OpenSearch’s adoption as a vector database has grown significantly with the rise of generative AI applications. Vector search workloads are scaling from millions to billions of vectors, making traditional CPU-based indexing both time consuming and cost intensive. To address this challenge, OpenSearch is introducing GPU acceleration as a preview feature for the OpenSearch Vector Engine in the upcoming 3.0 release by using NVIDIA cuVS. By leveraging the massive parallel processing capabilities of GPUs, this new feature dramatically reduces index building time, significantly lowering operational costs while delivering superior performance for large-scale vector workloads.
Why use GPU acceleration?
The OpenSearch Vector Engine has made significant strides in 2024, implementing various optimizations including AVX512 SIMD support, segment replication, efficient vector formats for reading and writing vectors, iterative index builds, intelligent graph builds, and a derived source for vectors. While these features and optimizations delivered incremental improvements in indexing times, they primarily enhanced the peripheral components of vector search rather than addressing the fundamental performance bottleneck in core vector operations.
Vector operations, particularly distance calculations, are computationally intensive tasks that are ideally suited for parallel processing. GPUs excel in this domain due to their massively parallel architecture, capable of performing thousands of calculations simultaneously. By leveraging GPU acceleration for these compute-heavy vector operations, OpenSearch can dramatically reduce index build times. This not only improves performance but also translates to significant cost savings, as shorter processing times mean reduced resource utilization and lower operational expenses. The GPU’s ability to efficiently handle these parallel computations makes it a natural fit for accelerating vector search operations, offering a compelling solution for organizations dealing with large-scale vector datasets.
The new architecture
The streamlined, decoupled GPU-accelerated indexing system comprises three core components:
- Vector Index Build Service – A dedicated GPU-powered fleet that specializes in high-performance vector index construction. This service operates independently to ensure optimal GPU resource utilization.
- OpenSearch Vector Engine – The k-NN plugin that manages vector-related operations, from ingestion to search, seamlessly integrating CPU- and GPU-accelerated workflows.
- Object store – A fault-tolerant intermediate storage layer that uses OpenSearch’s repository abstractions to securely store and handle vector data.
The following image illustrates the new architecture.
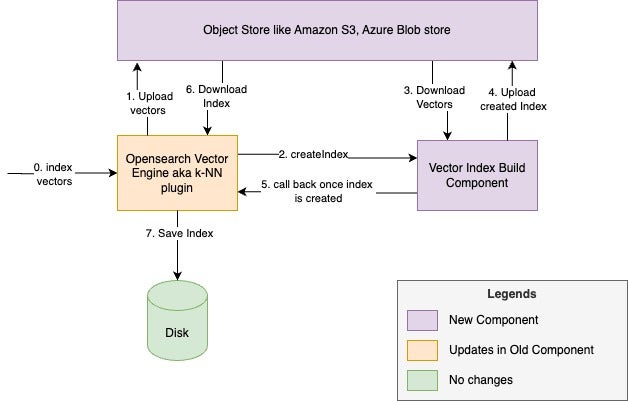
The new system uses the following workflow:
- Documents containing vectors are ingested into OpenSearch using the Bulk API.
- During flush/merge operations, the OpenSearch Vector Engine:
- Uploads vectors to the object store.
- Initiates a GPU-accelerated index build request to the GPU fleet.
- Monitors the progress of the build.
- The Vector Index Build Service:
- Constructs the index using GPU acceleration.
- Converts the index to a CPU-compatible format.
- Uploads the completed index to the object store.
- Finally, the OpenSearch Vector Engine:
- Downloads the optimized index.
- Integrates it with existing segment files.
- Completes the segment creation process.
If an error is encountered during any step, the system automatically falls back to CPU-based index building to ensure continuous operation. For more information, see the technical design documents and architecture diagrams.
Vector index builds using the CAGRA algorithm
The GPU workers leverage the NVIDIA cuVS CAGRA algorithm integrated through the Faiss library. CAGRA, or (C)UDA (A)NNS (GRA)ph-based, is a novel approach to graph-based indexing that was built from the ground up for GPU acceleration. CAGRA constructs a graph representation by first building a k-NN graph using either IVF-PQ or NN-DESCENT and then removing redundant paths between neighbors.
The following image illustrates the CAGRA algorithm. When a Vector Index Build request is received by the GPU workers, it carries all necessary parameters for constructing the segment-specific vector index. The Vector Index Build component initiates the process by retrieving the vector file from the object store and loading it into CPU memory. These vectors are then inserted into the CAGRA index through Faiss. Upon completion of the index construction, the system automatically converts the CAGRA index into an HNSW-based format, ensuring compatibility with CPU-based search operations. The converted index is then uploaded to the object store, marking the successful completion of the build request. This ensures that indexes built on GPUs can be efficiently searched on CPU machines while maintaining index building performance benefits.

Source: CAGRA: Highly Parallel Graph Construction and Approximate Nearest Neighbor Search for GPUs
Benchmark results
Initial benchmarking showed significant improvements in indexing performance and cost efficiency. The experiments used a 10M 768D dataset and OpenSearch Benchmark. The OpenSearch distribution is available here.
Test setup
| Key | Value |
|---|---|
| Number of data nodes | 3 |
| Data node type | r6g.4xlarge |
| Number of GPU workers | 3 |
| GPU worker type | g5.2xlarge |
| OpenSearch version | 2.19.0 |
Index configuration
| Key | Value |
|---|---|
| Number of primary shards | 6 |
| Number of replicas | 1 |
Performance comparison
The following table provides our experiment results.
| Metric | Baseline | GPU accelerated | Improvement |
|---|---|---|---|
| Optimized index build time (min) | 273.78333 | 29.13 | 9.3976 |
| Max CPU utilization (%) | 100 | 40 | 2.5 |
| Cluster cost (3 x r6g.4xlarge) | 11.03894 | 1.17 | |
| GPU cost (3 x g5.2xlarge) | 0 | 1.77 | |
| Total cost | 11.03894 | 2.94 | 3.75457 |
| Mean indexing throughput | 8202.98 | 16796.2 | 2.04757 |
| Index size (GB, without replicas) | 58.7 | 58.7 |
These results show that GPU acceleration improved indexing speed by 9.3x while reducing costs by 3.75x. Additionally, CPU utilization was 2.5x lower compared to the baseline, while indexing throughput improved by 2x. Because vector index builds no longer occur on CPUs, the OpenSearch cluster can handle higher indexing traffic without additional scaling, making it more efficient for heavy workloads.
Key benefits
GPU acceleration offers several advantages for vector search in OpenSearch:
- Decoupled architecture: OpenSearch and GPU workers operate independently, allowing each to evolve separately. This flexibility enables continuous optimization of price-performance ratios without interdependencies. Additionally, multiple OpenSearch clusters can share the same GPU resources on a time-shared basis.
- Efficient resource usage: GPU nodes focus solely on vector index building at the segment level, avoiding text index construction. This targeted use minimizes GPU utilization time, maximizing resource efficiency and cost effectiveness.
- Enhanced fault tolerance: An intermediate storage layer acts as a buffer, providing robust error handling. If a GPU worker fails mid-process, index build jobs can be restarted seamlessly without requiring vector re-uploads, significantly reducing downtime and data transfer overhead.
Conclusion
GPU-accelerated vector indexing marks a major milestone in OpenSearch’s evolution toward supporting large-scale AI workloads. Our benchmarks showed that GPU acceleration improved indexing speed by 9.3x while reducing costs by 3.75x compared to CPU-based solutions, reducing the time required for billion-scale index builds from days to hours. While GPU instances cost 1.5x more than their CPU counterparts, the substantial speed increase delivers a strong price-performance advantage—further amplified by the shared GPU fleet model for multi-tenant use.
The decoupled design ensures flexibility, allowing OpenSearch to adopt future hardware accelerators and algorithmic improvements. The deployment model enables seamless adoption across cloud and on-premises environments. By leveraging the CAGRA algorithm from NVIDIA’s cuVS library and supporting GPU-CPU index interoperability, OpenSearch delivers a robust, scalable solution with built-in error handling and fallback mechanisms for production reliability.
What’s next?
The initial GPU-based index build algorithm release will support FP32 for GPU-based index acceleration. Upcoming releases will introduce FP16 and byte support to further improve price-performance. Additionally, the OpenSearch community continues to enhance vector engine capabilities in order to enable low-latency, high-throughput retrieval, unlocking new possibilities for vector search at scale.
References
- CAGRA: Highly Parallel Graph Construction and Approximate Nearest Neighbor Search for GPUs
- Meta issue for improving the indexing performance of OpenSearch Vector Engine.
- Boosting OpenSearch Vector Engine Performance using GPUs RFC.
- Faiss library used for integrating with the CAGRA index.
- Worker images for setting up the OpenSearch cluster can be found here.
- OpenSearch Vector Engine code for integrating the index builds with remote index build workers.
- OpenSearch cluster CDK for setting up the OpenSearch cluster.




