, the maintainers are supportive, and the project is genuinely open. You don’t need permission. You just need to start.
Come say hi on the OpenSearch Slack, join a triage meeting, or pick up a good first issue. I’ll see you there.
Prithvi S is a Staff Software Engineer at Cloudera and a maintainer of the OpenSearch dashboards-search-relevance and search-relevance plugin. You can find him on GitHub.
