
Development teams are using Data Prepper and OpenSearch to better understand their applications through Trace Analytics. Now teams can use Data Prepper and OpenSearch for log analysis as well. You can start using Data Prepper 1.2.0 for log ingestion today. This release enables log collection into OpenSearch from Fluent Bit, supports Logstash configuration files, and provides other improvements.
Log Ingestion
The Problem with Logs
OpenSearch is a great tool for searching log data and developers are already using it for log analysis. Modern applications are distributed, often containing multiple services running across different servers. Developers want to analyze their log data centrally to more quickly address customer issues and improve application performance, availability, and security.
Getting log data into OpenSearch isn’t easy though. Application logs are generally unstructured data. They are lines of text which humans can read, but are not great for searching and analysis at large scale. Developers need to structure their log data in OpenSearch, enabling then to search for key events. Say, for example, finding slow HTTP requests during a certain time window.
The Solution
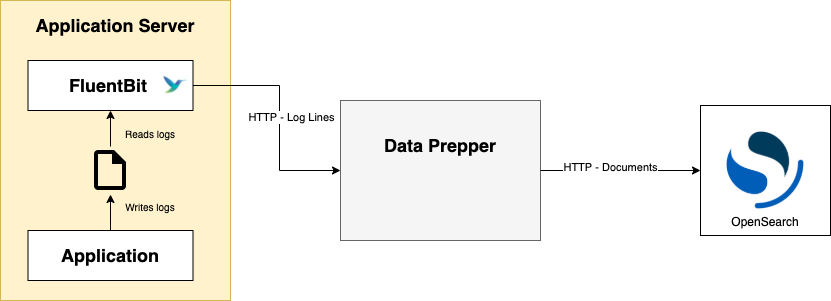
Data Prepper now supports log ingestion into OpenSearch using FluentBit. FluentBit is a popular Apache-licensed log forwarder. It runs alongside an application, reads log files, and forwards them to a destination over HTTP. Data Prepper receives these log lines using the new http source plugin. Data Prepper saves each log line as an individual OpenSearch document.
This diagram outlines the basic architecture for log ingestion using FluentBit, Data Prepper, and OpenSearch.
In this release, Data Prepper also provides a method to structure log data using the grok prepper. Pipeline authors can configure a grok prepper based on the known log format. Data Prepper will extract the specified parts of the log lines into specific fields in the destination OpenSearch document. The grok prepper uses patterns to extract parts of incoming log data. It has a number of predefined patterns and allows authors to create custom patterns using regular expressions. Here are just a few common predefined patterns Data Prepper supports.
INT– an integer valueUUID– A UUIDIP– an IP address in IPv4 or IPv6IPORHOST– either an IP address or a hostnameMONTH– the name of a Gregorian calendar month in the full name (January) or abbreviated form (Jan)LOGLEVEL– common log levels such as ERROR, WARN, DEBUG
To configure Data Prepper for log ingestion, you will create a pipeline with an http source, grok prepper, and opensearch sink. The following diagram shows the flow of data through this type of pipeline.

An Example
I’m going to illustrate this solution using Apache HTTP logs as an example. Apache HTTP is a popular web server and it logs HTTP requests in Common Log Format.
Below is a sample log line in the Common Log Format.
127.0.0.1 - admin [30/Nov/2021:11:34:28 -0500] "GET /hello/server HTTP/1.1" 200 4592
The line above has value information which developers want to put into fields in OpenSearch documents. Pipeline authors use the grok prepper to extract the different parts of the log line into individual fields.
To extract these fields, a pipeline author can create a grok prepper with the following configuration.
- grok:
match:
log: [ "%{IPORHOST:clientip} %{USER:ident} %{USER:auth} \[%{HTTPDATE:timestamp}\] "(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})" %{NUMBER:response} (?:%{NUMBER:bytes}|-)" ]
The configuration above will add new fields to the OpenSearch document. The following table shows some of the fields that it adds from the example above.
| Document field name | Meaning | Document field value from the example log line above |
|---|---|---|
| clientip | The requestor IP address | 127.0.0.1 |
| auth | The username of the requestor | admin |
| timestamp | Timestamp of the request | 30/Nov/2021:11:34:28 -0500 |
| verb | HTTP method/verb | GET |
| request | The request path | /hello/server |
| httpversion | The version of HTTP used | HTTP/1.1 |
| response | HTTP status code in the response | 200 |
| bytes | The size in bytes of the response | 4592 |
The Apache Common Log format is a common format. Data Prepper actually has a shortcut pattern to perform the same extraction. A pipeline author can configure grok to extract data from Apache
- grok:
match:
log: [ "%{COMMONAPACHELOG}" ]
You can read the Log Analytics guide and try out a complete demo to start working with log ingestion today.
Compatibility with Logstash Configuration Files
Some teams are already using Logstash for log ingestion. Data Prepper 1.2.0 parses your existing Logstash configuration files and creates a similar pipeline. This new feature supports simple Logstash configurations. But, it is designed for extensibility. Expect to see expanded support for more complex Logstash configuration files in future versions. Data Prepper has a Logstash migration guide to help you start migrating.
Other Improvements
Data Prepper 1.2.0 has a few other notable improvements.
- Default Data Prepper configuration: Data Prepper has a default configuration file which you can use to get started quickly. It runs the core API with SSL using a demo certificate and secures the core API with a default username and password.
- Configurable Authentication: The existing OTel Trace Source plugin already accepts OpenTelemetry Protocol trace data. Now both the existing OTel Trace Source and the new HTTP source plugins support configurable authentication. You can configure a username and password for HTTP Basic authentication. Or you can create a plugin with custom authentication.
- Plugin Framework: The new plugin framework improves the plugin author’s experience through a more flexible approach to creating plugins. It is also preparing future expansions for more community-driven plugins.
- Proxy Support for OpenSearch: You can now connect Data Prepper to an OpenSearch cluster via a proxy when your network requires it.
- Log4j Fix: This release also uses Log4j 2.16.0 which fixes CVE-2021-44228 and CVE-2021-45046. It also disables JNDI as a security hardening against similar exploits.
Next Steps
With Data Prepper 1.2.0 out, the team is already working on Data Prepper 1.3.0. This release will focus on more ways to enrich log data. Current community needs drive the list of prioritized features.
What do you want to see in Data Prepper? You can impact the project roadmap in a few ways. First, comment on or up-vote issues in GitHub which you find valuable. Second, if you don’t see it on the roadmap, please create a Feature request. Finally, Data Prepper is open-source and open to contributions. You can develop the feature you are looking for. Express your interest in working an issue and a Data Prepper maintainer will be happy to help you get started.
