
Vector search has become the foundation of modern semantic search systems. Today’s most common approach uses single vector embeddings, but recent state-of-the-art research shows that multi-vector representations created by late interaction models can significantly improve search relevance by preserving fine-grained, token-level information.
Unlike traditional approaches that compress entire documents into single vectors, late interaction models preserve token-level information until the final matching stage, enabling more precise and nuanced search results.
In this blog post, we’ll explore what late interaction models are, why they’re becoming increasingly important in search applications, and how you can use them in OpenSearch to deliver better search experiences for your users.
What is a late interaction model?
To understand late interaction models, let’s first examine the three main approaches for neural search, each offering different trade-offs between efficiency and accuracy.
Interaction is the process of evaluating the relevance between a query and a document by comparing their representations at a fine-grained level. The key difference lies in when and how the system compares queries with documents.
Bi-encoder models (no interaction)
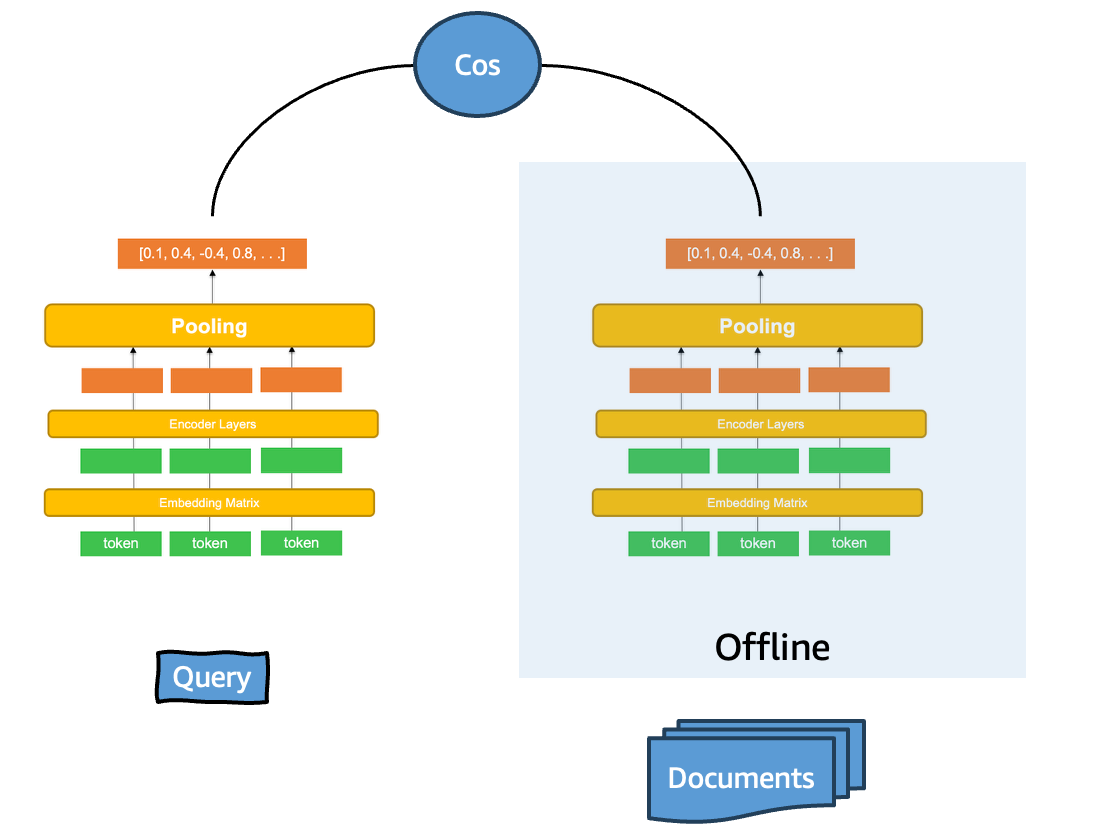
Bi-encoder models represent today’s most common approach, processing queries and documents completely independently.
In this architecture, a query such as “best hiking trails near Seattle” is transformed into a single vector representation through one encoder, while each document is processed separately through another encoder to produce its own single vector representation. These encoding processes occur in isolation—the query encoder has no access to document content, and vice versa. Relevance is subsequently determined by comparing these precomputed single vectors using similarity metrics such as cosine similarity or dot product.
Advantages:
- High efficiency: Document vectors can be computed offline and stored in advance.
- Excellent scalability: Performs well with large datasets.
- Fast retrieval: Enables rapid first-stage filtering of candidates.
Limitations:
- Reduced accuracy: A lack of interaction between the query and document during encoding limits semantic understanding.
This approach works particularly well for fast first-stage retrieval in vector search systems. Models like amazon.titan-embed-text-v2:0 exemplify this methodology. The following diagram illustrates the bi-encoder architecture and its independent processing approach.
Cross-encoder models (early/full interaction)
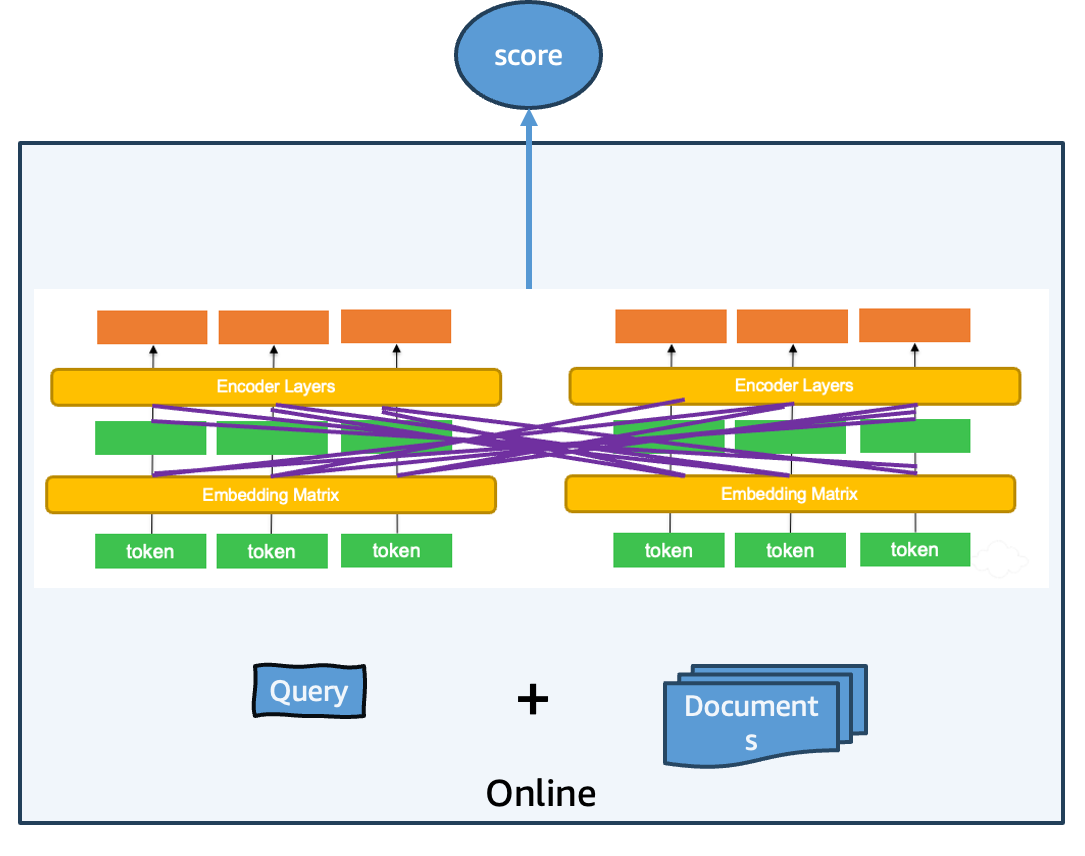
Cross-encoder models occupy the opposite end of the spectrum, achieving the highest accuracy through comprehensive query-document interaction.
In this architecture, the system concatenates the query with each candidate document (for example, “best hiking trails near Seattle” combined with document content) and processes this combined text through a transformer model. The model’s attention mechanism enables every query token to attend to every document token during encoding, capturing nuanced relationships between query and document elements. The model then directly outputs a single relevance score for the query-document pair.
Advantages:
- Highest accuracy: Deep interaction captures sophisticated semantic relationships.
- Superior understanding: A full attention mechanism provides comprehensive query-document analysis.
Limitations:
- Computational intensity: Each query-document pair requires a complete forward pass through the model.
- No precomputation: You cannot leverage cached embeddings, limiting scalability.
- Latency concerns: Processing overhead restricts real-time applications.
Cross-encoder models excel in second-phase reranking scenarios, where they reorder a small, preselected subset of results to optimize the most relevant matches. The size of the result set processed by cross-encoders typically depends on system requirements for cost, latency, and accuracy, but these models are commonly applied to first-page results only. OpenSearch provides native support for cross-encoder reranking through search pipelines. The following diagram demonstrates the cross-encoder architecture with its comprehensive query-document interaction mechanism.
Late interaction models (balanced approach)
Late interaction models, exemplified by ColBERT (Contextualized Late Interaction over BERT), achieve an optimal balance between the previous two approaches. These models process queries and documents independently, similar to bi-encoders, but generate multiple contextualized embeddings rather than single vectors.
In this architecture, a query such as “best hiking trails near Seattle” produces individual embeddings for each token: “best,” “hiking,” “trails,” “near,” and “Seattle”. Crucially, each embedding is contextualized by the surrounding words through the transformer’s attention mechanism. Documents undergo similar processing, resulting in multi-vector representations at the token level.
The fundamental innovation of late interaction models lies in their timing: query-document interaction occurs after independent encoding, through detailed token-level similarity computations. This approach preserves the efficiency benefits of independent encoding while enabling more sophisticated matching than single-vector comparison. The following diagram illustrates how late interaction models balance efficiency and accuracy through their unique architecture.
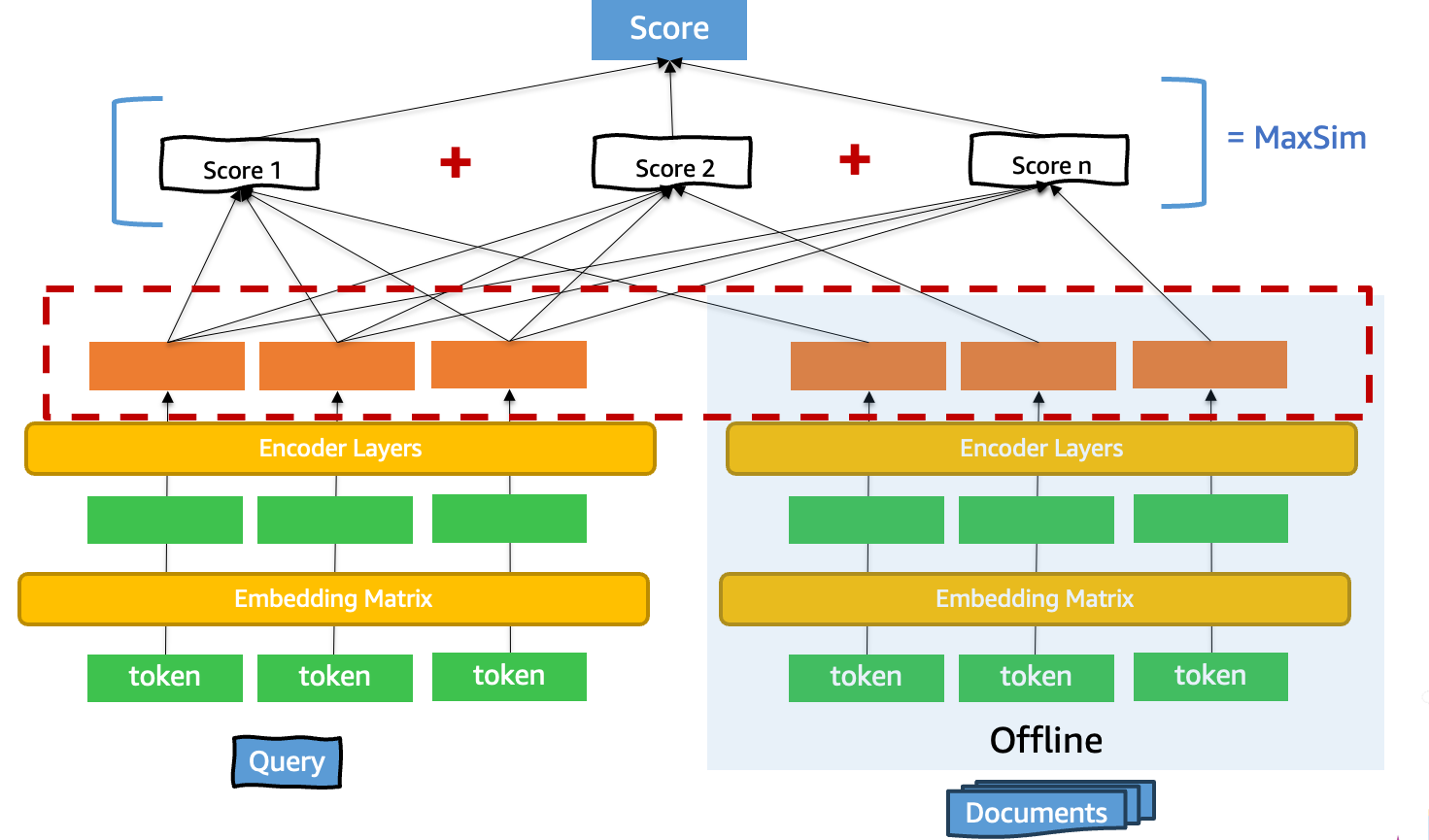
ColBERT exemplifies this approach through its scoring mechanism. After generating contextualized token embeddings for both the query and document, the model calculates the maximum similarity between each query token embedding and all document token embeddings. These maximum similarities are then aggregated to produce a final relevance score.
Advantages:
- Efficient precomputation: Document embeddings can be computed and stored offline.
- Token-level precision: Maintains fine-grained semantic information throughout the process.
- Balanced performance: Combines the speed benefits of bi-encoders with improved accuracy.
Scoring mechanism: This “late interaction” methodology enables more sophisticated matching than single-vector comparison while retaining computational efficiency.
The architectural spectrum
The three approaches form a spectrum of trade-offs between computational efficiency and search accuracy:
- Bi-encoders: Maximum efficiency, moderate accuracy, no query-document interaction
- Late interaction models: Balanced efficiency and accuracy, token-level interaction after encoding
- Cross-encoders: Maximum accuracy, higher computational cost, full interaction during encoding
Understanding this spectrum helps system architects choose the appropriate approach based on their specific requirements for latency, accuracy, and computational resources.
Why use late interaction models in search?
Using late interaction models in search offers several compelling advantages:
- Enhanced semantic understanding: Unlike traditional approaches that compress documents into single vectors, late interaction models preserve token-level information until the final matching stage. This enables precise token-level matching that single-vector models cannot achieve. For example, when searching “How can the orientation of texture be characterized?” within a multimodal document collection, a late interaction model like ColPali can identify specific sections within PDF pages discussing texture orientation analysis, even when the exact phrase does not appear in the text. The model’s token-level embeddings can match “orientation” with related concepts such as “directional analysis” and connect “texture” with “surface patterns” at a granular level, then aggregate these matches for accurate document ranking. This granular approach proves particularly valuable in specialized domains requiring high precision, such as scientific literature, technical documentation, and legal content.
- Optimal efficiency-accuracy balance: Late interaction models achieve an optimal balance between computational efficiency and search accuracy. They combine the efficiency of bi-encoders (through precomputed document embeddings) with accuracy levels approaching those of cross-encoders.
- Multimodal capabilities: Recent developments such as ColPali and ColQwen extend late interaction principles to images and other media types through patch-level embeddings. This advancement enables sophisticated searches such as “charts illustrating quarterly revenue” to pinpoint specific sections within PDFs—a capability that presents significant challenges for traditional single-vector models.
How to use late interaction models in OpenSearch
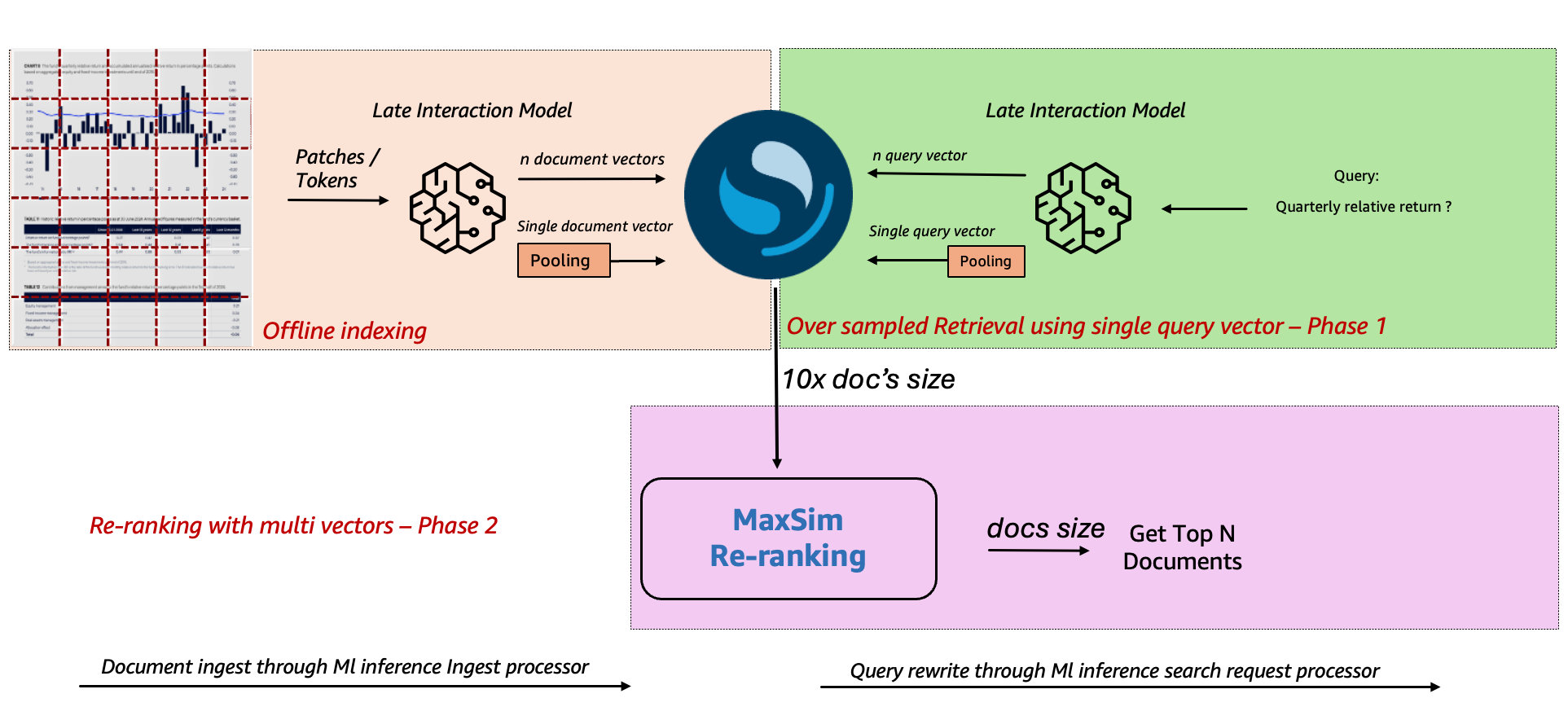
The search industry commonly adopts a two-phase strategy to integrate late interaction models in a way that balances performance and accuracy.
In the first phase, the system runs a fast approximate k-NN retrieval using single-vector embeddings from a bi-encoder model to select a small set of candidate documents from the full index. This step reduces the search space without the cost of processing multi-vector representations.
In the second phase, a reranker applies late interaction scoring to those candidates, using token-level multi-vectors to compute more precise relevance scores. The final ranked results reflect these fine-grained similarity calculations, enabling nuanced semantic matching while preserving scalability.
OpenSearch 3.3 introduced native support for late interaction reranking using the lateInteractionScore function. This function calculates document relevance using token-level vector matching by comparing each query vector against all document vectors, finding the maximum similarity for each query vector, and summing these maximum scores to produce the final document score.
The following example demonstrates using the lateInteractionScore function with cosine similarity to measure vector similarity based on direction rather than distance. In this example, the function compares document vectors named my_vector with the query vectors specified in the query_vectors parameter. To use this function, you need multi-vectors generated offline during document ingestion and multi-vectors computed online during query processing:
GET my_index/_search
{
"query": {
"script_score": {
"query": { "match_all": {} },
"script": {
"source": "lateInteractionScore(params.query_vectors, 'my_vector', params._source, params.space_type)",
"params": {
"query_vectors": [[1.0, 0.0]], [[0.0, 1.0]],
"space_type": "cosinesimil"
}
}
}
}
}
OpenSearch supports the full workflow for using late interaction models—from model connection to ingestion and search. To enable this functionality, you configure two main components. The ml-inference ingest processor generates both single-vector and multi-vector embeddings from text, PDFs, or images during document ingestion. The ml-inference search request processor rewrites incoming queries into k-NN queries that use the lateInteractionScore function at search time. Together, these components enable multimodal search with improved relevance across diverse content types. For detailed configuration steps, see the tutorial on reranking with externally hosted late interaction models.
To showcase the search performance of late interaction models, the ML playground includes a side-by-side comparison using the Vidore dataset. The dataset contains internet-sourced text about artificial intelligence, and 20 representative pages are indexed in the multimodal_docs index in the ML playground environment.
The interface allows you to compare a two-phase pipeline—which uses the ColPali model for late interaction reranking—against a single-phase baseline that uses amazon.titan-embed-image-v1 without late interaction. You can experiment with different queries to see how late interaction models improve relevance ranking for multimodal content.
Comparative results analysis
The following test demonstrates performance differences using the query “How can the orientation of texture be characterized?” against the multimodal_docs index. The comparison evaluates two approaches:
- Left panel:
colpali_searchsearch pipeline using ColPali model - Right panel:
titan_embedding_searchsearch pipeline using Titan embedding model
The target result appears on page 7, which contains the relevant answer explaining that texture orientation is characterized by a histogram of orientations. The ColPali model ranks this page as the top result (left panel), while the Titan embedding model fails to include it in the search results entirely (right panel). The following screenshot demonstrates this significant difference in search performance between the two approaches.
 For RAG applications using ColPali, explore the OpenSearch AI demo app available through Hugging Face.
For RAG applications using ColPali, explore the OpenSearch AI demo app available through Hugging Face.
Challenges and optimization techniques
While late interaction models offer strong retrieval accuracy, they also introduce significant computational and storage considerations. Because these models generate vectors for every token rather than a single embedding per document, they can produce hundreds or thousands of vectors per document—often increasing storage requirements by 10–100x compared to traditional approaches.
Recent research provides several strategies for addressing these challenges. PLAID (Performance-optimized Late Interaction Driver) uses centroids and clustering to shrink the number of vectors while preserving accuracy. Quantization techniques compress multi-vectors using binary or product quantization to reduce memory use. Smart chunking applies strategic document segmentation before embedding generation, and selective token embedding removes common stop words or uses attention mechanisms to keep only the most important tokens. Together, these optimizations make late interaction models more practical for production environments while maintaining their core advantage: fine-grained, token-level semantic matching.
Future developments in Lucene and OpenSearch
The OpenSearch vector engine (k-NN plugin) currently supports late interaction multi-vector rescoring using Painless scripting. Rescoring implementation is optimized for SIMD instructions. Multi-vectors are represented using a combination of OpenSearch’s object field type and float field type, which together enable storage and retrieval of token-level vector embeddings used in late interaction models.
Since the 10.3 release, Lucene also provides native support for rescoring search results using late interaction model multi-vectors. This capability is implemented through the LateInteractionField, which accepts float[][] multi-vector embeddings, encodes them into a binary representation, and indexes them as a BinaryDocValues field. The field supports multi-vectors with varying numbers of vectors per document; however, each token vector must have the same dimensionality. This requirement is common across late interaction models because it enables consistent similarity comparisons between query and document vectors.
Lucene also includes a LateInteractionRescorer class for rescoring results based on multi-vector similarity. The default scoring method is sum(max(vectorSimilarity)), which sums the maximum similarity between each query token vector and all document token vectors. In effect, each query token vector is compared against every document token vector, and their strongest interactions are aggregated into a final relevance score.
Planned enhancements
Development is underway to integrate Lucene’s LateInteractionField directly into the OpenSearch vector engine. This work (tracked in the related GitHub issues and PRs) will use Lucene’s built-in vectorization providers, which automatically vectorize operations and apply SIMD intrinsics when supported by the underlying hardware. With this integration, OpenSearch will inherit performance optimizations from upstream Lucene and benefit from ongoing improvements in this rapidly evolving area. Additionally, this integration enables late interaction model reranking in environments where Painless scripts are not supported.
To support this effort, we welcome your contributions in the form of patches and pull requests.
Get started with late interaction models
Ready to enhance your search relevance? Start experimenting with late interaction models in your OpenSearch deployment by following the reranking tutorial. Share your results, ask questions, and provide feedback on the OpenSearch forum. Your input helps shape the future development of these capabilities.



